练手案例:能为销量强助力的一套简易推荐算法
Posted 小象
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了练手案例:能为销量强助力的一套简易推荐算法相关的知识,希望对你有一定的参考价值。
我 相 信 这 么 优秀 的 你
已 经 置 顶 了 我
翻译|朱敏 选文|小象
转载请联系后台
作者简介
Chris Clark
Grove Collaborative的创始人。Grove Collaborative是一家通过了认证的B公司,将用户能负担得起的神奇而有效的天然产品运送到用户门口。
◇◆◇◆◇
背景
顾客说我们网站Grove.co的产品推荐系统很无趣。于是我们进行了调查,发现顾客最想要的是更好的产品搜索体验。从分析数据中发现,顾客们在推荐中一页接一页的往下点,试图找到可以购买的新产品。毫无疑问,在呈现我们产品目录的后半段这方面,我们做得并不好。
我们在呈现目录的另一半工作上并没做好
增加长尾商品曝光的一个通用方法就是简单的对搜索结果进行随机抖动。但是随机性的注入带来了两个问题:第一,目录深处的产品要冒泡出来,需要经历很多次随机。二,它破坏了推荐系统的框架,从而失去了客户的信任。
“框架”是什么意思呢?让我们看看一个来自雅虎的著名的例子。
◇◆◇◆◇
小甜甜效应
假设你正在浏览关于周末即将来临的美国全球橄榄球联盟比赛的文章,文章下面列出了一堆算法算出来的推荐文章。在2000年早期,好像每个人都希望阅读到有关小甜甜的报导,不管人们承认与否。
于是,当你浏览到这篇文章的底部,会看到“你可能也喜欢:”这几个字,紧随其后的是一篇关于小甜甜布兰妮和凯文·费德林的文章。你会有点被这个算法冒犯了的感觉,雅虎竟然认为我想要看有关小甜甜的消息??

其他搜索本词的人也看了…
但是如果显示“看了这篇文章的其他人也看了:”,…嗯哼…好吧,我会点击。这样的设计征求了我的许可,这个很重要!
就像一个好的接球手会为裁判设计一个擦边的棒球投掷,网站上的产品推荐有合适的上下文将会给客户们带来好的情绪,从而引导他们去购买或者点击。
“为你推荐”—呃。网站认为它了解我,嗯?
用下面这个代替试试:
“跟你一样的家庭经常买”
这样我就有了上下文,而且明白了。在我面前的不是一个推销产品的零售商,而是一个有用的商品集合,像我一样的客户也发现了它会带来帮助。满满的社会证据!
◇◆◇◆◇
貌似可信的意外发现
和我们的投资人之一,来自Bullpen Capital的Paul Martino,进行了一场令人兴奋的头脑风暴会议后,我们有了要实现一个潮流商品算法的想法。我们提取每天的所有“加入购物车”行为,从而找到趋势向上的商品。当然,有时这只会反映出我们市场部的活动(例如,通过邮件来推广一个产品会让这个产品变成潮品),但是通过适当的标准化,它也会突出时新的、趋势用到的搜索条目、以及由于一些意外的原因而受欢迎的商品。同时,它让移动缓慢的商品更容易突然获得人气,从而让一些长尾商品进入客户的视线。
◇◆◇◆◇
潮流产品引擎的实现
首先,我们要先获取“加入购物车”的数据。从我们的数据库中获取这个数据相对来说比较简单;只需要跟踪每个购物车-产品(我们称它为订购物品)的创建时间,使用SQL就能提取出来数据。取出最近20天的购物车数据,我们可以发现一些趋势(尽管只需要几天的数据就可以推断出哪些是趋势):
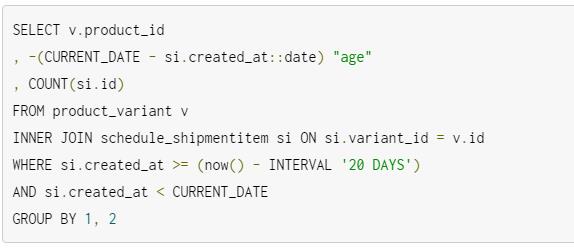
我对上面的代码做了一些简化(产品版本在活跃产品、付费顾客、上产品的环境等会有些微妙),结果数据特别简单:

每一行代表了过去20天内,在特定的日期,特定商品被加入购物车的数量。’age’的取值范围是-20(20天以前)到-1(昨天),所以当这些数据被视图化后,可以直观的从左读到右,即从过去到现在。
从这个链接(http://blog.untrod.com/files/sample-cart-add-data.csv)可以查看我们数据库中100种随机商品的数据样本。样本中,商品的ID和购物车都采用了匿名的方式,标准化后,结果绝对真实,但是个别数据点并不代表我们的实际商业。
◇◆◇◆◇
基本方法
在我们深究代码之前,先把数据视图化来概述基本的方法。每个中间步骤的代码及视图化,将会在稍后解释。
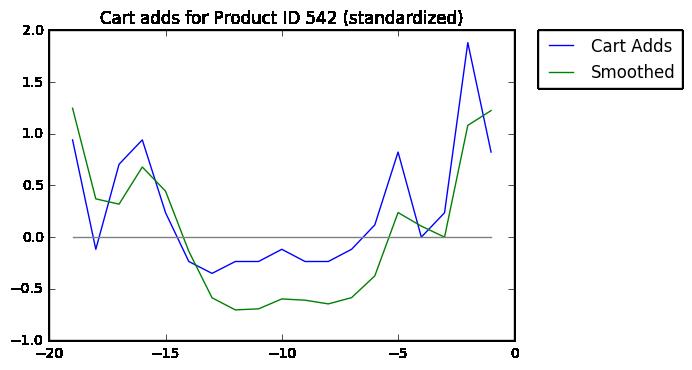
下图是样本数据中ID为542的商品的“加入购物车”曲线:
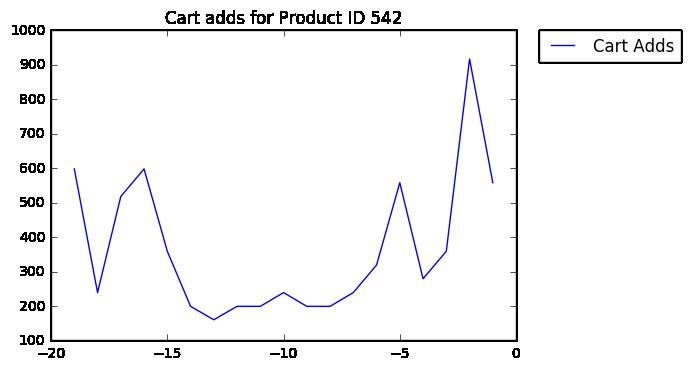
首先,使用低通过滤器(圆滑函数)来减少日均波动。
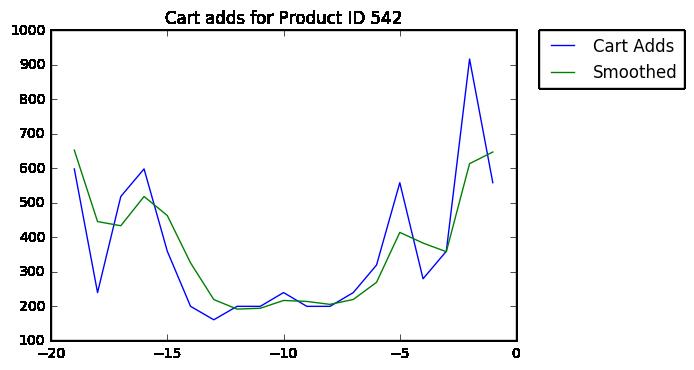
然后让Y轴标准化,这样受欢迎的商品能和不怎么受欢迎的商品进行比较。注意Y轴值的变化。
最后,计算被光滑后的趋势线上每条线段的斜率。
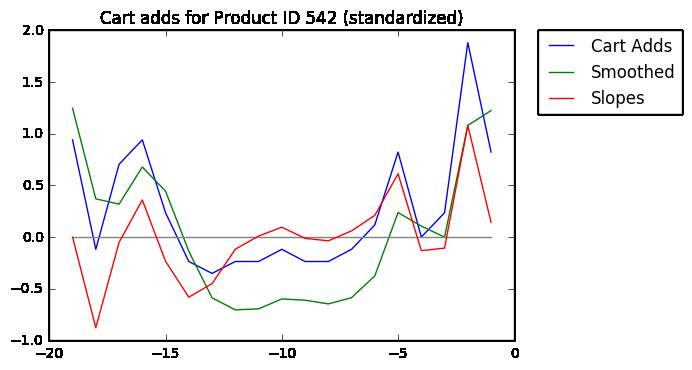
我们的算法会对数据库中的每个商品执行这些操作(当然是在内存中,不是可视化的),然后简单的返回过去的日子里斜率最大的商品,例如,上图中红线在t=-1时的最大值。
◇◆◇◆◇
代码
现在我们来看代码!你可以使用Python 2 Jupyter notebook或者Yhat’s Python IDE - 来运行本文中的代码。
下面是生成第一张图表(简单的视图化趋势)的代码。如同我们创建图表一样,我们通过运行这段代码来创建最后的算法。
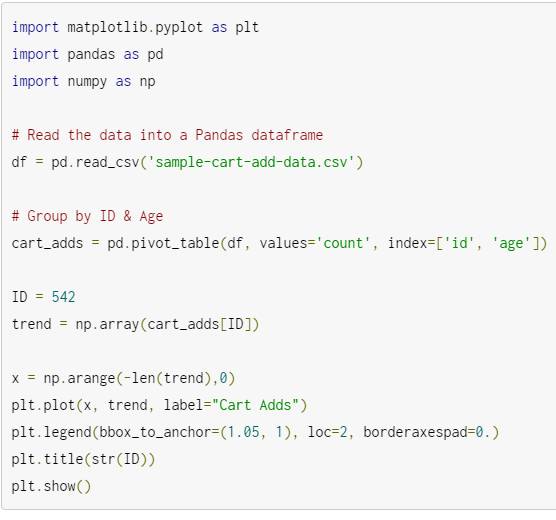
代码不能再简单了。使用pandas的pivot_table函数来为每个商品ID和’age’维度创建索引,这将为后面选择数据提供便利。
◇◆◇◆◇
Smoothing
定义一个圆滑函数(Smoothing Function),并将它应用到图表中:

这个函数需要说明一下。首先,它或多或少来自,但是被修改过,跟原来相比显得不那么奇怪。
smooth函数采用了一个权重的“窗口”,本例中的窗口由定义,并且在原始数据中移动这个窗口,根据窗口权重来加权邻近的数据点。
Numpy提供了一堆窗口(Hamming,Hanning,Blackman等),我们可以用命令行来查看各个窗口:
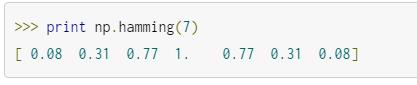
对整个数据集使用“窗口”来生成一个新的平滑后的数据集,这只是一个非常简单的低通过滤器。
代码的5-7行将原始数据中的前面部分数据和后面部分数据进行了反转和反射,这样窗口能保持“合适”,即使是在最边缘的数据点。这个看起来会显得奇怪,因为我们只关心最后的数据点,并据此来决定我们的潮流商品。你可能会觉得我们偏好于使用只检验历史数据的圆滑函数,其实是因为这个修改只反射接近边缘的尾部数据,所以并不会给结果带来净影响。
◇◆◇◆◇
标准化
我们需要将诸如平均每天10个被加入购物车的商品和平均每天百个或千个的商品进行比较。为了解决这个问题,我们使用四分间距(IQR)的方法来对数据进行标准化:

同时减去中位数,这样数据序列会以0为中心,而不是以1为中心。请注意,这是标准化,而不是正规化。这两者的区别在于正规化将序列的值严格限定在一个已知的区域内(通常是0和1),而标准化只是将它们放在同一个等级上。
对数据进行标准化处理的方法有很多,上文中所讲叙的方法是非常健壮和易实现的。
◇◆◇◆◇
斜率
非常简单!要找到光滑后、标准化后的序列上每个点的斜率,只需要拷贝一份序列,向后移一位,并相减。如下图:
代码如下:
哇!就这么简单。
◇◆◇◆◇
综合所有
现在我们只需要对每个商品重复所有的步骤,然后找到在最近的时间步内拥有最大斜率值的商品。
最终的实现如下:

结果如下:
这就是这个算法的核心。如今这个算法已投入使用,和我们已有的算法相比,它表现不错。我们还有一些额外的正在实施的模块,计划未来能够提升性能:
1. 将很多不受欢迎产品的结果丢弃掉。否则,在每天被加入购物车的数量为1-5附近波动的商品突然在某天上升到10个以上,很轻易就出现在了结果列表中。
2. 需要给商品配置权重。否则很有可能,一个从平均500次/天跳到600次/天的商品的趋势会紧挨着一个从20跳到40的商品。
关于趋势算法的资料如此少,很让人诧异 – 也很有可能其他人有更复杂的,能生成更好结果的技术。
但是对Grove来说,这个就足够了:可解释的;偶然发现的;同时与我们从顾客那收集的其它产品反馈相比,获得了更多的点击。

译者介绍
朱敏
以上是关于练手案例:能为销量强助力的一套简易推荐算法的主要内容,如果未能解决你的问题,请参考以下文章