资源 | 如何利用VGG-16等模型在CPU上测评各深度学习框架
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了资源 | 如何利用VGG-16等模型在CPU上测评各深度学习框架相关的知识,希望对你有一定的参考价值。
选自GitHub
机器之心编译
参与:蒋思源、刘晓坤
本项目对比了各深度学习框架在 CPU 上运行相同模型(VGG-16 和 MobileNet)单次迭代所需要的时间。作者提供了所有的测试代码,读者可以尝试测评以完善该结果。
在本项目中,作者测评了流行深度学习框架在 CPU 上的运行相同模型所需要的时间,作者采取测试的模型为 VGG-16 和 MobileNet。所有的测试代码都已经加入 Docker 文件,因此测试环境将很容易设置。目前这两个网络的参数都是随机生成的,因为我们只需要测试输入数据通过神经网络的测试时间。最后的结果并不能保证绝对正确,但作者希望能与我们共同测试并更新结果。
以下是该测试涉及的深度学习架构,
Caffe
Caffe2
Chainer
MxNet
TensorFlow
NNabla
对于这些深度学习框架,作者准备了多种安装设置,例如是否带有 MKL、pip 或 build。
安装与运行
因为我们将所有试验代码和环境都加入了 Docker 文件,所以我们需要下载 Dockerfile 并运行它。
$ docker build -t {NAME} .
$ docker run -it --rm {NAME}
在创建的 Docker 容器中,复制该 GitHub 项目的代码库并运行测试代码。
# git clone https://github.com/peisuke/dl_samples.git
# cd dl_samples/{FRAMEWORK}/vgg16
# python3 (or python) predict.py
当前结果
当前的结果还有很多误差,首先当前结果是模型在各个框架下的一个估计,例如第一项为单次迭代运行时间的样本均值,第二项为单次迭代时间的标准差。
从作者的测试代码可知,每一次迭代的运行时间采取的是 20 次迭代的均值,每一次迭代投入的都是批量为 1 的图片集。且每张图片都是维度为(224,224,3)的随机生成样本,且每一个生成的元素都服从正态分布。若再加上随机生成的权重,那么整个测试仅仅能测试各深度学习框架的在 CPU 上运行相同模型的时间。
以下分别展示了 20 次迭代(有点少)的平均运行时间和标准差,其中每种模型是否使用了 MKL 等 CPU 加速库也展示在结果中。
caffe(openblas, 1.0)
caffe-vgg-16 : 13.900894 (sd 0.416803)
caffe-mobilenet : 0.121934 (sd 0.007861)
caffe(mkl, 1.0)
caffe-vgg-16 : 3.005638 (sd 0.129965)
caffe-mobilenet: 0.044592 (sd 0.010633)
caffe2(1.0)
caffe2-vgg-16 : 1.351302 (sd 0.053903)
caffe2-mobilenet : 0.069122 (sd 0.003914)
caffe2(mkl, 1.0)
caffe2-vgg-16 : 0.526263 (sd 0.026561)
caffe2-mobilenet : 0.041188 (sd 0.007531)
mxnet(0.11)
mxnet-vgg-16 : 0.896940 (sd 0.258074)
mxnet-mobilenet : 0.209141 (sd 0.060472)
mxnet(mkl)
mxnet-vgg-16 : 0.176063 (sd 0.239229)
mxnet-mobilenet : 0.022441 (sd 0.018798)
pytorch
pytorch-vgg-16 : 0.477001 (sd 0.011902)
pytorch-mobilenet : 0.094431 (sd 0.008181)
nnabla
nnabla-vgg-16 : 1.472355 (sd 0.040928)
nnabla-mobilenet : 3.984539 (sd 0.018452)
tensorflow(pip, r1.3)
tensorflow-vgg-16 : 0.275986 (sd 0.009202)
tensorflow-mobilenet : 0.029405 (sd 0.004876)
tensorflow(opt, r1.3)
tensorflow-vgg-16 : 0.144360 (sd 0.009217)
tensorflow-mobilenet : 0.022406 (sd 0.007655)
tensorflow(opt, XLA, r1.3)
tensorflow-vgg-16 : 0.151689 (sd 0.006856)
tensorflow-mobilenet : 0.022838 (sd 0.007777)
tensorflow(mkl, r1.0)
tensorflow-vgg-16 : 0.163384 (sd 0.011794)
tensorflow-mobilenet : 0.034751 (sd 0.011750)
chainer(2.0)
chainer-vgg-16 : 0.497946 (sd 0.024975)
chainer-mobilenet : 0.120230 (sd 0.013276)
chainer(2.1, numpy with mkl)
chainer-vgg-16 : 0.329744 (sd 0.013079)
chainer-vgg-16 : 0.078193 (sd 0.017298)
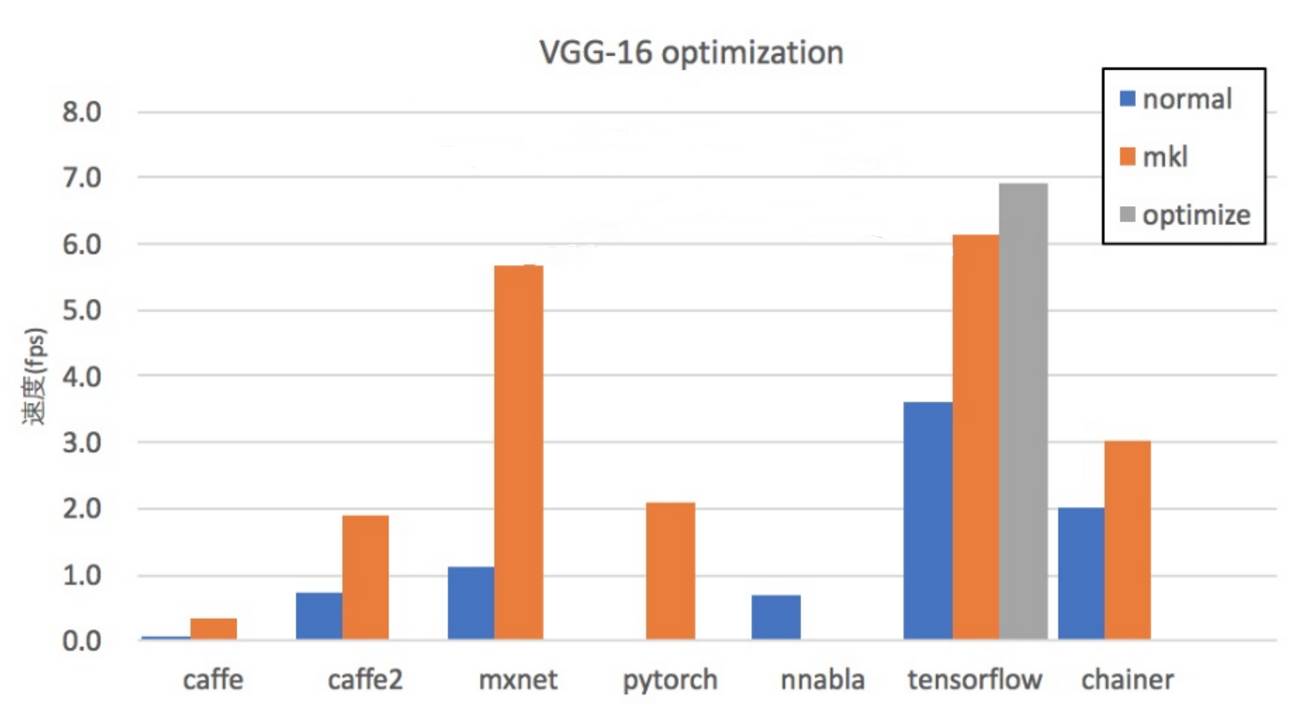
以下为各深度学习框架在 CPU 上执行 VGG-16 的平均运行速度,其中 TensorFlow 的单次迭代(批量大小为 1)平均速度较快:
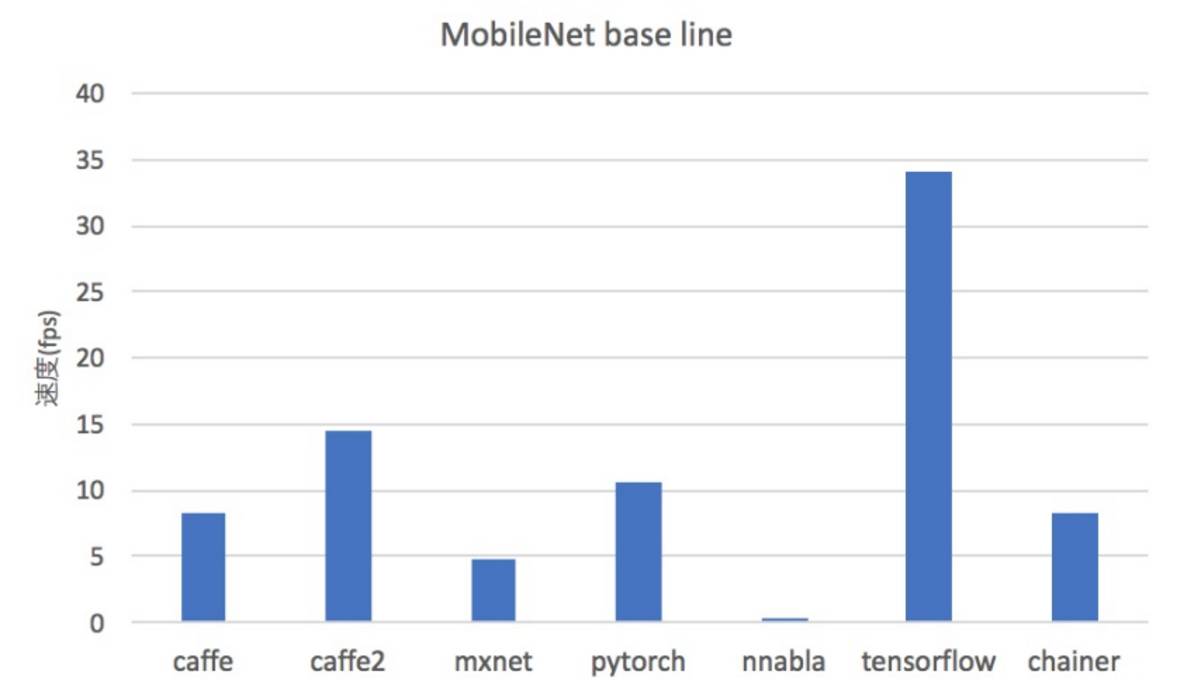
以下为 MobileNet 的单次迭代平均速度:
以下展示了不使用 MKL 等 CPU 加速库和使用时的速度区别,我们看到使用 MKL 加速库的各深度学习框架在平均迭代时间上有明显的降低。
以下展示了 MobileNet 的加速情况,令人惊讶的是 TensorFlow 使用 MKL CPU 加速库却令单次平均迭代时间增多了。
以上是作者在 CPU 上运行与测试各个深度学习框架的结果,其中我们还是用了 mkl 等 CPU 加速库。以下是作者使用的各个深度学习框架训练 VGG-16 和 MobileNet 的代码。
Caffe2/VGG-16
import numpy as np
import tqdm
import os
import shutil
import time
import caffe2.python.predictor.predictor_exporter as pe
from caffe2.python import core, model_helper, net_drawer, workspace, visualize, brew
core.GlobalInit(['caffe2', '--caffe2_log_level=0'])
def AddLeNetModel(model, data):
conv1_1 = brew.conv(model, data, 'conv1_1', dim_in=3, dim_out=64, kernel=3, pad=1)
conv1_1 = brew.relu(model, conv1_1, conv1_1)
conv1_2 = brew.conv(model, conv1_1, 'conv1_2', dim_in=64, dim_out=64, kernel=3, pad=1)
conv1_2 = brew.relu(model, conv1_2, conv1_2)
pool1 = brew.max_pool(model, conv1_2, 'pool1', kernel=2, stride=2)
conv2_1 = brew.conv(model, pool1, 'conv2_1', dim_in=64, dim_out=128, kernel=3, pad=1)
conv2_1 = brew.relu(model, conv2_1, conv2_1)
conv2_2 = brew.conv(model, conv2_1, 'conv2_2', dim_in=128, dim_out=128, kernel=3, pad=1)
conv2_2 = brew.relu(model, conv2_2, conv2_2)
pool2 = brew.max_pool(model, conv2_2, 'pool2', kernel=2, stride=2)
conv3_1 = brew.conv(model, pool2, 'conv3_1', dim_in=128, dim_out=256, kernel=3, pad=1)
conv3_1 = brew.relu(model, conv3_1, conv3_1)
conv3_2 = brew.conv(model, conv3_1, 'conv3_2', dim_in=256, dim_out=256, kernel=3, pad=1)
conv3_2 = brew.relu(model, conv3_2, conv3_2)
conv3_3 = brew.conv(model, conv3_2, 'conv3_3', dim_in=256, dim_out=256, kernel=3, pad=1)
conv3_3 = brew.relu(model, conv3_3, conv3_3)
pool3 = brew.max_pool(model, conv3_3, 'pool3', kernel=2, stride=2)
conv4_1 = brew.conv(model, pool3, 'conv4_1', dim_in=256, dim_out=512, kernel=3, pad=1)
conv4_1 = brew.relu(model, conv4_1, conv4_1)
conv4_2 = brew.conv(model, conv4_1, 'conv4_2', dim_in=512, dim_out=512, kernel=3, pad=1)
conv4_2 = brew.relu(model, conv4_2, conv4_2)
conv4_3 = brew.conv(model, conv4_2, 'conv4_3', dim_in=512, dim_out=512, kernel=3, pad=1)
conv4_3 = brew.relu(model, conv4_3, conv4_3)
pool4 = brew.max_pool(model, conv4_3, 'pool4', kernel=2, stride=2)
conv5_1 = brew.conv(model, pool4, 'conv5_1', dim_in=512, dim_out=512, kernel=3, pad=1)
conv5_1 = brew.relu(model, conv5_1, conv5_1)
conv5_2 = brew.conv(model, conv5_1, 'conv5_2', dim_in=512, dim_out=512, kernel=3, pad=1)
conv5_2 = brew.relu(model, conv5_2, conv5_2)
conv5_3 = brew.conv(model, conv5_2, 'conv5_3', dim_in=512, dim_out=512, kernel=3, pad=1)
conv5_3 = brew.relu(model, conv5_3, conv5_3)
pool5 = brew.max_pool(model, conv5_3, 'pool5', kernel=2, stride=2)
fc6 = brew.fc(model, pool5, 'fc6', dim_in=25088, dim_out=4096)
fc6 = brew.relu(model, fc6, fc6)
fc7 = brew.fc(model, fc6, 'fc7', dim_in=4096, dim_out=4096)
fc7 = brew.relu(model, fc7, fc7)
pred = brew.fc(model, fc7, 'pred', 4096, 1000)
softmax = brew.softmax(model, pred, 'softmax')
return softmax
model = model_helper.ModelHelper(name="vgg", init_params=True)
softmax = AddLeNetModel(model, "data")
workspace.RunNetOnce(model.param_init_net)
data = np.zeros([1, 3, 224, 224], np.float32)
workspace.FeedBlob("data", data)
workspace.CreateNet(model.net)
nb_itr = 20
timings = []
for i in tqdm.tqdm(range(nb_itr)):
data = np.random.randn(1, 3, 224, 224).astype(np.float32)
start_time = time.time()
workspace.FeedBlob("data", data)
workspace.RunNet(model.net.Proto().name)
ref_out = workspace.FetchBlob("softmax")
timings.append(time.time() - start_time)
print('%10s : %f (sd %f)'% ('caffe2-vgg-16', np.array(timings).mean(), np.array(timings).std()))
MXNet/MobileNet
import numpy as np
import os
import gzip
import struct
import time
import tqdm
from collections import namedtuple
import mxnet as mx
def conv_bn(inputs, oup, stride, name):
conv = mx.symbol.Convolution(name=name, data=inputs, num_filter=oup, pad=(1, 1), kernel=(3, 3), stride=(stride, stride), no_bias=True)
conv_bn = mx.symbol.BatchNorm(name=name+'_bn', data=conv, fix_gamma=False, eps=0.000100)
out = mx.symbol.Activation(name=name+'relu', data=conv_bn, act_type='relu')
return out
def conv_dw(inputs, inp, oup, stride, name):
conv_dw = mx.symbol.Convolution(name=name+'_dw', data=inputs, num_filter=inp, pad=(1, 1), kernel=(3, 3), stride=(stride, stride), no_bias=True, num_group=inp)
conv_dw_bn = mx.symbol.BatchNorm(name=name+'dw_bn', data=conv_dw, fix_gamma=False, eps=0.000100)
out1 = mx.symbol.Activation(name=name+'_dw', data=conv_dw_bn, act_type='relu')
conv_sep = mx.symbol.Convolution(name=name+'_sep', data=out1, num_filter=oup, pad=(0, 0), kernel=(1,1), stride=(1,1), no_bias=True)
conv_sep_bn = mx.symbol.BatchNorm(name=name+'_sep_bn', data=conv_sep, fix_gamma=False, eps=0.000100)
out2 = mx.symbol.Activation(name=name+'_sep', data=conv_sep_bn, act_type='relu')
return out2
def create_network():
data = mx.sym.Variable('data')
net = conv_bn(data, 32, stride=2, name='conv_bn')
net = conv_dw(net, 32, 64, stride=1, name='conv_ds_2')
net = conv_dw(net, 64, 128, stride=2, name='conv_ds_3')
net = conv_dw(net, 128, 128, stride=1, name='conv_ds_4')
net = conv_dw(net, 128, 256, stride=2, name='conv_ds_5')
net = conv_dw(net, 256, 256, stride=1, name='conv_ds_6')
net = conv_dw(net, 256, 512, stride=2, name='conv_ds_7')
net = conv_dw(net, 512, 512, stride=1, name='conv_ds_8')
net = conv_dw(net, 512, 512, stride=1, name='conv_ds_9')
net = conv_dw(net, 512, 512, stride=1, name='conv_ds_10')
net = conv_dw(net, 512, 512, stride=1, name='conv_ds_11')
net = conv_dw(net, 512, 512, stride=1, name='conv_ds_12')
net = conv_dw(net, 512, 1024, stride=2, name='conv_ds_13')
net = conv_dw(net, 1024, 1024, stride=1, name='conv_ds_14')
net = mx.symbol.Pooling(data=net, global_pool=True, kernel=(7, 7), pool_type='avg', name='pool1')
return mx.sym.softmax(net)
mlp = create_network()
mod = mx.mod.Module(symbol=mlp, context=mx.cpu(), label_names=None)
mod.bind(data_shapes=[('data', (1, 3, 224, 224))], for_training=False)
mod.init_params(initializer=mx.init.Xavier(magnitude=2.))
Batch = namedtuple('Batch', ['data'])
nb_itr = 20
timings = []
for i in tqdm.tqdm(range(nb_itr)):
data = np.random.randn(1, 3, 224, 224).astype(np.float32)
start_time = time.time()
batch = Batch([mx.nd.array(data)])
mod.forward(batch)
prob = mod.get_outputs()[0].asnumpy()
timings.append(time.time() - start_time)
print('%10s : %f (sd %f)'% ('mxnet-mobilenet', np.array(timings).mean(), np.array(timings).std()))
PyTorch/MobileNet
import numpy as np
import tqdm
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
def conv_dw(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
class MobileNet(nn.Module):
def __init__(self):
super(MobileNet, self).__init__()
self.model = nn.Sequential(
conv_bn( 3, 32, 2),
conv_dw( 32, 64, 1),
conv_dw( 64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
nn.AvgPool2d(7),
)
self.fc = nn.Linear(1024, 1000)
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return F.softmax(x)
model = MobileNet()
model.eval()
nb_itr = 20
timings = []
for i in tqdm.tqdm(range(nb_itr)):
data = np.random.randn(1, 3, 224, 224).astype(np.float32)
data = torch.from_numpy(data)
start_time = time.time()
data = Variable(data)
output = model(data)
timings.append(time.time() - start_time)
print('%10s : %f (sd %f)'% ('pytorch-mobilenet', np.array(timings).mean(), np.array(timings).std()))
MobileNet 模型的结构:
首先定义两个函数:
conv_bn:卷积、batch 归一化、ReLU;
conv_dw:卷积、batch 归一化、ReLU、卷积、batch 归一化、ReLU;
然后将网络经过 1 次 conv_bn 和 13 次 conv_dw 计算,和 1 次平均池化,最后使用 softmax 函数输出。
TensorFlow/VGG-16
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import tqdm
import time
def vgg(x):
conv1_1 = tf.layers.conv2d(x, 64, 3, padding='same', activation=tf.nn.relu)
conv1_2 = tf.layers.conv2d(conv1_1, 64, 3, padding='same', activation=tf.nn.relu)
pool1 = tf.layers.max_pooling2d(conv1_2, 2, 2)
conv2_1 = tf.layers.conv2d(pool1, 128, 3, padding='same', activation=tf.nn.relu)
conv2_2 = tf.layers.conv2d(conv2_1, 128, 3, padding='same', activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(conv2_2, 2, 2)
conv3_1 = tf.layers.conv2d(pool2, 256, 3, padding='same', activation=tf.nn.relu)
conv3_2 = tf.layers.conv2d(conv3_1, 256, 3, padding='same', activation=tf.nn.relu)
conv3_3 = tf.layers.conv2d(conv3_2, 256, 3, padding='same', activation=tf.nn.relu)
pool3 = tf.layers.max_pooling2d(conv3_3, 2, 2)
conv4_1 = tf.layers.conv2d(pool3, 512, 3, padding='same', activation=tf.nn.relu)
conv4_2 = tf.layers.conv2d(conv4_1, 512, 3, padding='same', activation=tf.nn.relu)
conv4_3 = tf.layers.conv2d(conv4_2, 512, 3, padding='same', activation=tf.nn.relu)
pool4 = tf.layers.max_pooling2d(conv4_3, 2, 2)
conv5_1 = tf.layers.conv2d(pool4, 512, 3, padding='same', activation=tf.nn.relu)
conv5_2 = tf.layers.conv2d(conv5_1, 512, 3, padding='same', activation=tf.nn.relu)
conv5_3 = tf.layers.conv2d(conv5_2, 512, 3, padding='same', activation=tf.nn.relu)
pool5 = tf.layers.max_pooling2d(conv5_3, 2, 2)
flat5 = tf.contrib.layers.flatten(pool5)
d1 = tf.layers.dense(flat5, 4096)
d2 = tf.layers.dense(d1, 4096)
out = tf.layers.dense(d2, 1000)
return tf.nn.softmax(out)
# tf Graph input
X = tf.placeholder("float", [None, 224, 224, 3])
Y = vgg(X)
init = tf.initialize_all_variables()
config = tf.ConfigProto()
config.graph_options.optimizer_options.global_jit_level = tf.OptimizerOptions.ON_1
sess = tf.Session(config=config)
sess.run(init)
nb_itr = 20
timings = []
for i in tqdm.tqdm(range(nb_itr)):
batch_xs = np.random.randn(1, 224, 224, 3).astype(np.float32)
start_time = time.time()
ret = sess.run(Y, feed_dict={X: batch_xs})
timings.append(time.time() - start_time)
print('%10s : %f (sd %f)'% ('tensorflow-vgg-16', np.array(timings).mean(), np.array(timings).std()))
VGG-16 模型的结构:
2 个卷积层,1 个池化层;
2 个卷积层,1 个池化层;
3 个卷积层,1 个池化层;
3 个卷积层,1 个池化层;
3 个卷积层,1 个池化层;
1 个 flatten 层;
然后是 1 个 3 层全连接神经网络;
最后用 softmax 函数输出。
激活函数都是 ReLU 函数。
和 TensorFlow 相比,PyTorch 由于不需要定义计算图,非常接近 Python 的使用体验,其函数的定义过程和模型运算要简洁得多,代码格式也更加清晰明了。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
以上是关于资源 | 如何利用VGG-16等模型在CPU上测评各深度学习框架的主要内容,如果未能解决你的问题,请参考以下文章