通过两种推荐算法思路,给你推荐的电影竟然是...?
Posted 北斗大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过两种推荐算法思路,给你推荐的电影竟然是...?相关的知识,希望对你有一定的参考价值。
我们平时在浏览电商、视频、听歌等应用时,网页一般会有一个“猜你喜欢”,也就是智能,虽然一般来说推荐的不是很准确,但是小编还是研究了一下是怎么做出来的……今天说一说最简单的一个实现方法,叫做基于用户的协同过滤。
假设有几个人分别看了如下电影并且给电影有如下评分(5分最高,没看过的不评分),我们目的是要向A用户推荐一部电影:
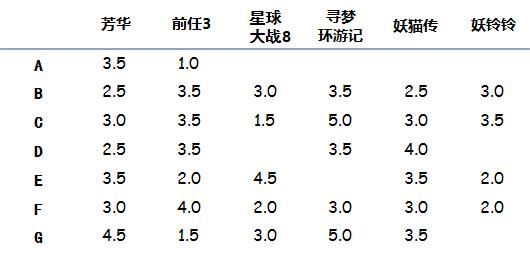
Score
协同过滤的整体思路只有两步,非常简单:寻找相似用户,推荐电影。
寻找相似用户####
所谓相似,其实是对于电影品味的相似,也就是说需要将A与其他几位用户做比较,判断是不是品味相似。有很多种方法可以用来判断相似性,(与我之前写的K-Means文章中判断两点是否类似的方法是一致的)这篇文章用“欧几里德距离”来做相似性判定。
我们把每一部电影看成N维空间中的一个维度,这样每个用户对于电影的评分相当于维度的坐标,那么每一个用户的所有评分,相当于就把用户固定在这个N维空间的一个点上,然后利用欧几里德距离计算N维空间两点的距离:每一个电影的评分求差值,然后求每个差值的平方,然后求平方的和,然后在开平方。距离越短说明品味越接近。
本例中A只看过两部电影(《芳华》和《前任3》),因此只能通过这两部电影来判断品味了,那么计算A和其他几位的距离:
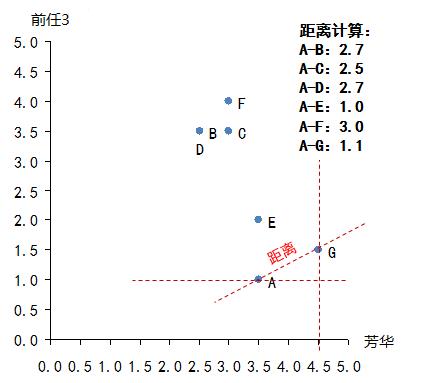
distance
然后我们做一个变换,变换方法为:相似性=1/(1+欧几里德距离),这个相似性会落在【0,1】区间内,1表示完全品味一样,0表示完全品味不一样。这时我们就可以找到哪些人的品味和A最为接近了,计算后如下:
相似性:B-0.27,C-0.28,D-0.27,E-0.50,F-0.25,G-0.47
可见,E的口味与A最为接近,其次是G。
推荐电影
要做电影加权评分推荐。意思是说,品味相近的人对于电影的评价对A选择电影来说更加重要,具体做法可以列一个表,计算加权分:
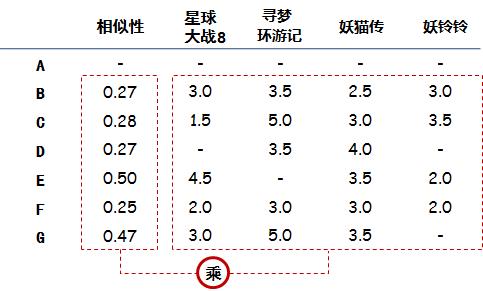
weighted
把相似性和对于每个电影的实际评分相乘,就是电影的加权分:
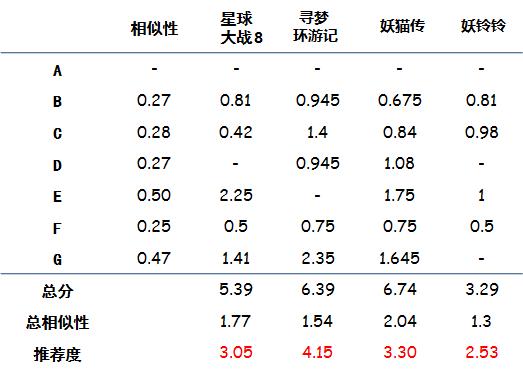
conclusion
加权后,还要做少量的计算:总分是每个电影加权分的总和,总相似度是对这个电影有评分的人的相似性综合,推荐度是总分/总相似性,目的是排除看电影人数对于总分的影响
结论在最终一行,就是电影的推荐度(因为是根据品味相同的人打分加权算出的分,可以近似认为如果A看了这部电影,预期的评分会是多少)。
有了电影的加权得分,通常做法还要设定一个阈值,如果超过了阈值再给用户推荐,要不怎么推荐都是烂片,如果这里我们设置阈值为4,那么最终推荐给A的电影就是《寻梦环游记》。
我们现在的做法是向用户推荐电影。当然还可以从另外角度来思考:如果我们把一开始的评分表的行列调换,其他过程都不变,那么就变成了把电影推荐给合适的受众。因此,要根据不同场景选择不同的思考维度。

还有一类智能推荐算法,是“基于物品的协同过滤”。消费者每天都在买买买,行为变化很快,但是物品每天虽然也有变化,但是和物品总量相比变化还是少很多。这样,就可以预先计算物品之间的相似程度,然后再利用顾客实际购买的情况找出相似的物品做推荐。
由于物品整体变化不大,所以这个相似程度不用每天都算,节省计算资源;同时,可以只给某一样商品只备选5个相似商品,推荐时只做这5个相似物品的加权评分,避免对所有商品都进行加权评分,以避免大量计算。
还是用上面的例子,目的是给A推荐一部电影
Score
首先是计算电影之间的相似度,方法还是有很多,这次用Pearson相关系数来做,公式为:
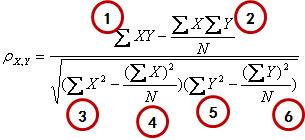
pearson.png
公式看起来复杂,其实可以分成6个部分分别计算就好了,我们选《寻梦环游记》(X)和《妖铃铃》(Y)作为例子,来算一下相似度,则
X=(3.5,5.0,3.0)
Y=(3.0,3.5,2.0)
数字就是评分,因为只有三个人同时看了这两个电影,所以X,Y两个向量都只有三个元素。按照公式逐步计算:
1.x和y的乘积再求和:3.5×3.0+5.0×3.5+3.0×2.0=34
2.x求和乘以y求和,再除以个数:((3.5+5.0+3.0)×(3.0+3.5+2.0))/3=32.58
3.x的平方和:3.52+5.02+3.0^2=46.25
4.x和的平方除以个数:((3.5+5.0+3.0)^2))/3=44.08
5.y的平方和:3.02+3.52+2.0^2=25.25
6.y和的平方除以个数:((3.0+3.5+2.0)^2))/3=24.08
最终把这几块的结果带入到整体的公式中:得出相关系数为0.89。
按照这种方法,需要两两计算电影的相似性,最终结果如下表:
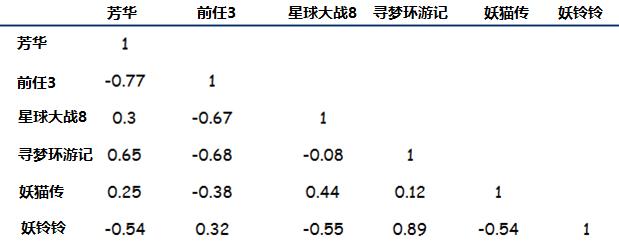
相似性
相关系数取值为【-1,1】,1表示完全相似,0表示没关系,-1表示完全相反。结合到电影偏好上,如果相关系数为负数,比如《芳华》和《前任3》,意思是说,喜欢《芳华》的人,存在厌恶《前任3》的倾向。
然后就可以为A推荐电影了,思路是:A只看过两个电影,然后看根据其他电影与这两个电影的相似程度,进行加权评分,得出应该推荐给A的电影,具体方法可以列一个表:
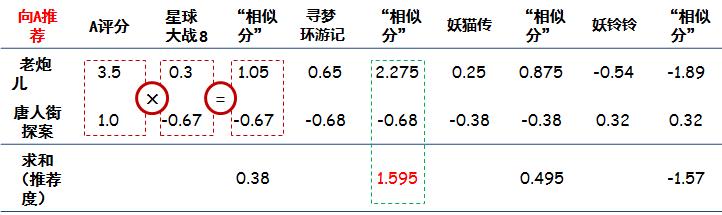
final
用A看过的电影的评分,和其他电影的相似度相乘(红框),然后再把相乘后的结果加和(绿框),得出最后的推荐度。这里可以看到,应该向A推荐《寻梦环游记》,和上一篇文章用基于用户的协同过滤算法结果是一致的。
#总结#
推荐算法的几个基本思想:
根据和你共同喜好的人来给你推荐(基于用户的)
根据你喜欢的物品找出和它相似的来给你推荐(基于物品的)
根据你给出的关键字来给你推荐(退化成搜索算法)
根据上面的几种条件组合起来给你推荐
经过多年的发展,思想还是这些思想,变化的地方在于计算相似度的衡量标准上,进而衍生出了各种计算相似度的算法,各种算法的优劣体现在相似度判定的准确度以及算法的计算速度和占用的计算资源:
欧氏距离算法
余弦距离算法
Jaccard距离算法
皮尔逊距离算
...
【热门福利】
【推荐文章】
以上是关于通过两种推荐算法思路,给你推荐的电影竟然是...?的主要内容,如果未能解决你的问题,请参考以下文章