目标检测101:一文带你读懂深度学习框架下的目标检测
Posted 大数据文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测101:一文带你读懂深度学习框架下的目标检测相关的知识,希望对你有一定的参考价值。
大数据文摘作品
编译:及子龙,张礼俊
余志文,钱天培
从简单的图像分类到3D位置估算,在机器视觉领域里从来都不乏有趣的问题。其中我们最感兴趣的问题之一就是目标检测。
如同其他的机器视觉问题一样,目标检测目前为止还没有公认最好的解决方法。在了解目标检测之前,让我们先快速地了解一下这个领域里普遍存在的一些问题。
在计算机视觉领域中,最为人所知的问题便是图像分类问题。
图像分类是把一幅图片分成多种类别中的一类。
ImageNet是在学术界使用的最受欢迎的数据集之一,它由数百万个已分类图像组成,部分数据用于ImageNet大规模视觉识别挑战赛(ILSVRC)。 最近几年来,解决分类问题的模型已经有了超越人类的识别能力,所以分类问题实际上已经被解决了.
然而,图像分类问题有许多挑战,相伴随着的是许多如何解决这些问题的文献以及对还未被解决的问题的探讨。
 图像分类实例
图像分类实例
1目标定位
同图像分类类似,目标定位要找到单个目标在图像中的位置。 目标定位实例
目标定位实例
目标定位在实际生活中的应用很广泛,比如,智能剪切(通过定位目标所在的位置,识别需要图片从哪里剪切) ,或者进行常规的目标提取以便进一步处理。结合图像分类技术,它不仅仅可以定位目标,还能对该物体分类。
2实例分割
从目标检测更进一步,我们不仅仅要找到图片中的对象,更是要发现该检测对象对应的像素码。我们把这个问题称为实例分割,或者是对象分割。
3目标检测
在迭代处理定位和图片分类问题时,我们最终还是需要对多个目标进行同时检测和分类。目标检测是在图片中对可变数量的目标进行查找和分类。其中重要的区别是“可变”这一部分。
和图像分类问题不同的是,由于每一张图片待检测目标的数量不一,目标检测的输出长度是可变的。在这篇文章中,我们将详细地介绍一些实际应用,讨论目标检测作为机器学习问题的主要困难,以及在过去的几年里如何应用深度学习处理目标检测。 目标检测实例
目标检测实例
1人脸检测
自20世纪中期以来,傻瓜相机开始通过更为高效的自动对焦来检测人面。 虽然这是一种比较浅显的目标检测应用,但是这种方法同样适用于其他类型的目标检测,我们稍后将会介绍。
2计数
计数是一个简单但是经常被忽略的目标检测问题。统计人,车,花甚至是微生物数量是现实世界的需求,在大部分基于图像的系统中都要使用。近几年伴随着监控视频设备的不断涌现,使用机器视觉将原图像转化为结构化数据的需求也越来越多。
3视觉搜索引擎
最后,我们比较喜欢的一个实例是Pinterest(图片社交平台)的视觉搜索引擎。
他们将目标检测作为索引图像内容的处理流程之一。比如,你可以在不同的背景下找到某个特定的钱包。 这比Google Image的反向搜索引擎只是找到类似的图像更强大。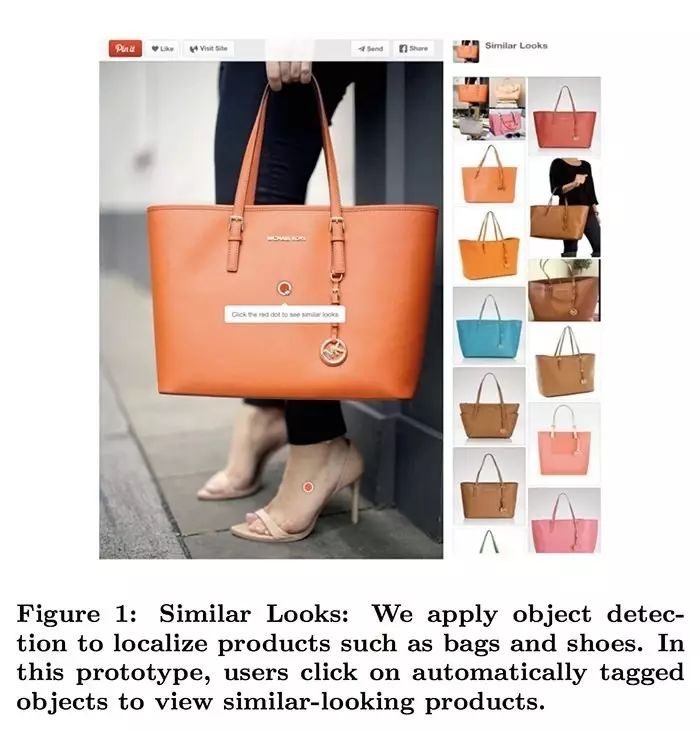 图1:相似查找:我们应用目标检测方法定位包或鞋子这些产品。在这张图片中, 用户可以点击图片中的目标对象便可以查找类似的产品。
图1:相似查找:我们应用目标检测方法定位包或鞋子这些产品。在这张图片中, 用户可以点击图片中的目标对象便可以查找类似的产品。
4空中影像分析
在这个廉价无人机和卫星兴起的年代,我们能在空中获取空前多的关于地球的数据。 如今已经有越来越多的公司开始使用planet 或者descartes labs 公司提供的卫星图片,应用目标检测来计算汽车,树,船的数量。这些举措都为我们带来了高质量的数据,这在从前是不可能实现的。
一些公司正在应用无人机摄像对人难以到达的地方进行自动监测(例如BetterView)或者使用物体检测方法进行整体分析(例如TensorFlight)。 除此之外,一些公司实现了不需人为干预下的场景自动检测和位置识别。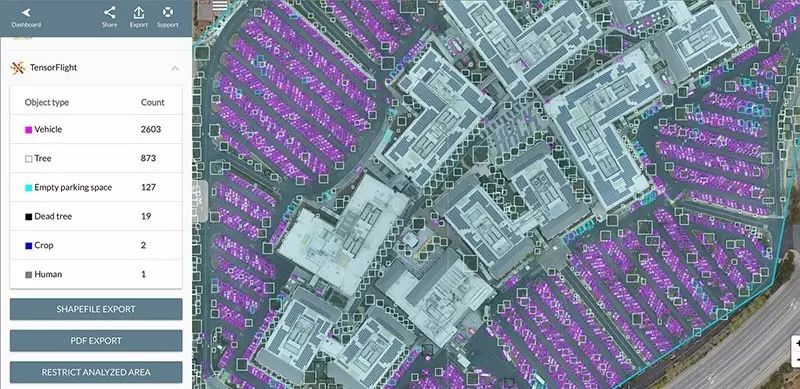 使用TensorFlight实现汽车、树和行人的识别
使用TensorFlight实现汽车、树和行人的识别
现在,让我们开始深入了解目标检测中的主要问题。
1对象数量不确定
我们在前面提到过对象数量可变,但是并没有解释为什么是个问题。当训练机器学习模型的时候,你经常需要把数据表示成固定长度的向量。如果在训练之前图片中的对象数量是未知的,模型的输出数量也就是未知的了。因此,一些增加模型复杂性的预处理是必要的。
在传统的方法中,输出的数量可以使用滑动窗函数来计算,给不同位置产生一个固定大小的特征窗。在做完了预测之后,有些预测会被丢弃,有些会被合并到最终结果里面。

滑动窗示例
2对象大小不同
另外一个挑战是处理不同大小对象的问题。面对一个简单的分类问题,你期望是尽可能将覆盖图片大部分面积的对象进行分类。而在有些情境中,你想识别的对象可能只有几十个像素点大小(或者说是原图片中占比很小的一部分)。以往人们通过使用不同大小的滑动窗来解决这个问题,这种方法虽然简单,却效率低下。
3建模
第三个挑战是同时解决目标定位和图像分类这两个问题。 我们如何将这两种不同类型的需求组合到一个模型里呢?
在进入深度学习和如何应对这些挑战之前,让我们先快速了解一些经典的检测方法。
1传统方法
在这里我们将集中介绍其中两个最流行且目前依然被广泛使用的模型。
第一个是2001年由Paul Viola和Michael Jones在论文《Robust Real-time Object Detection》里提出 的Viola-Jones框架。这个方法快速且相对简单,使得低处理能力的傻瓜相机得以进行实时的面部识别。
我们不打算深入介绍它是如何工作和训练的,但是总体来说,该算法是通过使用哈尔特征(Haar features)生成许多(可能几千个)简单的二元分类器来实现的。这些分类器通过一个多尺度级联滑动窗进行评估,一旦遇到错误的分类结果则提前结束。
2深度学习方法
在机器学习领域,深度学习一直是个大boss,尤其在计算机视觉方面。在图像分类的任务上,深度学习已经彻底击败了其他的传统模型。同样,在目标检测方面,深度学习也代表了目前的最先进水平。
读到这里,你应该对我们面临的挑战和对解决它们的办法有了一定的了解,接下来我们将概述一下在过去的几年深度学习方法的发展历程。
2013年由NYU(纽约大学) 提出的OverFeat 是最早将深度学习用于目标检测的方法之一。他们提出了一个使用卷积神经网络(CNNs)来处理多尺度滑窗的算法。
2013年由NYU(纽约大学) 提出的OverFeat 是最早将深度学习用于目标检测的方法之一。他们提出了一个使用卷积神经网络(CNNs)来处理多尺度滑窗的算法。
OverFeat提出后不久,加州大学伯克利分校的Ross Girshick及其同事就发表了Regins with CNN features,简称R-CNN的方法,该方法在物体识别挑战中有50%的效果提升。
他们提出了目标检测分三步走的方法:
•使用候选区域方法(最流行的一个是’Selective Search’)提取可能的物体
•使用CNN从每一个区域提取特征
•使用支持向量机(SVM)分类每一个区域
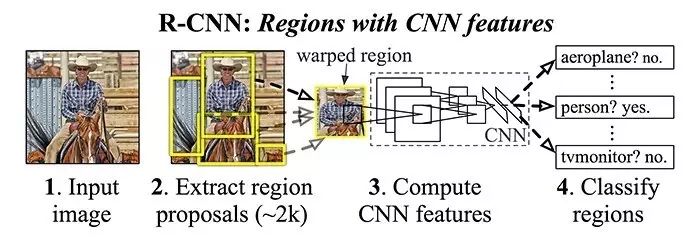 R-CNN架构
R-CNN架构
Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." 2014.
尽管R-CNN能达到很好的识别效果,但是它在训练中有很多的问题。
为了训练模型,你首先要对训练数据集产生候选区域,然后把CNN特征提取应用于每一个区域(对于Pascal 2012数据集通常需要处理200GB的数据),最后再训练支持向量机分类器。
和R-CNN类似,Fast R-CNN依然采用Selective Search生成候选区域,但是和之前的分别提取出所有的候选区域然后使用支持向量机分类器不同,Fast R-CNN 在完整的图片上使用CNN然后使用集中了特征映射的兴趣区域(Region of Interest, RoI),以及前向传播网络进行分类和回归。这个方法不仅更快,而且有Rol集中层和全连接层,使得模型从头到尾可求导,更容易训练。
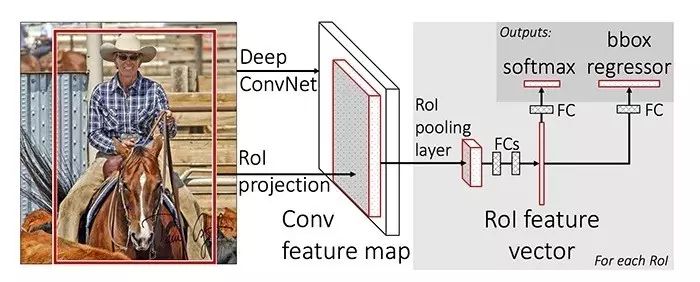 Fast R-CNN
Fast R-CNN
Girshick, Ross. "Fast R-CNN" 2015.
在Fast R-CNN被提出过后不久,Joseph Redmon(与Girshick等人合著)发表了You Only Look Once:Unified, Real-Time Object Detection(YOLO)这篇论文。
YOLO提出了一个兼具准确性和速度性的简单的卷积神经网络,首次实现了实时物体检测。
 YOLO架构
YOLO架构
Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." 2016.
接着,Shaoqing Ren(依然与Girshick合著,目前在Fackbook研究中心)发表了Faster R-CNN,这是R-CNN的第三次迭代。
Faster R-CNN添加了候选区域网络(Region Proposal Network, RPN),试图取消对Selective Search 算法的依赖,这使得模型可以完全实现端到端训练。
我们暂时不会详细深入地介绍RPNs的运行原理,但抽象地说,它基于一个叫“物体性”(objectness)的分数输出对象。这些物体被用在Rol集中层和全连接层,从而实现分类的目标。
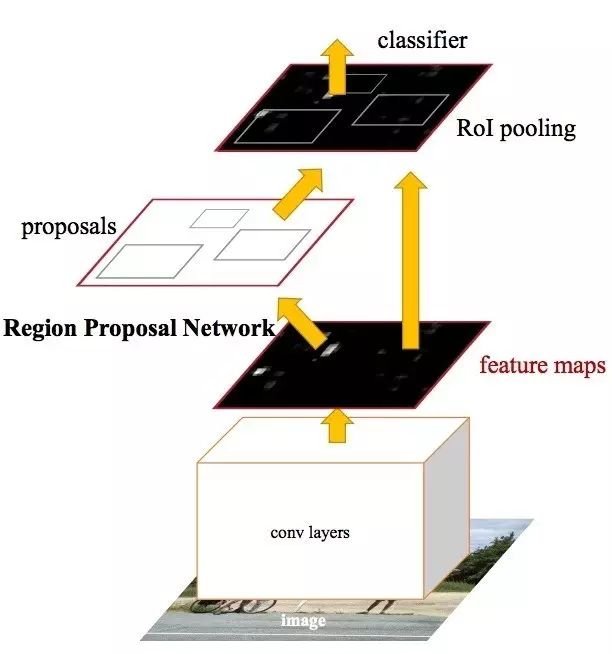 Faster R-CNN架构
Faster R-CNN架构
Ren, Shaoqing, et al. "Faster R-CNN: Towards real-time object detection with region proposal networks." 2015.
最后,还有两篇论文不得不提:Single Shot Detector(SSD) 和 Region-based Fully Convolutional Networks(R-FCN)。 前者在YOLO的基础上使用多尺寸的卷积特征图使得在结果和速度上都有提升。后者基于Faster R-CNN的架构,但是只使用了卷积网络。
数据集的重要性
在研究中,数据集扮演了十分重要的角色,其重要性经常被低估。每一次新的数据集发布,都会有论文被发表,新的模型在此基础上进行比对和提升,把不可能变成可能。
很可惜,对于目标检测,我们还没有足够的数据集。数据很难产生,而且成本很高,具备优秀数据库的公司一般不愿意公开他们的数据,而学校则无法接触到优质的数据集。
话虽如此,我们还是有一些不错的公开数据可以使用,下面的列表就是目前可用的主要数据集。
Name |
# Images (trainval) |
# Classes |
Last updated |
ImageNet |
450k |
200 |
2015 |
COCO |
120K |
80 |
2014 |
Pascal VOC |
12k |
20 |
2012 |
Oxford-IIIT Pet |
7K |
37 |
2012 |
KITTI Vision |
7K |
3 |
2014 |
结论
最后,在目标检测领域,还有很多未知的领域值得我们探索,不论是业界应用还是新型算法。尽管这篇文章只对目标检测作了简单的概述,我们依然希望它能帮助你初步了解目标检测这一领域,并为你更进一步的学习打下基础。
原文链接:https://tryolabs.com/blog/2017/08/30/object-detection-an-overview-in-the-age-of-deep-learning/




点击图片阅读
吴恩达导师Michael I. Jordan刚去清华手写版书讲了三天课,这有一份他的课程笔记
以上是关于目标检测101:一文带你读懂深度学习框架下的目标检测的主要内容,如果未能解决你的问题,请参考以下文章