推荐算法——协同过滤
Posted AI初见
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐算法——协同过滤相关的知识,希望对你有一定的参考价值。
推荐算法具有很多的应用场景和很大的商业价值,比如今日头条、百度资讯、京东商城等都会根据一定的信息向用户推荐相关内容,因此推荐算法非常值得研究。协同过滤是目前应用最为广泛的一种推荐算法。下面做简单介绍。
1 推荐算法概述
(1)推荐系统
在工作生活中,我们常常通过谷歌、百度等搜索引擎获取相关的目标信息。在目标明确的情况下,搜索引擎是很好的信息获取方式,但如果目标不明确,比如不知道搜索什么关键字时,搜索引擎就不行了。那么,怎么办呢?系统可以根据相关的信息,把符合用户个人口味和喜好的内容推荐给用户,这就是推荐系统,与搜索引擎相对应,称为推荐引擎。
推荐引擎利用特定的信息过滤技术,把不同的物品或内容推荐给可能对它感兴趣的用户。
其工作原理如图示:
从图中可以看出,一般情况下,推荐系统的数据来源一般包括三个方面:物品、用户、用户对物品的喜好。
(2)推荐系统分类
基于数据来源的不同,可以将推荐系统划分为三类:
A,根据用户信息发现用户的相关程度,称为基于人口统计学的推荐。优点:不适用当前用户的历史数据,可以应对新用户的“冷启动”问题;不依赖于物品本身,对不同领域都可以使用。缺点:用户信息不易获取,尤其涉及敏感信息;推荐只是依据用户信息进行分类,过于粗糙,不适合对品味要求高的领域,比如图书、电影、音乐等。
B,根据物品或内容的元数据,发现物品或内容的相关型,称为基于内容的推荐。优点:对物品或内容可以很好的建模,能提供更加准确的推荐。缺点:需要对物品进行分析和建模,效果依赖于模型的完整性;没有考虑人的感受;因为需要用户的历史喜好信息,所以存在新用户的冷启动问题。
C,根据用户对物品或信息的喜好,发现物品或内容的相关性,或发现用户的相关性,即被称为基于协同过滤的推荐。
基于推荐模型的建立方式,可将推荐系统划分为以下三类:
A,基于物品和用户本身的推荐,这种推荐引擎将每个用户和物品都当作独立的实体,预测每个用户对每个物品的喜好程度,这些信息往往是一个二维矩阵。由于用户感兴趣的物品远远小于总物品的数目,这样的模型导致大量的数据空置,即我们得到的二位矩阵往往是一个很大的稀疏矩阵,但这样的模型又会在推荐系统的准确性上有损失;
B,基于关联规则的推荐:关联规则的挖掘已经是数据挖掘中的一个经典的问题,组要是挖掘一些数据的依赖关性,典型的场景就是“购物篮问题”,通过关联规则的挖掘,可以找到那些物品经常被同时购买,或者用户购买一些物品后通常会购买哪些其他的物品。当挖掘出关联规则后,就可以基于这些规则给用户推荐;
C,基于模型的推荐: 根据已有的用户喜好信息作为训练样本,训练出一个预测用户喜好的模型,这样以后用户进入系统,可以基于这个模型计算推荐。该方法问题在于如何将用户实时或者近期的喜好信息反馈给训练好的模型,从而提高推荐的准确度。
2 基于协同过滤的推荐
随着Web2.0的发展,Web站点更加提倡用户参与和用户贡献,因此基于协同过滤的推荐机制应运而生。其原理很简单,大体可分为三类:
(1)基于用户的协同过滤推荐
原理:根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,然后对当前用户进行推荐,一般使用“K-近邻”算法找到相似“邻居”。
步骤:
A,寻找与当前用户关系较近的“邻居”用户,得到相关系数
B,获取邻居用户对物品的评分;
C,去除当前用户已经浏览或接触的物品/内容,将剩余的物品和内容按照一定规则推荐给当前用户。
常见的有两种推荐规则方法:直接推荐,即找到与当前用户最相关的邻居,将其评分较高的物品推荐给当前用户;加权排序,即对某一物品,邻居的评分*邻居的相关系数,然后将所有用户的值叠加求和,即得到这个物品的加权评分,对所有物品的加权评分排序,然后挑选出加权评分较高的物品推送给当前用户。
示例:
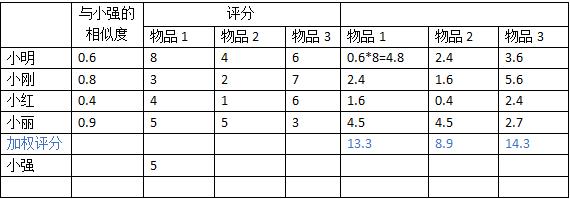
如上表所示,假设只需要推荐一种物品。(1)若按照直接推荐的方法,小丽与小强的相似度最高,那么从小丽的评分物品中选取,物品1和2的评分都很高,但请注意小强已经对物品1做过评分,故不需再推荐,所以将物品2推荐给小强;(2)若按照加权排序推荐的方法,物品3的加权评分最高,而小强没有评价过,所以将物品3推荐给小强。
(2)基于项目(物品)的协同过滤推荐
基于项目的协同过滤,说直白点就是,给当前用户推荐和其之前喜欢的物品相似的物品。
示例:为实现目标,需要建立物品同现矩阵和用户的评分矩阵,然后求得评分。
推荐评分矩阵 = 物品同现矩阵*评分矩阵,即有
将结果填入入上表中。
仍假设只需要推荐一个物品。从推荐评分矩阵中可以看到,物品1、2、3、4的评分依次为21、17、18、10。首先,去除用户已评分的物品1和2,还剩下物品3和物品4,那么物品3的评分比物品4的评分高,所以,将物品3作为推荐物品。
(3)基于模型的协同过滤推荐
基于模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实施的用户喜好的信息进行预测,计算推荐。(基于模型的协同过滤相关算法较多,稍后会挑选一两个算法学习说明)
优点:不需要对物品或用户进行严格的建模,并且不要求物品的藐视是机器可以理解的;该方法计算出来的推荐是开放的,可以共用他人的经验,而可以很好的支持用户发现潜在的偏好。
缺点:方法的核心是基于历史数据,对新用户和新物品都有冷启动问题;推荐的效果依赖于用户历史数据的多少和准确性;在实际用用中,用户历史偏好是用稀疏矩阵存储的,而稀疏矩阵上的计算有明显的问题,包括可能少部分人的错误偏好会对推荐系统的准确度有较大影响;对于一些特殊品味的用户,不能基于很好的推荐;该方法基于用户历史数据,不够灵活。
(4)混合的推荐机制,当前系统中,很少有只使用一种推荐的机制和策略,往往会将很多方法混合在一起,从而达到更好的效果。比如加权、切换、分区、分层等。
3 冷启动问题
(1)什么是冷启动?
很多推荐机制是基于历史数据的,不论是用户历史数据,还是物品的历史数据,如何在没有历史数据的情况下设计个性化的推荐系统,并让用户对推荐结果满意,这就是冷启动问题。
(2)冷启动分类
用户冷启动:即如何给新用户个性化推荐
物品冷启动:即如何将新的物品推荐给可能对它有兴趣的用户
系统冷启动:如何在一个新的系统(没有用户、没有用户行为,只有少部分物品)上设计个性化推荐系统,从而使系统刚发布时,就让用户体会到个性化推荐。
(3)冷启动解决方案
A,利用用户注册信息
注册信息大体分为3类:1)人口统计学信息,如年龄、性别、职业、学历等;2)用户感兴趣的描述,如用户填写感兴趣的描述;3)从其他网站导入数据。
处理流程:1)获取用户注册信息;2)根据注册信息对用户分类;3)给用户推荐所属分类中的物品。
B,提供非个性化的推荐,比如热门排行榜
C,选择合适的物品启动用户的兴趣
通过让用户对物品进行评分来收集用户兴趣,例如新用户第一次访问时,并不立即给用户展示推荐结果,而是给用户提供一些物品,让用户对其反馈,根据用户反馈提供个性化支持
D,利用物品的内容信息
即用来解决新加入物品的冷启动问题,其中一个方法可以是计算与其最相似的物品,然后将其推荐给相关用户。
E,利用用户在其他地方已经沉淀的数据进行冷启动
F,发挥专家的作用等
参考链接:
(1)《推荐引擎初探》https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/index.html
(2)《推荐系统浅谈系列(三)-冷启动问题》https://www.jianshu.com/p/97e46f933010
精诚所至,金石为开
以上是关于推荐算法——协同过滤的主要内容,如果未能解决你的问题,请参考以下文章