商品推荐算法&推荐解释
Posted SAS中文论坛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了商品推荐算法&推荐解释相关的知识,希望对你有一定的参考价值。
这是今天看到的一篇蛮有新意的讲稿,由于不是一篇完整的论文,所以理解起来稍微有些困难,就顺着写个笔记,仅供参考。
在这篇文章中,我分成两部分,我们先顺着作者的思路去理解,如果对数学不感兴趣就直接往下拉,最后我会说按我的理解中我们需要从作者这里吸取什么和我推荐的做法。
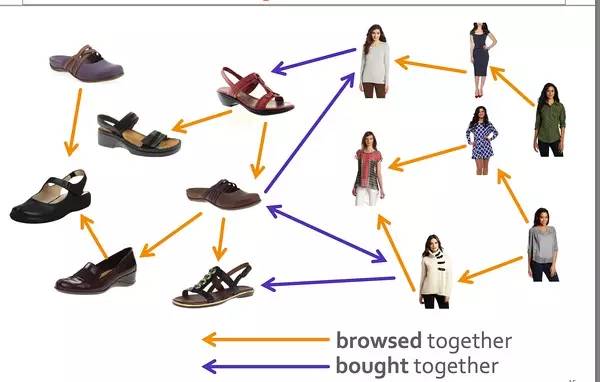
做过商品或者条目推荐的同学,应该都创建过一张这样的Product Graph. 但是这样的图谱不具备文本含义的解释性,而且也没办法很好的和内容关联起来。我相信大部分同学之前一般的做法是这样子,先找到同一个类别,然后在同一个类别里做这样的事儿。
生成一张完整的产品图谱的作用有以下几个:

但是这里很重要,因为如果单纯用类别可以找到替代品,但是找不到互补品。

另外的一个问题还在于怎样生成替代品的推荐理由,应该是更好,而不是他们包含同一关键词。

推荐一整套装备。
所以我们讲产品问题转换成数学模型问题:
在模型层面: 是否我们可以使用产品数据建模,来表示出产品之间的关系
在产品理解层面: 我们是否可以解释为什么用户更喜欢某一个产品而不是其他的
问题建模:
作为一个二元分类问题,来看p(x,y),也就是x和y之间是否有关联。
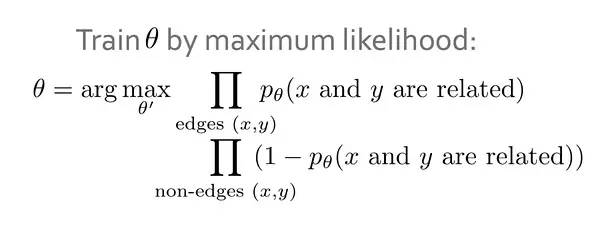
那么整体的优化目标就变成了这个样子,也就是希望有边的都是有关联的,没边的都是没关联的。这样就变成了优化p(x,y),于是问题转换成了用什么作为维度来预测。
于是作者做了如下的尝试:
1. 直接计算文本相似度,文本用的是用户的评论以及商品描述
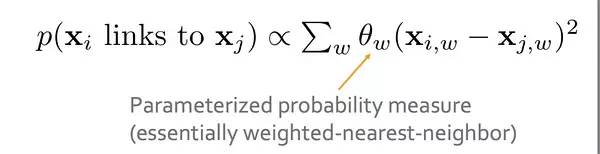
其实和我们传统计算文本相似度很类似,但是最终的训练数据是item之间的连接关系,所以其实转换成训练不同topic维度的权重。
2. Topic Model来降维,避免维度灾难

这个优化的路子肯定是没问题的,但是这个优化方式的问题在于我们把生成topic这件事情本身和商品之间是否存在关系这两件事情给独立看待了,而只是在后来强行地加入了不同topic的权重参数以适应训练数据的需要。也就是说Topic并没有很好的和Link去结合起来。所以我们要想办法找到和Link相关的正确的Topic才行。因为我们要时刻记得我们产生Topic的意义不仅仅是用来做推荐,还有为基于Link关系的商品推荐生成推荐理由,topic生成与商品之间的连接关系息息相关。
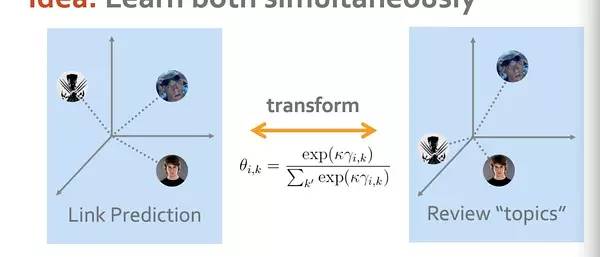
所以我们需要把这两个不同方向的分解做个中和,这样才能用topic来解释link的关系。
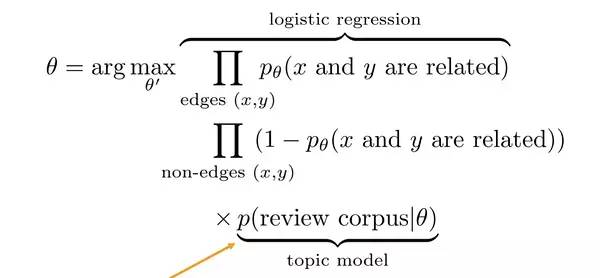
作者的办法就是通过相乘把他们合并起来了,那么这个公式的意义是什么?计算因子的计算稍微有点绕,我们先把公式列出来再看详细的说明:

我们分开来看,看这部分的意义:
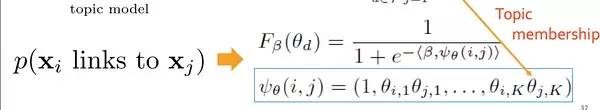
这是一个逻辑回归的函数,如果希望目标函数F最大,也就是应该使指数部分的相反数最大,Beta是一个训练权重暂且不谈,也就是应该使Psi最大,也就是说让i和j所属的topic分布尽量一致。这样其实就把生成topic的过程与最终的目标完全结合起来了,而不是把希望寄托于权重参数上。
接下来问题就变成了我们如何训练Theta呢:
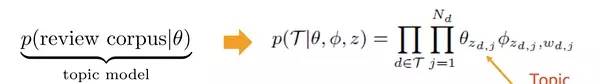
这里我被误导了,我一直在用LDA来折腾这里的公式。后来发现其实并没有使用LDA,而是使用的PLSA的训练模型,我个人认为原因应该是模型的复杂性吧。为了方便大家回归PLSA的数学意义,粘一段LDA数学八卦的讲解:

最后回到刚才的整体优化目标函数上,作者其实表达了两件事情,首先是希望做出的topic分解能够最符合当前link的训练数据;另外也希望最符合topic model的优化模型。
那么接下来做了几点的持续优化:
1. 我们之前所有的训练都是基于无向图的,例如买了iPhone可以买手机壳,但是买手机壳推荐iPhone就是一个不好的推荐了。所以作者的解决方案是对训练的参数做了调整:

其实大家可以理解为参数又多了一个……..于是我们就可以在topic上形成了递进关系,过去我们只能说,他们都是移动硬盘,但是现在就可以在语言描述上说,这是比他更高端的移动硬盘。
2. 如果大家有一些解优化函数的经验,看到上面的优化函数都会头大,不是因为不能解,完全可以依照PLSA的方法用EM方法去搞,但是参数实在太多了,算起来完全无法想象。所以作者结合了具体业务将商品形成了目录树:
然后作者没有细致去讲,大概意思也就是说那么多topic其实也就10到20个目录和这个商品有联系,所以可以极大地节省运算量。但是作者也承认,非常慢!
那么我们抛除模型,看看这篇paper带给了我们什么启示,这篇文章核心其实就是在解决“推荐解释”的问题,当然顺路也提高了推荐的准确性。作者从几个角度去出发,这几点都是值得我们在做推荐算法的时候考虑的:
<1> 推荐的递进性,我们过去无论在做商品聚类,还是基于标签推荐时,都是基于一个无向的“图模型”。
<2> 区分出互补性和替代性,这一点其实我承认过去并没有系统地考虑过,我们通常的推荐都是基于互补性的。
但是从工程角度上,并不适合上来就搭建这么复杂的模型,所以我们可以适当做简化,例如:
<1> 认为相同目录下的商品是替代关系,不同目录的商品是互补关系。
<2> 通过抽取不同类目的关键词和情感词,给每个类目一组关键词,例如鞋子可以分成Size, 颜色, 舒适度,性价比等,然后通过关键词抽取对商品的不同维度去做分级,从而在推荐理由的时候就可以形成推荐产品的递进关系。
<3> 做topic model的时候也应该是同一个类目下做,这样计算量也小了很多。
<4> 使用买了也买的link关系训练topic model中不同维度的权重时,只训练同一子目录就够了,因为不同目录下的商品的topic之间其实没啥联系。
总之在工业界做过数据挖掘和推荐系统的人应该知道,只要达到目的就足够了,用什么模型其实真的没有那么重要,优化了好久的模型还真的不如加两条规则,或者人工清洗一下数据好用。模型真正的价值是泛化,但是对于工业界来说,泛化能力不需要太强,只要限定在当前的产品线就够了,如果产品形态改了大不了我再来一个算法就可以了。这也就是为什么很多算法模型没必要搞的那么复杂但是效果一样很好的缘故。
以上是关于商品推荐算法&推荐解释的主要内容,如果未能解决你的问题,请参考以下文章