干货|3分钟让你了解个性化推荐算法
Posted 大数据DT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货|3分钟让你了解个性化推荐算法相关的知识,希望对你有一定的参考价值。
如果去商场里买东西,我并不愿意听导购小姐讲的话,但是电商网站上的推荐,我还真的愿意看一看。【猜你喜欢】,好,那你就猜猜吧。
推荐这种体验除了电商网站,还有新闻推荐、电台音乐推荐、搜索相关内容及广告推荐,基于数据的个性化推荐也越来越普遍了。今天就针对场景来说说这些不同的个性化推荐算法吧。
说个性化之前,先提一下非个性化。 非个性化的推荐也是很常见的,毕竟人嘛都有从众心理,总想知道大家都在看什么。非个性化推荐的方式主要就是以比较单一的维度加上半衰期去看全局排名,比如,30天内点击排名,一周热门排名。
但是只靠非个性化推荐有个弊端,就是马太效应,点的人越多的,经过推荐点得人有更多。。。强者越强,弱者机会越少就越弱,可能导致两级分化严重,一些比较优质素材就被埋没了。
所以,为了解决一部分马太效应的问题,也主要是顺应数据化和自动化的模式,就需要增加个性化的推荐(可算说到正题了。。。)个性化的优点是不仅体验好,而且也大大增加了效率,让你更快找到你感兴趣的东西。YouTube也曾做过实验测试个性化和非个性化的效果,最终结果显示个性化推荐的点击率是同期热门视频的两倍。

一般来说,如果是推荐资讯类的都会采用基于内容的推荐,甚至早期的邮件过滤也采用这种方式。
基于内容的推荐方法就是根据用户过去的行为记录来向用户推荐相似额推荐品。简单来说就是你常常浏览科技新闻,那就更多的给你推荐科技类的新闻。
复杂来说,根据行为设计权重,根据不同维度属性区分推荐品都是麻烦的事,常用的判断用户可能会喜欢推荐品程度的余弦向量公式长这样,我就不解释了(已经勾起了我关于高数不好的回忆)。。。
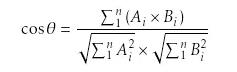
但是,这种算法缺点是由于内容高度匹配,导致推荐结果的惊喜度较差,而且有冷启动的问题,对新用户不能提供可靠的推荐结果。并且,只有维度增加才能增加推荐的精度,但是维度一旦增加计算量也成指数型增长。如果是非实体的推荐品,定义风格也不是一件容易的事,同一个作者的文风和曲风也会发生改变。

说电商推荐那不可能不讲到亚马逊,传言亚马逊有三成的销售额都来自个性化的商品推荐系统。实际上,我自己也常常在这里找到喜欢的书,也愿意主动的去看他到底给我推荐了什么。
一般电商主流推荐算法是基于一个这样的假设,“跟你喜好相似的人喜欢的东西你也很有可能喜欢。”即协同过滤过滤算法。主要的任务就是找出和你品味最相近的用户,从而根据最近他的喜好预测你也可能喜欢什么。
这种方法可以推荐一些内容上差异较大但是又是用户感兴趣的物品,很好的支持用户发现潜在的兴趣偏好。也不需要领域知识,并且随着时间推移性能提高。但是也存在无法向新用户推荐的问题,系统刚刚开始时推荐质可能较量差。
电商行业也常常会使用到基于关联规则的推荐。即以关联规则为基础,把已购商品作为规则头,规则体为推荐对象。比如,你购买了羽毛球拍,那我相应的会向你推荐羽毛球周边用品。关联规则挖掘可以发现不同商品在销售过程中的相关性,在零售业中已经得到了成功的应用。
自从可以浏览器读取cookies,甚至获得年龄属性等信息,广告的个性化投放就也可以根据不同场景使用了。
当用户的行为数据较少时,基于知识的推荐可以帮助我们解决这类问题。用户必须指定需求,然后系统设法给出解决方式。假设,你的广告需要指定某地区某年龄段的投放,系统就根据这条规则进行计算。基于知识的推荐在某种程度是可以看成是一种推理技术。这种方法不需要用户行为数据就能推荐,所以不存在冷启动问题。推荐结果主要依赖两种形式,基于约束推荐和基于实例推荐。

由于各种推荐方法都有优缺点,所以在实际中,并不像上文讲的那样采用单一的方法进行建模和推荐(我真的只是为了解释清楚算法)。。。
在组合方式上,也有多种思路:加权、变换、混合、特征组合、层叠、特征扩充、元级别。
并且,为了解决冷启动的问题,还会相应的增加补足策略,比如根据用户模型的数据,结合挖掘的各种榜单进行补足,如全局热门、分类热门等。
还有一些开放性的问题,比如,需不需要帮助用户有品味的提升,引导人去更好的生活。
最后,我总想,最好的推荐效果是像一个了解你的朋友一样跟你推荐,因为他知道你喜欢什么,最近对什么感兴趣,也总能发现一些有趣的新东西。这让我想到有一些朋友总会兴致勃勃的过来说,嘿,给你推荐个东西,你肯定喜欢,光是听到这句话我好像就开心起来,也许这就是我喜欢这个功能的原因。

我们将为大家提供与大数据相关的最新技术和资讯。
以上是关于干货|3分钟让你了解个性化推荐算法的主要内容,如果未能解决你的问题,请参考以下文章