机器学习分类算法模型训练与测试工具
Posted 石油云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习分类算法模型训练与测试工具相关的知识,希望对你有一定的参考价值。
http://www.petroleumcloud.cn/pages/602.html
分类是根据已知训练样本,通过计算选择特征参数,建立判别函数以对样本进行分类,属于监督学习范畴。分类算法的核心就是按照某种标准给对象贴标签,再根据标签来区分归类。
《机器学习》(周志华)一书中,用选西瓜的问题做了很好的诠释。如下表所示,类别的标签是最后一列,对于选瓜这个问题,有两类,即是好瓜和不是好瓜两种情况。因此,对应有两个标签:“是”和“否”。在输入模型的时候可以把1作为“是”的标签,0作为“否”的标签。
第二列“色泽”一直到第七列“触感”,都是特征参数,表格中特征参数对应的特征值是判断好瓜和坏瓜的标准。每一行都是一个样本,通过一定数量的样本(训练样本)输入分类模型,可以训练得到具有预测好瓜坏瓜能力的分类模型。
在石油领域中,有类似的需要根据一组观测参数来预测分类的情况都可以用分类算法来处理,如利用钻、录、测数据预测漏、喷、塌、卡等钻井事故的问题。
常用的分类算法包括决策树、支持向量机、随机森林、Adaboost(集成学习)等,其中:
(1)决策树是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法;
(2)支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折中,以求获得最好的推广能力;
(3)随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定;
(4)Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
本模块提供了Adaboost、决策树、随机森林、支持向量机等分类算法。允许用户直接导入训练集(包含特征值与标签)与测试集,选择分类算法,一键点击“训练模型”,进行模型训练,输出准确率,可以导出保存训练好的模型,以后可以进行类别的预测。
模块操作界面如下图所示:
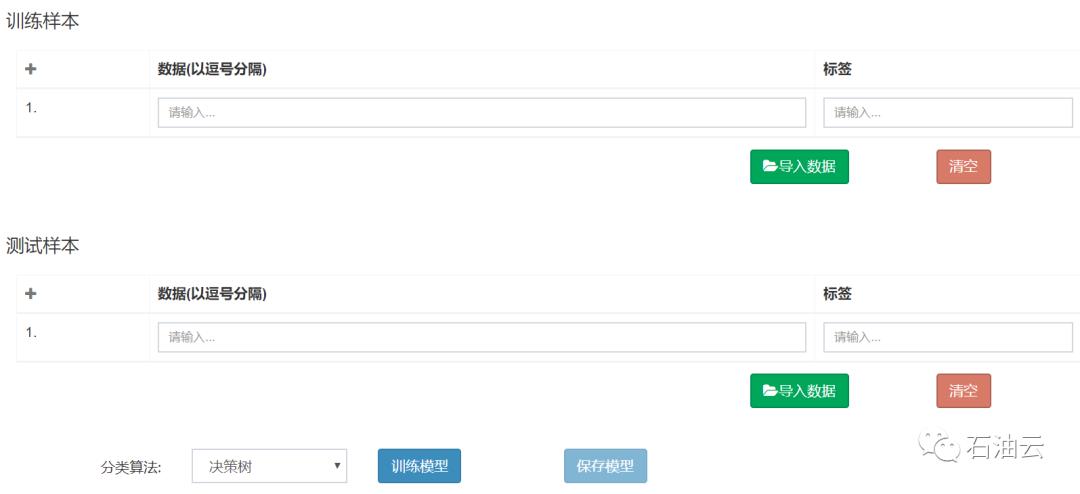
操作步骤如下:
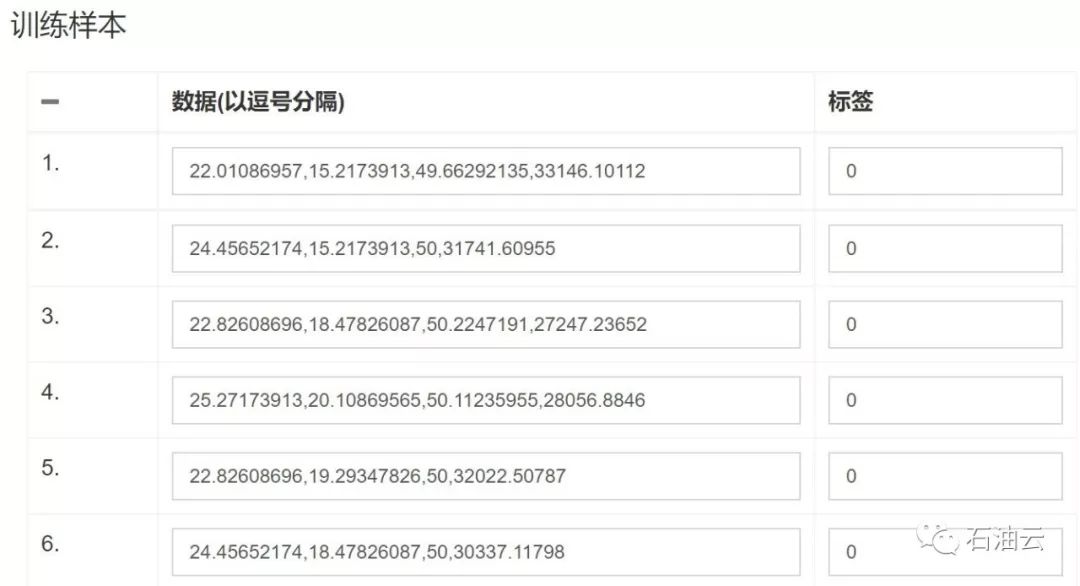
(1)导入训练数据
点击“导入数据”,将CSV格式(Excel文件另存为CSV逗号分隔)的数据导入,也可以通过手动输入的方式添加数据以及标签。导入的数据最后一列为特征值对应的标签,一般以整数数据代表不同的标签,其他每一列数据代表一个特征参数对应的特征值。导入数据的格式如下图所示:

训练样本导入前如下图所示:
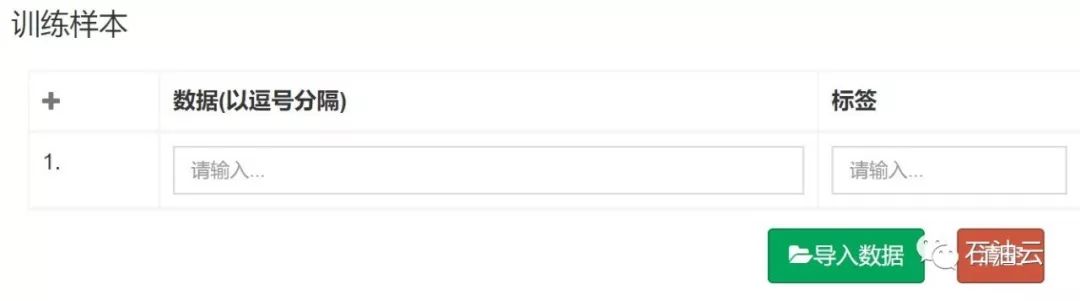
训练样本导入后如下图所示:
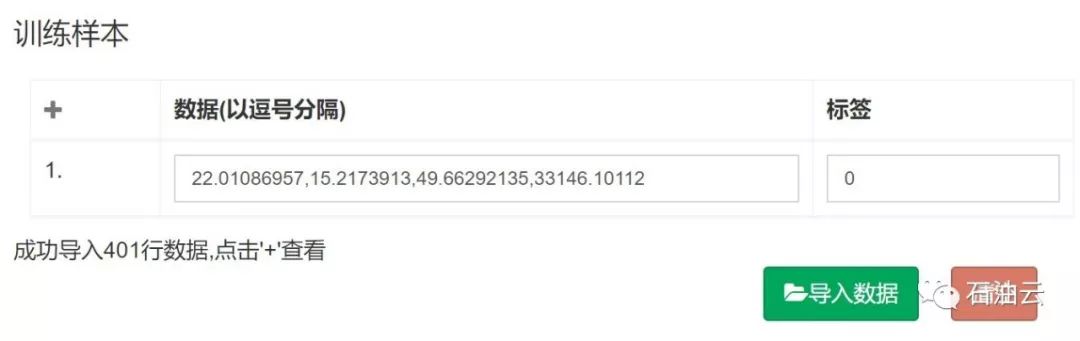
(2)导入测试样本
在训练样本处,点击“导入数据”,导入测试样本文件,用来检验所训练模型的准确率。
训练样本导入前如下图所示:
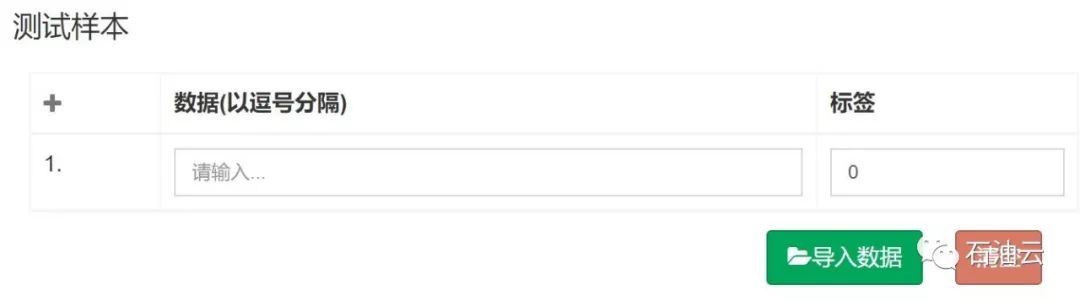
训练样本导入后如下图所示:
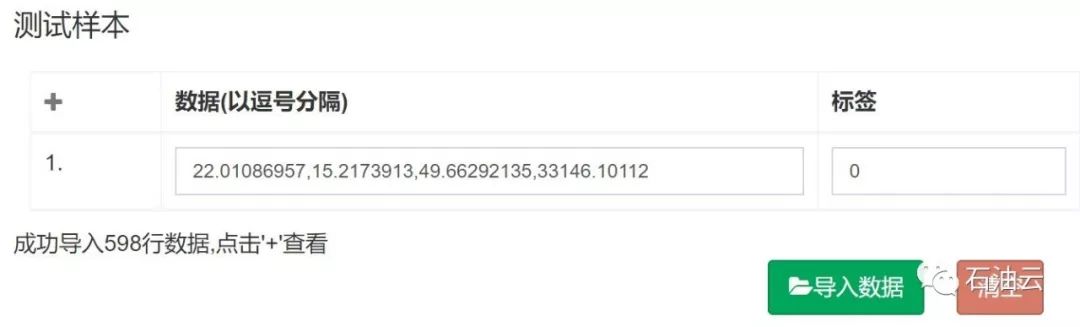 可以通过点击加号来查看导入的数据:
可以通过点击加号来查看导入的数据:
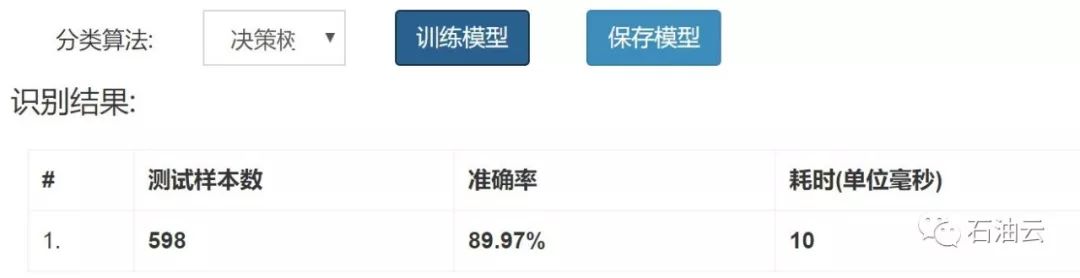
(3)选择分类算法并训练模型
从分类算法下拉中选择需要使用的算法,然后点击“训练模型”,即得到训练结果。

得到的模型预测结果将显示在下方:
(4)保存模型
点击保存模型,将训练好的模型保存好,未来进行分类预测。训练好的分类模型可以登录如下网址加载与应用:
http://www.petroleumcloud.cn/pages/603.html
交易担保 搜导师 搜导师 Mini Program
点击“阅读原文”访问www.petroleumcloud.cn
以上是关于机器学习分类算法模型训练与测试工具的主要内容,如果未能解决你的问题,请参考以下文章