小谈基于协同过滤的产品推荐算法
Posted KPMG大数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小谈基于协同过滤的产品推荐算法相关的知识,希望对你有一定的参考价值。
协同过滤算法又可以主要分为基于用户的和基于产品的两种算法,我们会分别加以介绍。
1. 问题描述
目前很多点评网站或者电商平台都允许用户有对产品进行评分,评分一般是五分制或者十分制,经过一段时间的数据积累,大量的用户ID会积累一定数量的评分数据,可以得到类似于下面的评分数据表:
上表的每一行表示一个用户,每一列代表一种产品,为了叙述方便,我们用cij表示用户i对产品j的评分。当然,实际项目中的用户数和产品数远远大于上表,数据的稀疏程度也有所差异。该表格是基于5分制的打分规则产生的,然而不是每个用户都对所有产品进行了评分因此,我们将有评分信息的表格都加上了底色。需要根据已有的评分对每个用户产生推荐产品,比如用户U7,没有购买过产品2、4、5、6、8(为了方便起见,这里假设没有评分就表示该用户没有购买过该产品),我们需要估计出该用户对这5种产品的评分,并根据估计的评分结果推荐产品。
另外一种情况,我们以商业银行为例,很多客户购买了银行不同类型、不同数量的理财产品,往往也需要建立客户的产品推荐模型,进行精准营销。但是这种情况得到的数据结构和上表有所不同,我们只知道每个客户是否购买过每种产品,不能得到客户对该种产品的评分,最后得到的是二分类的数据表,尽管所能提供的数据信息要少得多,但是推荐模型的建模思路基本是一样的。
协同过滤算法的实际上是基于相似性规则进行推荐的,基于用户的协同过滤就是将对与被推荐用户(即所谓的“Active user”)相似程度高的其他用户青睐的产品进行推荐,而基于产品的协同过滤算法则是在active user没有购买的产品列表中,找出与已购买产品相似程度高的产品对其进行推荐。因此,我们首先要介绍常用的衡量产品或者用户相似程度的的指标。
2. 相似性衡量
常用的相似性衡量指标有三个,分别是Pearson相关系数、Cosine相关系数和Jaccard指数。我们可以将两个用户(或产品)的评分向量表示为u1=(c11, c12, ......, c1k)和u2=(c21, c22, ......, c2k),这里的k表示这两个用户在k个产品上都进行了评分。相信大家对Pearson相关系数都是很熟悉的,这里不再赘述;Cosine相关系数其实就是夹角余弦:
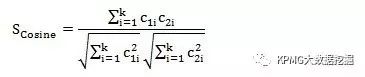
Cosine相关系数是以u1和u2两个向量的夹角来表示他们的相似程度,夹角越小,Cosine相关系数也就越大。Jaccard指数是针对二分类的数据表计算相似度的,比如用户u1购买了A种产品,u2购买了B种产品,两个用户总共购买了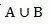 种产品,这其中有
种产品,这其中有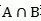 种产品是双方都购买了的,Jaccard指数表示为:
种产品是双方都购买了的,Jaccard指数表示为:
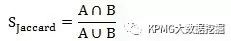
显然,在确定的情况下,购买相同产品的种类越多,两人的相似度也就越高。基于用户或者产品的协同过滤算法基本都是利用上述三个指标来计算相似度,并进行产品推荐的,但是具体的做法有一些区别,下面分别介绍。
3. 基于用户的协同过滤算法
将所有用户按照与与Active user的相似系数大小从高到低进行排序,可以取前*个,也可以取相关系数大于某个临界值的所有用户构成Active user的高相似用户集合,记为N(a),| N(a)|表示集合中的用户个数。根据N(a)中用户的评分信息,估计出Active user对未评分产品j的评分,估计公式为:
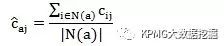
由于N(a)中的用户与Active user的相似性也有高低之别,不妨假设sai表示Active user与用户i之间的相似系数,也可以结合该相似系数计算出加权的评分估计值:
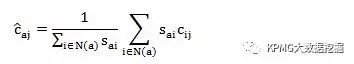
接下来就可以将估分最高的前*个产品推荐给Active user啦。
4. 基于产品的协同过滤算法
基于产品的协同过滤算法首先需要计算出所有产品之间的两两相似度,如果产品个数为n,可以将产品之间的相似系数保存在n*n的矩阵中,为了节约储存空间和减少接下来的计算量,也可以只保留排在前k的相似系数。sij表示产品i和j之间的相似度,C(i)表示与产品i相似程度最高的前k个产品的集合,C(a)表示Active user所有已评分产品的集合,如果产品i是需要估计评分的产品,那么:
最后再将估分最高的前*个产品推荐给Active user,就完成了这个算法的应用过程。
5. 小结
这两种推荐算法都采用了相同的相似度衡量方法,但是一般情况下,基于用户的协同过滤算法会涉及较大的计算量问题,因为用户的数量一般会远远大于产品的数量,这样产生的用户相似度矩阵也会很大,所以往往会利用反查的手段来减少计算量,将那些与Active user没有相同点评产品的用户先予以排除。
另外,在数据处理阶段,往往还会对每个用户的评分数据进行归一化处理,比如将每个用户的评分数据减去该用户所有产品评分的平均值,因为有些用户的评分总是偏高或者偏低,这样做就可以在一定程度上消除个人评分倾向性带来的偏差。
长按二维码即可关注!也请随手推荐我们给你的小伙伴 ↓↓↓↓
以上是关于小谈基于协同过滤的产品推荐算法的主要内容,如果未能解决你的问题,请参考以下文章