美团推荐算法:机器学习重排序模型
Posted 信息安全club
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了美团推荐算法:机器学习重排序模型相关的知识,希望对你有一定的参考价值。
【转】http://blog.csdn.net/chndata/article/details/43405641
原文由美团技术团队成员撰写,介绍其推荐系统的构建和优化过程中的一些做法。
框架
从框架的角度看,推荐系统基本可以分为数据层、触发层、融合过滤层和排序层。数据层包括数据生成和数据存储,主要是利用各种数据处理工具对原始日志进行清洗,处理成格式化的数据,落地到不同类型的存储系统中,供下游的算法和模型使用。候选集触发层主要是从用户的历史行为、实时行为、地理位置等角度利用各种触发策略产生推荐的候选集。候选集融合和过滤层有两个功能,一是对出发层产生的不同候选集进行融合,提高推荐策略的覆盖度和精度;另外还要承担一定的过滤职责,从产品、运营的角度确定一些人工规则,过滤掉不符合条件的item。排序层主要是利用机器学习的模型对触发层筛选出来的候选集进行重排序。
同时,对与候选集触发和重排序两层而言,为了效果迭代是需要频繁修改的两层,因此需要支持ABtest。为了支持高效率的迭代,我们对候选集触发和重排序两层进行了解耦,这两层的结果是正交的,因此可以分别进行对比试验,不会相互影响。同时在每一层的内部,我们会根据用户将流量划分为多份,支持多个策略同时在线对比。
数据应用
数据乃算法、模型之本。美团作为一个交易平台,同时具有快速增长的用户量,因此产生了海量丰富的用户行为数据。当然,不同类型的数据的价值和反映的用户意图的强弱也有所不同。

1.用户主动行为数据记录了用户在美团平台上不同的环节的各种行为,这些行为一方面用于候选集触发算法(在下一部分介绍)中的离线计算(主要是浏览、下单),另外一方面,这些行为代表的意图的强弱不同,因此在训练重排序模型时可以针对不同的行为设定不同的回归目标值,以更细地刻画用户的行为强弱程度。此外,用户对deal的这些行为还可以作为重排序模型的交叉特征,用于模型的离线训练和在线预测。
2.负反馈数据反映了当前的结果可能在某些方面不能满足用户的需求,因此在后续的候选集触发过程中需要考虑对特定的因素进行过滤或者降权,降低负面因素再次出现的几率,提高用户体验;同时在重排序的模型训练中,负反馈数据可以作为不可多得的负例参与模型训练,这些负例要比那些展示后未点击、未下单的样本显著的多。
3.用户画像是刻画用户属性的基础数据,其中有些是直接获取的原始数据,有些是经过挖掘的二次加工数据,这些属性一方面可以用于候选集触发过程中对deal进行加权或降权,另外一方面可以作为重排序模型中的用户维度特征。
4.通过对UGC数据的挖掘可以提取出一些关键词,然后使用这些关键词给deal打标签,用于deal的个性化展示。
策略触发
上文中我们提到了数据的重要性,但是数据的落脚点还是算法和模型。单纯的数据只是一些字节的堆积,我们必须通过对数据的清洗去除数据中的噪声,然后通过算法和模型学习其中的规律,才能将数据的价值最大化。在本节中,将介绍推荐候选集触发过程中用到的相关算法。
1. 协同过滤
提到推荐,就不得不说协同过滤,它几乎在每一个推荐系统中都会用到。基本的算法非常简单,但是要获得更好的效果,往往需要根据具体的业务做一些差异化的处理。
清除作 弊、刷单、代购等噪声数据。这些数据的存在会严重影响算法的效果,因此要在第一步的数据清洗中就将这些数据剔除。
合理选取训练数据。选取的训练数据的时间窗口不宜过长,当然也不能过短。具体的窗口期数值需要经过多次的实验来确定。同时可以考虑引入时间衰减,因为近期的用户行为更能反映用户接下来的行为动作。
user-based与item-based相结合。
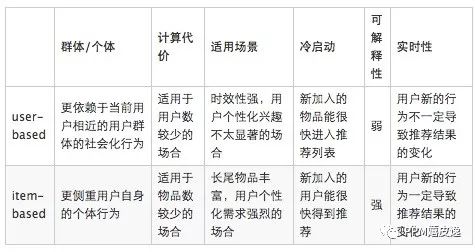
尝试不同的相似度计算方法。在实践中,我们采用了一种称作loglikelihood ratio[1]的相似度计算方法。在mahout中,loglikelihood ratio也作为一种相似度计算方法被采用。
下表表示了Event A和EventB之间的相互关系,其中:
k11 :Event A和EventB共现的次数
k12 :Event B发生,EventA未发生的次数
k21 :Event A发生,EventB未发生的次数
k22 :Event A和EventB都不发生的次数

则logLikelihoodRatio=2 * (matrixEntropy - rowEntropy -columnEntropy)
其中
rowEntropy = entropy(k11, k12) + entropy(k21, k22)
columnEntropy = entropy(k11, k21) + entropy(k12, k22)
matrixEntropy = entropy(k11, k12, k21, k22)
(entropy为几个元素组成的系统的香农熵)
2. location-based
对于移动设备而言,与PC端最大的区别之一是移动设备的位置是经常发生变化的。不同的地理位置反映了不同的用户场景,在具体的业务中可以充分利用用户所处的地理位置。在推荐的候选集触发中,我们也会根据用户的实时地理位置、工作地、居住地等地理位置触发相应的策略。
根据用户的历史消费、历史浏览等,挖掘出某一粒度的区域(比如商圈)内的区域消费热单和区域购买热单
区域消费热单
区域购买热单
当新的线上用户请求到达时,根据用户的几个地理位置对相应地理位置的区域消费热单和区域购买热单进行加权,最终得到一个推荐列表。
此外,还可以根据用户出现的地理位置,采用协同过滤的方式计算用户的相似度。
3. query-based
搜索是一种强用户意图,比较明确的反应了用户的意愿,但是在很多情况下,因为各种各样的原因,没有形成最终的转换。尽管如此,我们认为,这种情景还是代表了一定的用户意愿,可以加以利用。具体做法如下:
对用户过去一段时间的搜索无转换行为进行挖掘,计算每一个用户对不同query的权重。
计算每个query下不同deal的权重。
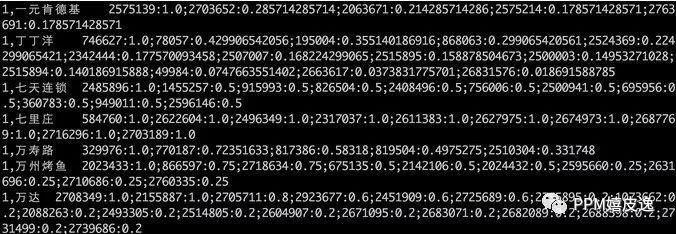
当用户再次请求时,根据用户对不同query的权重及query下不同deal的权重进行加权,取出权重最大的TopN进行推荐。
4. graph-based
对于协同过滤而言,user之间或者deal之间的图距离是两跳,对于更远距离的关系则不能考虑在内。而图算法可以打破这一限制,将user与deal的关系视作一个二部图,相互间的关系可以在图上传播。Simrank[2]是一种衡量对等实体相似度的图算法。它的基本思想是,如果两个实体与另外的相似实体有相关关系,那它们也是相似的,即相似性是可以传播的。

5. 实时用户行为
目前我们的业务会产生包括搜索、筛选、收藏、浏览、下单等丰富的用户行为,这些是我们进行效果优化的重要基础。我们当然希望每一个用户行为流都能到达转化的环节,但是事实上远非这样。
当用户产生了下单行为上游的某些行为时,会有相当一部分因为各种原因使行为流没有形成转化。但是,用户的这些上游 行为对我们而言是非常重要的先验知识。很多情况下,用户当时没有转化并不代表用户对当前的item不感兴趣。当用户再次到达我们的推荐展位时,我们根据用户之前产生的先验行为理解并识别用户的真正意图,将符合用户意图的相关deal再次展现给用户,引导用户沿着行为流向下游 行进,最终达到下单这个终极目标。
目前引入的实时用户行为包括:实时浏览、实时收藏。
6. 替补策略
虽然我们有一系列基于用户历史行为的候选集触发算法,但对于部分新用户或者历史行为不太丰富的用户,上述算法触发的候选集太小,因此需要使用一些替补策略进行填充。
热销单:在一定时间内销量最多的item,可以考虑时间衰减的影响等。
好评单:用户产生的评价中,评分较高的item。
城市单:满足基本的限定条件,在用户的请求城市内的。
子策略融合
为了结合不同触发算法的优点,同时提高候选集的多样性和覆盖率,需要将不同的触发算法融合在一起。常见的融合的方法有以下几种:
加权型:最简单的融合方法就是根据经验值对不同算法赋给不同的权重,对各个算法产生的候选集按照给定的权重进行加权,然后再按照权重排序。
分级型:优先采用效果好的算法,当产生的候选集大小不足以满足目标值时,再使用效果次好的算法,依此类推。
调制型:不同的算法按照不同的比例产生一定量的候选集,然后叠加产生最终总的候选集。
过滤型:当前的算法对前一级算法产生的候选集进行过滤,依此类推,候选集被逐级过滤,最终产生一个小而精的候选集合。
目前我们使用的方法集成了调制和分级两种融合方法,不同的算法根据历史效果表现给定不同的候选集构成比例,同时优先采用效果好的算法触发,如果候选集不够大,再采用效果次之的算法触发,依此类推。
候选集重排序
如上所述,对于不同算法触发出来的候选集,只是根据算法的历史效果决定算法产生的item的位置显得有些简单粗暴,同时,在每个算法的内部,不同item的顺序也只是简单的由一个或者几个因素决定,这些排序的方法只能用于第一步的初选过程,最终的排序结果需要借助机器学习的方法,使用相关的排序模型,综合多方面的因素来确定。
1. 模型
非线性模型能较好的捕捉特征中的非线性关系,但训练和预测的代价相对线性模型要高一些,这也导致了非线性模型的更新周期相对要长。反之,线性模型对特征的处理要求比较高,需要凭借领域知识和经验人工对特征做一些先期处理,但因为线性模型简单,在训练和预测时效率较高。因此在更新周期上也可以做的更短,还可以结合业务做一些在线学习的尝试。在我们的实践中,非线性模型和线性模型都有应用。
非线性模型
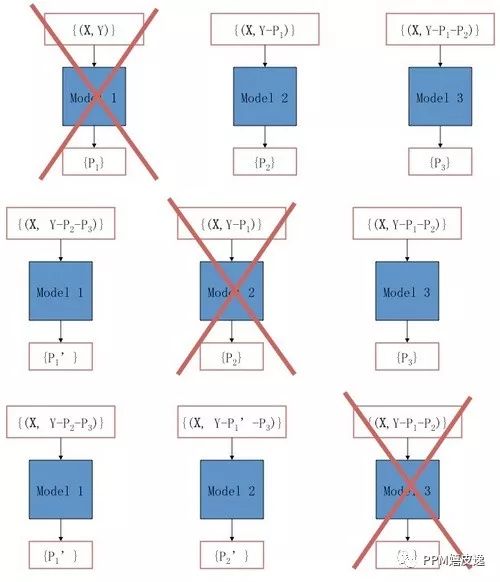
目前我们主要采用了非线性的树模型Additive Groves[4](简称AG),相对于线性模型,非线性模型可以更好的处理特征中的非线性关系,不必像线性模型那样在特征处理和特征组合上花费比较大的精力。AG是一个加性模型,由很多个Grove组成,不同的Grove之间进行bagging得出最后的预测结果,由此可以减小过拟合的影响。
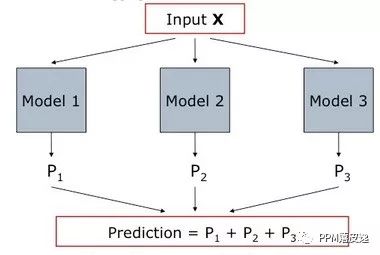
每一个Grove有多棵树组成,在训练时每棵树的拟合目标为真实值与其他树预测结果之和之间的残差。当达到给定数目的树时,重新训练的树会逐棵替代以前的树。经过多次迭代后,达到收敛。
线性模型
目前应用比较多的线性模型非Logistic Regression莫属了。为了能实时捕捉数据分布的变化,我们引入了online learning,接入实时数据流,使用google提出的FTRL[5]方法对模型进行在线更新。
主要的步骤如下:
在线写特征向量到HBase
Storm解析实时点击和下单日志流,改写HBase中对应特征向量的label
通过FTRL更新模型权重
将新的模型参数应用于线上
2. 数据
采样:对于点击率预估而言,正负样本严重不均衡,所以需要对负例做一些采样。
负例:正例一般是用户产生点击、下单等转换行为的样本,但是用户没有转换行为的样本是否就一定是负例呢?其实不然,很多展现其实用户根本没有看到,所以把这样样本视为负例是不合理的,也会影响模型的效果。比较常用的方法是skip-above,即用户点击的item位置以上的展现才可能视作负例。当然,上面的负例都是隐式的负反馈数据,除此之外,我们还有用户主动删除的显示负反馈数据,这些数据是高质量的负例。
去噪:对于数据中混杂的刷单等类作 弊行为的数据,要将其排除出训练数据,否则会直接影响模型的效果。
3. 特征
在我们目前的重排序模型中,大概分为以下几类特征:
deal(即团购单,下同)维度的特征:主要是deal本身的一些属性,包括价格、折扣、销量、评分、类别、点击率等
user维度的特征:包括用户等级、用户的人口属性、用户的客户端类型等
user、deal的交叉特征:包括用户对deal的点击、收藏、购买等
距离特征:包括用户的实时地理位置、常去地理位置、工作地、居住地等与poi的距离
对于非线性模型,上述特征可以直接使用;而对于线性模型,则需要对特征值做一些分桶、归一化等处理,使特征值成为0~1之间的连续值或01二值。
总结
以数据为基础,用算法去雕琢,只有将二者有机结合,才会带来效果的提升。对我们而言,以下两个节点是我们优化过程中的里程碑:
将候选集进行融合:提高了推荐的覆盖度、多样性和精度
引入重排序模型:解决了候选集增加以后deal之间排列顺序的问题
以上是关于美团推荐算法:机器学习重排序模型的主要内容,如果未能解决你的问题,请参考以下文章