推荐算法整理
Posted 往远看928
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐算法整理相关的知识,希望对你有一定的参考价值。
写给自己的
岁月,愿你在平安喜乐中度过
文/wendy
四月的北京,与众不同,来了场雪。
最近因公司产品在构想推荐机制,周末对推荐算法进行了系统归纳整理,内化以便有所启发。
人们获取信息的方式
现在我们问别人问题的时候,态度好一点的会耐心解答,没空的也会丢一句:问“度娘”,他们都是乐于助人的人,至少给了解决问题的思路。
提到的“问度娘”,其实是一种带有明确目标/需求借助互联网主动获取信息的方式——搜索(在搜索引擎提供的结果里,可以借助浏览和点击来明确判断是否满足了用户基本需求);另一种获取信息的方式是“推荐”,与搜索不同的是它是被动且模糊的。
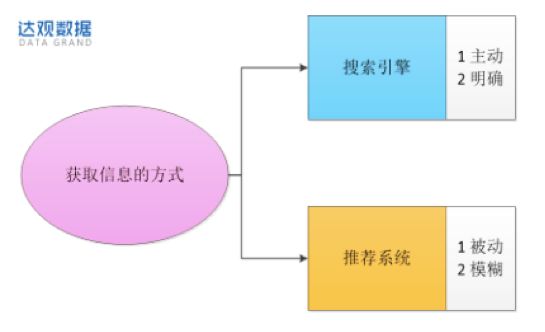
网络有句话:“搜索是在已知条件下进行的,强调结果;推荐是对未知的探寻,强调过程。”
推荐的本质
其实推荐和搜索本质有相似的地方,都是为了在这个信息过载的时代,帮助用户找到自己感兴趣的东西。
(以目录纲要的形式展现,便于读者直观了解内容全局)
目录——
一、协同过滤推荐算法(UserCF和ItemCF)
二、基于内容的推荐算法
三、混合推荐算法
四、流行度推荐算法
五、基于标签的推荐
补充1:个性化推荐存在的问题
1.冷启动问题
2.数据稀疏性问题
3.推荐的精确度和准确度问题
4.传统的个性化推荐,无法保证推荐的实时性
5.精确度与多样性的平衡问题
6.垃圾数据处理
补充2:更丰富的推荐维度
1.按照用户细分
1)用户消费能力
2)用户分层(身份标签)
2.按照内容组织形式
1)直接推店铺或者优惠(点评猜你喜欢)
2)通过UGC短评来推荐(某宝的有好货)
3)以及现在很流行的PGC文章来推荐(小红书等)
目前的推荐算法一般分为几大类:
一、协同过滤推荐算法
协同过滤推荐算法应该算是一种用的最多的推荐算法,它是通过用户的历史数据来构建“用户相似矩阵”和“产品相似矩阵”来对用户进行相关item的推荐,以达到精准满足用户喜好的目的。
最基本的协同过滤分为两种,UserCF和ItemCF。
1)基于内容的协同过滤(item-based CF),用户对不同内容的评分来评测内容之间的相似性,基于内容之间的相似性做出推荐;
最典型的例子:著名的“啤酒加尿布”,就是通过分析知道啤酒和尿布经常被美国爸爸们一起购买,于是在尿布边上推荐啤酒,增加了啤酒销量。
2)基于用户的协同过滤(user-based CF),通过用户对不同内容的行为,来评测用户之间的相似性,基于用户之间的相似性做出推荐。
这部分推荐本质上是给相似的用户推荐其他用户喜欢的内容,一句话概括就是:和你类似的人还喜欢下列内容。
ItemCF:找到跟TA喜好最相似的商品,然后推给TA。
UesrCF:找到跟TA喜好最相似的其他用户,然后把这些用户喜欢的商品推给TA。
补充:该部分会运用遇余弦公式(大学里学过的cos,看例子其实不难,只需要理解用来干什么即可)
余弦公式,本身应用范围很广,量化相似度在搜索推荐,商业策略中都是常见问题,余弦公式是很好的解决方案。就推荐本身而言,计算内容的相似度,计算用户的相似度,计算用户类型的相似度,计算内容类型的相似度,这些都是可以应用的场景。
A和B用户对五种物品的喜爱程度(以数字衡量,0-5分)




只需要记住:协同过滤推荐算法含基于用户和内容两种协同过滤,通过评估用户行为和内容相似度进行推荐,算法会运用余弦公式,得出的结果越小越相似。
例子:「网易云音乐」是典型的个性化推荐的音乐产品
根据用户对音乐的行为来建立一个喜爱程度模型,例如:收藏-5分,加入歌单-4分,单曲循环-3分,分享-5分,听一遍就删-0分
根据余弦公式便可算出用户的相似度,然后进行相似用户的歌曲推荐。
二、基于内容的推荐算法
Content-Based是一个将Item先降维,再compare,在通过KNN或者一些其他算法推荐(了解大致情况即可)。
细化来说,是将item的名称、简介等进行分词处理后,提取出TF-IDF值较大的词作为特征词,在此基础上构建item相关的特征向量,再根据余弦相似度来计算相关性,构建相似度矩阵。
简单来说,基于内容的推荐不需要太多的惯性数据,因此可以部分解决冷启动问题和流行性偏差问题,弥补了协同过滤算法中的部分不足,因此也可以将两者混合起来使用,例如混合推荐算法就是采用了这样的方式;
其次,需要注意的是,如果单纯使用基于内容的过滤算法,会出现过度专业化问题,导致推荐列表里面出现的大多都是同一类东西。就比如浏览新闻时随手点了一则娱乐头条,接下来会发现推荐的资讯全是娱乐相关,就是因为出现了过度专业化的现象。
应用:初级步骤是通过分词技术对标题和简介等进行处理,形成特征标签。例如,对于图书和电影而言,可以对名称和简介进行特征词提取,从而构建特征向量
三、混合推荐算法
混合推荐算法很好理解,就是将其他算法推荐的结果赋予不同的权重,然后将最后的综合结果进行推荐的方法。
举例来说,比如上述已经提到了三种方式,协同过滤算法中的基于用户和基于item的协同过滤推荐,和基于内容的推荐算法;而混合推荐算法中是将这三种推荐结果赋予不同的权重,如:基于用户的协同过滤的权重为40%,基于item的协同过滤的权重为30%,基于内容的过滤技术的权重为30%,然后综合计算得到最终的推荐结果。
四、流行度推荐算法
这种方法是对item使用某种形式的流行度度量,例如最多的下载次数或购买量,然后向新用户推荐这些受欢迎的item。就和我们平时经常看到的热门商品、热门推荐类似。
五、基于标签的推荐
标签系统相对于之前的用户维度和产品维度推荐,从结构上讲,其实更易于理解一些,也更容易直接干预结果一些。关于tag和分类,基本上是互联网有信息架构以来就有的经典设计结构。
内容有标签,用户也会因为用户行为被打上标签,通过标签去关联内容。
标签查找的方法这里有很大可以发挥的空间,比如,通过知识库进行处理,或者语义分析处理。而对于一些设计之初就有标签概念的网站,就比较容易。
例子:比如豆瓣和知乎。对于知乎而言,公共编辑的标签是天然的标签内容,对于知乎的用户而言,浏览回答关注等行为则是天然的用户标签素材。
在个性化的推荐过程中,会存在几种问题,比如:冷启动问题、数据稀疏性问题、推荐的精确度和准确度等问题。
1.冷启动问题
如果用户的标签信息为零,那么个性化推荐就等于不存在。这个情况下,往往是让用户进入兴趣标签填写的页面,或者通过搜集用户在其它平台的标签数据来进行推荐。近期做的项目,我们可以获取并明确用户的基本属性,所以针对此可进行标签推荐。
2.数据稀疏性问题
很多电商平台的信息数据之大,使得任意两个用户浏览的商品交集非常小,这时候通常采用商品聚类或者用户聚类的方式。
3.推荐的精确度和准确度问题
通过收集更多的用户标签,不断优化推荐算法,多种推荐算法的组合推荐来最大化保证推荐的精确度和准确度。
4.传统的个性化推荐,无法保证推荐的实时性
5.精确度与多样性的平衡问题
盲目的精确推荐可能会使用户的视野越来越狭窄,也就无法向用户推荐其它多样的物品和信息,如何平衡两者的关系是需要解决的问题。
6.垃圾数据处理
对于系统产生的异常数据、垃圾数据需要业务特点制定一套清洗规则。
……
电商领域,呈现出更丰富的推荐维度
1.按照用户细分
1)用户消费能力,比如中高客单价的用户群和低端客单价的用户群;
2)用户分层,比如学生党、辣妈、有车一族等,通过身份标签来获得认同,同时可以满足较长尾的用户需求。
2.按照内容组织形式
1)直接推店铺或者优惠(点评猜你喜欢);
2)通过UGC短评来推荐(某宝的有好货);
3)以及现在很流行的PGC文章来推荐(小红书等)。
其中PGC一般较为专业,定位于中高端人群更合适。
还有O2O模式,同时需要对场景进行考量。
以上便是常见的算法总结,供参考。
出奇的冷,依然愿你温暖开心。
往远看928
愿你在平安喜乐中度过
以上是关于推荐算法整理的主要内容,如果未能解决你的问题,请参考以下文章