情感分析与推荐算法专场(视频+实录+PPT)| AIS预讲会全程干货分享
Posted 读芯术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了情感分析与推荐算法专场(视频+实录+PPT)| AIS预讲会全程干货分享相关的知识,希望对你有一定的参考价值。
“AIS2018(ACL、IJCAI、SIGIR)论文预讲会” 全程干货
2018年6月9-10日,代表学术界和工业界的顶级交流盛会——由中国中文信息学会青年工作委员会和百度公司联合举办的【“AIS2018(ACL、IJCAI、SIGIR)论文预讲会”】在北京盛大举行。预讲会共包括10个专场,芯君将为大家带来全程的内容干货。后台回复AIS,可获得讲者公开PPT。
AIS (ACL、IJCAI、SIGIR) 2018
Session 1: Sentiment and Recommendation

“情感分析与推荐算法” 专场全程视频分享
以下分享内容根据讲者口头分享整理,具体内容详见论文。

1 王昊 中科院计算所
Exploiting POI-Specific Geographical Influence for POI Recommendation

随着移动互联网的发展,涌现了很多基于位置的社交网络(LBSNs),比如Foursquare、Gowalla等。在LBSNs中,用户可以签到兴趣点(POIs),分享访问的经历,并且可以发现更多值得探索的兴趣点。据统计,截止到2016年,Foursquare已经吸引了5千万的活跃用户,累计了80亿的用户签到行为。由于在LBSNs中,POI数量非常庞大,为了更好地帮助用户发现感兴趣的POIs,LBSNs通常会为用户提供POI推荐服务。

POI推荐和传统推荐有很多不同,比如,地理影响:用户的签到行为是对线下的POI进行访问,因此,会受到地理位置的影响,比如,人们通常不会走太远去进行活动。本文关注于通过探索地理影响,来提升POI推荐的效果。
现有方法,认为地理影响使得用户签到的POIs的经纬度会在地图上呈现集中,并使用某种分布,来建模这种集中现象。然而,在建模时,现有方法认为地理影响只和POI之间的距离相关,而忽略了不同的POI之间的地理影响存在着高度的差异性和非对称性。
我们希望建模POI之间个性化的地理影响,也就是说,每一对POIs都有特定的地理影响,这种影响不只和它们的距离有关,也和它们自身的特性有关。因此,首先,我们采用一个非线性函数来拟合地理影响和POI之间距离的关系;其次,为了刻画POI的特性,我们为每个POI引入了两个隐向量,分别表示POI的影响力和易感性,前者刻画POI引导用户访问其他 POIs的能力,后者表示POI接收其他POIs的用户来访问的可能性,二者的内积则表示POI之间的个性化影响因子。
2 马仁峰 复旦大学智能媒体计算实验室
Mention Recommendation for Multimodal Microblog with Cross-attention Memory Network

什么是mention任务?Mention Recommendation就类似于微博上用的“@”,提醒某一个人看某一篇推文,我的数据集是在推特这个社交平台上爬取的。
为什么用户会采取mention操作?比如我需要推荐出我自己的一个产品,我会艾特一下某个使用我的产品的名人,增加推广度;或者说我跟我的好友进行一些良性的互动,在社交平台上分享彼此的一些经历与看法;或者说我达成了某一项合作or完成了一项突破性工作,我会mention我的合作伙伴进而更好的在社交平台上推广自己,推销产品。因此,Mention Recommendation非常有现实意义的。
之前有很多工作在研究这个课题,我暂且仅列举两个例子,一个是传统的人工构建特征的方法,另一个是去年利用深度学习方法。之前大多数的方法,都是局限于用文本信息,根据推特的季度报告,它们有三亿多活跃月用户,每月的新推文量非常大,其中有42%的推文,是带有图片的。并且带有图片的推文相对于无图片的有1.5倍的概率被转推,如果我的一篇推文带有图片,能更好推销自己。单从这方面数据来说,图片对于社交平台上的分析具有很重要的作用。
为什么我需要多模态来做mention recommendation这个任务?
首先,这是我论文里面举的一个例子,我发推的时候说买了一个Mac,对IT同行们来说提到Mac首先想到的是电脑,而对大多数女性朋友来说Mac是她们比较喜欢的化妆品品牌。没有看图的时候,看到这样一句话会产生一定的歧义性。有时文本有一定的歧义性,引用图片的信息,对提升整个Mention Recommendation非常有价值。
因此我们从推特上构建一个数据集,一开始选了四千个用户,把它历史爬下来之后筛选有mention同时带有图片的推文,大概有三千个核心用户,再把核心的推特用户记录下来。
下面讲一下我们提出的模型。模型主要有三个部分构成,第一部分,我有一个需要被推荐的推文,我需要很好的建模它的推文内容信息;然后基于待推荐的推文内容信息,分别用于建模用户的文本和图片历史兴趣。
这是一个整体的模型图,红色代表的是图片相关信息,蓝色代表的是文本相关信息。(其中所有的图片都经过一个预训好的VGG-Net16,取最后个mean-pooling前的feature map,形成一个图片的特征矩阵)
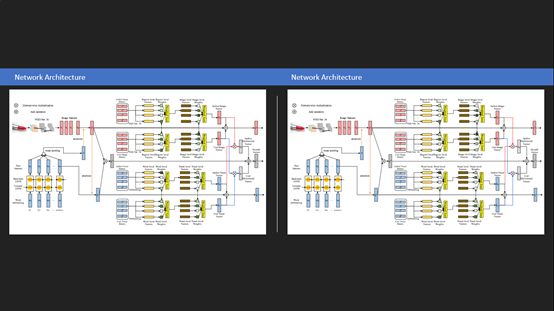
再细看每一个模块,对于query tweet的信息建模,首先应用的是co-attention的机制,对于文本内容的特征矩阵先mean-pooling,用这个文本向量对图片做attention,再用生成的图片向量对文本特征矩阵做一遍attention,来建模这个多模态的推特的整体表征。
对于后面的历史兴趣其实是分开两个对称的模块,以文本信息为例,我前面构建了一个要做预测推文的文本信息,基于它对用户历史文本信息进行一个Hierarchical-attention的建模。文本信息是有两个级别,一个是句子级别,一个是词级别,获得比较好的文本历史性建模。结合这三者做预测,它是可以堆叠很多层。
3 蒋卓人 中山大学
Cross-language Citation Recommendation via Hierarchical Representation Learning on Heterogeneous Graph

传统的学术搜索引擎大都是在同语种情况下进行检索和推荐,在跨语言的情况下,没办法直接计算不同语种文本的要素信息,比如文本相似度等。因此会面临一系列挑战:第一个挑战是所谓的信息需求转移的问题,对于跨语言问题而言,最直观的解决方法是基于机器翻译解决这个问题,但是我们认为机器翻译和引文推荐存在本质上的不同,因为基于机器翻译总是要找类似语意的文本,但是引文推荐我们需要找相关的论文,这里表示相关的信号并不一定具有相同语意和含义。
第二,既然引用的关系很重要的话,我们需要通过引用学到相关性的信号,但是我们发现,在这种跨语言的语料情况下,跨语言的引用关系非常稀少,我们在ACM和万方的数据库里进行了一个调查,平均而言,同语种的引用关系是跨语言引用关系的28倍之多。
第三,还有非常多其他类型的信息都可以帮助我们做引文推荐,但是目前的研究大多是基于一系列的人工定义的规则,例如元路径等,我们想做一些更加自动化的尝试,所以我们就提出我们的框架,Hierarchical Representation Learning on Heterogeneous Graph,想要构建一个异构信息图,把图上的节点投射到一个空间当中。这个算法,最重要的是生成一组叫relation type usefulness distribution的概率分布,通过概率分布进行自动化的异构图探索,我们把Heterogeneous Graph分成两层,一个是全局的,即在graph schema这个层面上,我们训练得到一组基于任务优化的关系类型重要性概率分布;另一个是局部的,我们在局部上依靠的是一组任务无关的关系转移概率分布,这个是我们建图时候已经确定的。最后通过一个双层的random walk去更好地进行异构图的探索。
我们这个工作是基于random walk based graph embedding的框架。即在一个图上进行随机游走生成一系列节点的序列,再把每个节点类比为一个词,用skip-gram去生成节点的表示。
但目前的随机游走的图表示学习方法还是存在一些问题。
第一,传统工作主要针对homogeneous graph,它不能直接应用在heterogeneous graph当中。
第二,也有一些heterogeneous graph的表示学习工作,例如metapath2vec等,但是它们大多需要一些人类先验的知识,不能完全自动化。
第三,目前的方法没有很好地用到全局的信息,主要是基于局部的信息,像graph-schema的信息也许能够带来一些帮助。
第四,我们发现其实大多数的方法都是要去encode网络拓扑信息,但能不能把一些任务相关的信息也嵌入节点表示当中去,即基于不同任务优化不一样的节点表示。所以,我们提出了一系列的relation type usefulness distribution,基于不同的任务,优化不同的节点表示,并学习不同边类型的重要性。
最终我们的算法框架对传统基于random walk的graph embedding框架进行了三个扩展,一是基于异构图,二是通过层次化的两层随机游走生成异构的节点序列,三是采用heterogeneous skip-gram生成节点表示。具体算法细节请参见我们的论文。
在实验上,我们做了基于中文论文推荐英文论文的实验,在ACM和万方的数据集上进行,对照了17组baseline,我们的方法取得了最好的效果。具体实验的细节参见我们的论文。
最后总结一下,第一,我们提出了一个异构图表示学习的方法,第二,尝试通过学习relation type usefulness distribution增加算法的可解释性,第三,我们在cross-language citation recommendation的这样一个有挑战性的任务中验证了模型,第四,我们这个工作其实可以应用在其他任务当中,只要该任务可以被建模成Hierarchical Representation Learning on Heterogeneous Graph。
4 黄瑾 中国人民大学
Improving Sequential Recommendation with Knowledge-Enhanced Memory Networks.

在推荐工作中使用Knowledge Base和Memory Network,能基于长期的数据的问题进行处理(能够获得基于属性的用户偏好表示,并能基于长期的数据问题进行处理)。
我们的模型是由RNN和Key-Value Memory Network组成,会获得两个组件的优点。用Knowledge Base的信息来增强模型的语义表示,就具有高度的可解释性。
我们的模型框架有两部分组成,时序推荐和Key-Value Memory Network。
首先,我们模型的第一个模块是RNN-based Networks,我们选用了GRU。输入给定用户的一个历史记录,计算出用户的时序偏好表示。由时序偏好表示和item,我们能得到用户在第t个时刻对item的一个偏好分数,我们会把分数高的推荐给用户。
第二个模块是Knowledge-Enhanced部分,首先用一个Key-Value Memory Networks,就是Key Memory存的是item的关系属性,比如说对于电影来讲,它可能会有导演、演员这一类关系,Value Memory中存放的是用户在对应关系中具体的偏好,比如它在导演方面喜欢詹姆斯·卡梅伦,其实对Key-Value Memory Network来讲它是把每个Memory分成两个部分,一个Key vector,一个是Value vector,它以pair对的形式存在于Memory中,这里要注意的是Key Memory中存放的向量是所有用户共享的,而在Value Memory中存放的向量是每个用户独有的。
而这个模型的运行是首先从GRU部分能得到用户的时序偏好表示,把时序偏好表示输入到Key-Value Memory Network中,可以得到用户在属性上的偏好。还有一个部分,Key-Value Memory Network的一个读写操作,当用户有一个新的交互记录的时候,我们用item来更新用户Memory Network的向量表示。
我们主要在四批数据集上做测试,在Freebase offline 的一个API上获取了他们对应的实体表示,考虑了两个任务,一个是next-item,一个是next-session,有几个评估参数。
考虑了非时序和时序的一个baseline,实验结果比较不错,还做了别的分析,最后是我们定性分析实验。我们主要分析在两个层面上是有可解释性的,一个是在Attribute-level,一个是在Value-level上具有可解释性。
这项工作主要集合了GRU-based的时序推荐以及knowledge-enhanced Key-Value Memory Network,能够有效提高它对语义的表示,我们构建了四批数据集并在四批数据集上有着不错的表示。
我们未来的工作可能集中在测模型的泛化能力,以及会考虑非结构性的数据和一些存在噪音的类似文本数据之类的内容。
5 秦川 中国科学技术大学
Enhancing Person-Job Fit for Talent Recruitment :An Ability-aware Neural Network Approach

我们基于能力感知的神经网络方法,设计帮助提升在人才招聘市场当中其中人岗匹配这个问题的性能。
随着最近互联网时代的一个快速发展,在线人才招聘网站,对传统人才招聘环节带来了一些新的变革,例如数据爆炸问题。Person-Job Fit也就是人岗匹配,这种匹配、推荐是双向的。人岗匹配分两个部分的数据,一部分是招聘信息,是对人才技能要求。匹配的对象,一般会展示以往的工作经历,或者项目经历。对于一个实际的招聘环节,不是所有能力都是非常重要的,我们希望通过历史招聘数据,对岗位所需要的能力,包括对人体现的能力进行一个加权处理。
举个例子,很多情况下我的一个岗位要求,我更关注的是比较具体的实际要求,而不是泛泛的,比如逻辑思维的要求。而且,对于一个岗位要求来讲,它有多条能力要求。
我们建立的框架是基于能力感知的神经网络系统,分三部分。
首先是词级别表征部分, 其次是一个复杂一些的是一种层级能力感知的表征方法,可以在之前的词义表征之上提出high-level的表征,我们分为四种层级能力感知的一种注意力机制,来帮助我们更好学习他的能力表征。
最后,人岗之间的一个预测匹配环节,去预测这个人和这个岗匹配程度到底有多好。
除了自己的模型,还有一种比较基础的基于RNN的人岗匹配的模型和传统的一些方法。相比之下,我们的模型达到了一个非常好的效果,并且做了一些基于数据稳定性的实验,包括还有一些基于时间效率的实验。
我们模型提升了在人岗匹配应用中的效率还有准确率,更多是希望能够帮助提供一种可解释性的建议给到我们HR的团队。
6 彭敏龙 复旦大学
Cross-Domain Sentiment Classification with Target Domain Specific Information

我们是用Target Domain Specific信息去做Cross-Domain。
首先,我用一个例子介绍一下什么是Cross-Domain, 我们假设Book Domain里面有大量标注数据,而在Kitchen Domain里面我们只有少量的,甚至没有labeled data以及大量的unlabeled data数据,cross-domain 希望利用这些数据训练一个在kitchen domain上有良好表现的模型。目前一个主流方法是提取domain-invariant表示并在该表示上用labeled数据训练模型。参考该类方法,我们工作有以下两点动机:
第一,Domain-specific的表示也包含很多信息。第二,有限的target domain标注数据如果我们在specific信息上进行训练,会比在所有的特征空间里面进行训练更有效。
基于这两个motivations,我们提出一下cross-domain框架。首先提取domain-invairant的特征表示,也就是绿色的表示,目标是训练的Invariant classifier,称为F_c。然后是specific的特征表示,目标是训练Specific classifier,我们称之为F_t。这两个classifiers在target unlabeled data上作co-training,更有效的利用target specific数据。
将domain-invariant和domain-specific的两个特征组合起来,要尽可能重构原始的输入。并且这个重构只在target domain上训练的。在这个空间下,specific domain跟target domain尽可能不一致,也是基于CMD提出来的,这里我们引入了一个负号,要求两个distributions要尽可能不相似。
在这个target domain(目标域)特征空间下,我们用target domain的有标签数据训练了一个分类器。因为目标域的带标签数据量是比较少的,我们希望尽可能高效利用这个数据,于是引入了一个co-training的训练框架。
co-training的意思就是,比如说你有两个分类器,你把一个分类器在没有标注的数据上做预测,然后挑选出你最确信的那个数据,然后把它加入到带标签的数据集里面。同样,对于另外一个分类器也是同样的操作。然后重新训练这两个分类器,然后做迭代,实现co-training。
关于实验结果,我们基于Amazon review上面12个cross-domain的任务上,实现了提升。对于差异比较大的domain上,我们提升比较大,比如dvd到electronics,还有dvd到kitchen。
同时,我们还做了可视化。可以看到在domain-invariant特征下,specific domain和target domain它们是date distribution是很接近的,也就是它们的data distribution是很接近的。在target domain和specific的空间下,specific domain和target domain它们区别很大,它们的data distribution差异比较大。
7 许晶晶 北京大学
Unpaired Sentiment-to-Sentiment Translation Using Cycled Reinforcement Learning

我们在做一个情感转换的任务,解释一下就是给你一句话,我们的模型可以准确的把它的语义保留下来,在保留语义的同时把情感做一个反转。比如这个电影不好看,一般模型输出,这个电影非常的好看。而实际可以用一个反转词表解决问题。
人在表达自己情感的时候是非常复杂的,有的是用情感词表示的,但有的不是,比如,输入“这顿饭难吃得跟石头一样”,不能反转成“这顿饭好吃得跟石头一样”。
另外,现在没有标准、成对的训练语料,标注语料需要人力。
最后,很多知识库有情感辞典,有很多情感词有多义现象,它的反义词有很多,但设置一系列规则方式,效果很差。而且很多情感词在辞典中没有反义词。
面对上面的问题,我们会把情感信息和语义信息在一个语层上剥离,在语义信息上反转信息生成句子。为了避免情感和语音信息同时被改变,我们提出这个模型。
这个模型主要有三大部分组成。
第一部分,去情感模块,直接显示把情感词去掉,优点在于去情感词的同时,非情感词是留下的,所以这个在去情感的时候可以把语义信息留下。
第二部分,加情感模块。有几个不同的解码器,不同的解码器根据你想要的情感生成对应情感文本。
第三部分,强化学习模块,因为这两个模型是孤立的,中间的梯度是断的,我们提出一种强化学习方法,来训练以上这两个模块。
去情感模块运用常见的LSTM模型,它的目标是把情感词检测出来。我们训练了一个情感分类器,用这个情感分类器学到的attention的那个权重来指导去情感,所以我们直接拿情感分类器的attention做训练语料训练这个模块。
加情感模块设了两个不同情感的解码器,训练是很简单的,我们没有平行语料,没办法产生一个去情感的文本,要生成反面的,测试的时候加一个反转情感,就可以实现。
强化学习的方法是用情感分类器给它一个奖励,我们BLEU 分数来做这个奖励。
关于实验结果,在两个数据集上,亚马逊的数据上做了一个实验,可以明显看出BLEU score在语义上提高的非常明显,这个结果和人工评测也是一致的,在语义保持上提升得非常明显,这也是我们模型的优点。在生成样例的时候,我们的模型是记忆反转的情况,也是语义保持比较好的。
8 范创 哈尔滨工业大学(深圳)
Convolution-based Memory Network for Aspect-based Sentiment Analysis

不同于传统的文本情感分类,方面级的情感分类需要对文本中不同的目标判断其情感倾向性。例如在下面的例子中,同一段文本对三个不同的目标,分别表现了正向、中性、负向三种不同的情况。
目前在该任务中主要以下几个挑战,首先是如何对文本和目标之间的关系进行细粒度的建模,而且我们知道,在文本中一个单词的具体含义往往由其上下文决定。我们如何对基于多词的复杂情感表达进行建模,也是一个非常值得考虑的问题。
在之前的研究方法中,从最早的基于特征的方法以及到现在基于深度学习的循环注意力机制,都取得了一个相当不错的成果,但是这些方法都没有充分考虑到刚才说的那种针对于多词的复杂情感表达进行建模。为了解决这个问题,我们提出了一个基于卷积操作的注意力机制。
在我们的方法中,选择了记忆网络作为模型的一个基础框架,此时模型的输入就是target embedding,我们将其作用于不同的记忆单元,将会为每一个单元分配一个权重,我们希望用这种方式对文本和target之间的关系进行一个建模。最后,记忆单元的线性组合作为最终的分类特征。
由于深层的模型,往往对于数据有更好的拟合能力,单层的记忆网络可以扩展成多层,此次对于第i层来说,它的输入来自前一层输出,而它的输出又可以作为下一层输入。最后一层的输出就是我们最后的分类特征,这种模型虽然解决了对文本和目标之间关系的建模,但是对之前复杂的情感表达,仍然缺乏建模能力。
而在我们的模型当中,我们通过双向GRU提取文本的一个序列特征,我们的输入也是target embedding,此时计算每一个位置的权重时,不仅考虑到当前的记忆单元,而考虑之前的t个记忆单元,以及之后的t个记忆单元,我们希望通过这种方式对每个位置的上下文进行显示的建模。
此时我们得到的一个αi它其实包含了(2t+1个记忆单元),此时当我们的αi作用于不同的机器单元时,我们可以对整个模型得到2t+1个机器输出,我们称之为oj,我们将这2t+1个机器输出oj连接起来,作为最后的分类向量。
我们做了一个卷积操作窗口大小对性能的影响,当K等于1的时候,其实我们注意力机制退化成传统的注意力机制,而K等于3的时候,我们其实考虑了当前位置上的前一个词和后一个词,共三个单元,此时模型得到最佳的性能。当我们考虑到上下文更多的时候,这个时候认为性能下降原因在于它上下文中的噪声可能就多于有用的信息。
注意力机制的可视化结果有两个现象可以关注,首先是我们模型的注意力是成块的集中在文本中的某些区域,这就对应于文本中的多词表达。此外,随着层数的堆叠,模型注意力有一个逐渐转移的过程,也从侧面证明了模型注意力机制的有效性。
总的来说,我们的工作主要包括以下三个方面,首先,将memory network作为一个基础框架,同时,为了捕获基于多词的复杂情感表达,我们提出了一种基于卷积操作的注意力机制,而实验的定性和定量分析也证明了模型的有效性。
我们一起探讨AI落地的最后一公里
推荐文章阅读
读芯君爱你
以上是关于情感分析与推荐算法专场(视频+实录+PPT)| AIS预讲会全程干货分享的主要内容,如果未能解决你的问题,请参考以下文章
以标准的名义!DevOps 国际峰会 2018 · 深圳站精彩实录(附大会PPT)
今日头条抖音:4亿日活的推荐系统架构与算法实践,33页ppt详解!