推荐算法基于LR的推荐算法
Posted 智能推荐系统
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐算法基于LR的推荐算法相关的知识,希望对你有一定的参考价值。
1、原理介绍
LR(逻辑斯蒂回归)算法的本质是一个线性回归函数,该算法主要用作二分类的场景,例如点击率预估,算法公式如下:
其中x是模型的输入
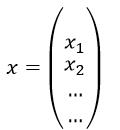
xi表示每个维度的输入。
w是表示模型输入x的系数向量,w=( w1, w2, …), wi表示维度xi的权重。
2、模型求解
我们通过梯度下降法求解我们的模型。以点击率预估为例,首先收集样本。变量定义如下:
nums 表示收集样本的数量 。
(Xi,yi)表示用户第 个样本的数据,Xi表示样本的特征,yi表示点击情况(0表示没有点击,1表示点击)。
Yi 表示模型的预测值,是关于w,b的变量。
定义交叉熵损失函数:
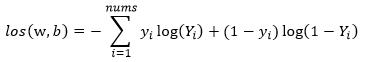
通过梯度下降法求解los(w,b)最小时对应的w,b即为所求模型参数。
3、业务实践
LR算法在目前推荐系统业界中,流行的做法是大规模离散化特征(one-hot编码),然后带入LR模型,以广告点击率模型为例,步骤如下:
Step1:构造用户画像
按照特征类别构造用户画像,对类别下面的所有特征进行离散化处理,例如:用户历史浏览物品记录,用户社会属性,通过模型给用户打的标签等等。
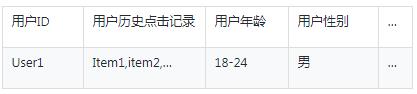
表:用户画像
Step2:构造物品画像
构造物品画像,同样也是需要划分物品特征类别,类别下面特征离散化处理,例如:物品ID,物品标签,物品热度等等。

表:用户画像
Step3:构造场景画像
在实际的业务实践中,往往是一个模型需要用到多个场景,不同场景物品的平均点击率差别很大,为了更好地解决不同场景平均点击率不同的问题,往往需要加上场景特征。场景画像一般只有场景ID,在某些特殊场景(例如:搜索列表)可以加上位置信息。

表:场景画像
Step4:收集样本数据
收集历史曝光点击数据,收集的数据维度包括:用户ID,物品ID,场景ID,是否点击。然后关联用户画像和物品画像得到模型的训练样本数据。

表:样本数据
Step5:构造模型特征
通过对样本数据构造模型特征得到模型的输入,模型特征分两类,一类是交叉特征,另一类是原始特征。
交叉特征:选择用户的类别特征、选择物品的类别特征、场景ID做三个维度的交叉,例如:用户历史点击记录为item1,item2 , 物品的ID特征为I1,场景特征为scene1,那么生成的交叉特征为item1&I1&scene1,item2&I1&scene1。
原始特征:原始特征是指直接把画像特征作为模型的输入特征,一般是把物品的泛化特征作为原始特征,用于物品冷启动特征或场景冷启动特征,例如:物品的CTR、物品的热度、物品的标签等等。
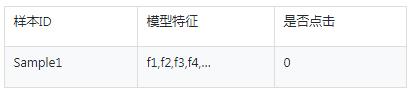
表:模型输入
Step6:模型训练
把模型中的所有特征进行one-hot编码,假设模型特征数为N,首先给每个模型特征一个唯一1-N的编码,那么每个样本的模型输入向量是维度为N取值0/1的向量 ,0表示该样本具备对应编号的特征,1表示没有,例如:样本1的具有有编号为1和编号为3的特征,那么样本1的模型输入向量为(1,0,1,0,0,…),然后通过通用的LR训练器训练模型,即可把模型的参数训练出来。
Step7:模型使用
给定一个用户u,及一批候选物品,对用户u如何推荐物品。通过上述方法计算用户u对候选集中每个物品的模型得分,按照模型得分降序推荐给用户。
「 更多干货,更多收获 」
智能推荐 个性化推荐技术与产品社区 |
长按并识别关注 |
以上是关于推荐算法基于LR的推荐算法的主要内容,如果未能解决你的问题,请参考以下文章