AWS CTO:解读首选 MXNet 做为 AWS 的深度学习框架的原因
Posted 云头条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AWS CTO:解读首选 MXNet 做为 AWS 的深度学习框架的原因相关的知识,希望对你有一定的参考价值。
机器学习在我们的生意和生活中的许多方面扮演着越来越重要的角色,应用于编写显式算法行不通的众多计算任务。
在亚马逊,机器学习一向是我们许多业务流程的关键,从商品推荐到欺诈检测,从库存数量、图书分类再到恶意评价检测。我们还在多得多的应用领域广泛使用机器学习:搜索、自动驾驶无人机、订单履行中心的机器人、文本及语音识别等。
在机器学习算法当中,名为深度学习的一类算法已逐渐代表这种算法:能够获取大量数据,了解这些数据当中蕴含的优雅、实用的模式:照片里面的脸庞、文本的含义或口语的意图。已出现了一系列编程模型,可帮助开发人员借助深度学习来定义和训练人工智能算法;还出现了一系列开源框架,将深度学习交到更多普通人的手里。我们在AWS上支持的流行的深度学习框架的几个例子包括:Caffe、CNTK、MXNet、TensorFlow、Theano和Torch。
我们得出了结论,在所有这些流行的框架当中,MXNet是可扩展性最强的框架。我们认为,人工智能社区将得益于投入更多的精力来支持MXNet。今天我们宣布,MXNet将是我们首选的深度学习框架。除了致力于打造MXNet方面的生态系统外,AWS还将贡献代码和更完备的说明文档。我们会与其他企业组织达成合作伙伴关系,进一步推进MXNet。
AWS及对深度学习框架的支持
在AWS,我们坚信为客户提供选择的道理。我们的目的是,通过提供一系列合适的实例、软件(AMI)和托管服务,利用我们的客户自行选择的工具、系统和软件,支持他们。就像在亚马逊RDS中那样――我们支持多种开源引擎,比如mysql、PostgreSQL和MariaDB,在深度学习框架这个方面,我们支持所有流行的深度学习框架,为此提供一系列最出色的EC2实例和适合他们的软件工具。
亚马逊EC2拥有一系列广泛的实例类型和GPU,还拥有大量内存,它已成为深度学习训练的重心。为此,我们为客户最近提供了一系列工具,以便尽可能容易地开始入手:深度学习AMI(Deep Learning AMI)预先安装上述流行的开源深度学习框架;GPU加速机制,可通过已经安装的CUDA驱动程序来享用,预先配置,随时可以运行;还有Anaconda和Jupyter之类的支持性工具。开发人员还可以使用分布式深度学习CloudFormation模块,使用这个AMI,为更庞大的训练任务启动一个横向扩展的、具有弹性的P2实例集群。
由于亚马逊和AWS继续致力于基于深度学习的几项技术,我们会继续在易用性、可扩展性和功能特性等方面改进所有这些框架。然而,我们计划尤其大大改进MXNet这一种框架。
选择一种深度学习框架
开发人员、数据科学家和研究人员在选择一种深度学习框架时考虑三个重要的因素:
扩展能力,可以扩展到多个GPU(跨多个主机),以便使用更庞大、更复杂的数据集,训练更庞大、更复杂的模型。深度学习模型可能需要几天或几周的时间来训练,所以这方面即便很小的改进,对于开发和评估新模型的速度也会大有影响。
开发速度和可编程性,尤其是使用他们已经熟悉的语言这一机会,那样他们就能迅速构建新模型,并更新现有模型。
在众多设备和平台上运行的可移植性,因为深度学习模型不得不在许许多多不同的地方运行:从拥有出色网络和大量计算能力的笔记本电脑和服务器集群,到常常位于边远地方,网络不太可靠,计算能力弱得多的移动设备和联网设备,不一而足。
同样这三个因素对AWS及我们许多客户的开发人员来说也很重要。经过认真评估后,我们选择了MXNet作为我们的首选深度学习框架,我们打算把它广泛用于现有的服务和即将推出的新服务。
作为这个承诺的一部分,我们将积极通过贡献代码来倡导和支持开源开发(我们已经贡献了不少的代码),改善开发者体验以及网上和AWS上的说明文档,并致力于研发可视化、开发以及迁离其他框架迁移所需的支持工具。
MXNet方面的背景
MXNet是一种功能全面、可灵活编程、可扩展性超强的深度学习框架,支持最先进的深度学习模型,包括卷积神经网络(CNN)和长短期记忆网络(LSTM)。MXNet根源于学术界,它是几家知名大学的研究人员的合作和贡献的结晶。创始组织包括华盛顿大学和卡内基·梅隆大学。
卡内基·梅隆大学计算机学系主任安德鲁·摩尔(Andrew Moore)说:“MXNet诞生于卡内基·梅隆大学,是我见过的可扩展性最强的深度学习框架,这个典例表明了什么使计算机学的这个领域如此有魅力――不同的学科都非常完美地协同起来:富有想象力的线性代数以一种新颖的方式工作,大规模分布式计算为深度学习带来了一种全新的局面。亚马逊致力于MXNet让我们为之激动,迫不及待地想看到MXNet变得日臻完善。”
扩展MXNet
深度学习框架跨多个处理器核心横向扩展的效率是它的关键特点之一。更高效的扩展让你得以大幅提高训练新模型的速度,或者在同样的训练时间内显著提高模型的精准性。
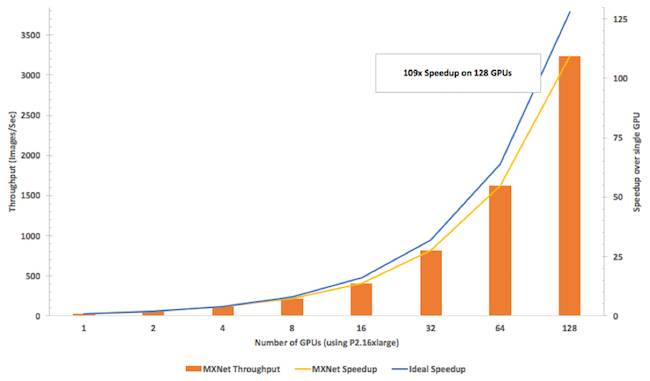
这正是MXNet大放异彩的一个方面:我们训练了一种流行的图像分析算法Inception v3(用MXNet实现,在P2实例上运行),使用越来越多的GPU。MXNet不仅拥有我们评估的任何库中最高的吞吐量(以每秒训练的图像数量来衡量),而且吞吐量提升的速度与用于训练的GPU数量增加的速度几乎一样快(扩展效率达到了85%)。
用MXNet来开发
除了可扩展性外,MXNet不仅能够混合多种编程模型(命令式和声明式编程模型),还能够用一系列广泛的编程语言来编写代码,包括Python、C++、R、Scala、Julia、Matlab和javascript。
MXNet的高效模型和可移植性
计算效率很重要(与可扩展性紧密相关),但是几乎同样重要的是内存占用空间(memory footprint)。在服务于拥有多达1000层的深度网络时,MXNet占用的内存仅为4GB。它还可以在多个平台上移植,核心库(以及所有依赖项)都可以装入到单单一个C++源文件中,可以针对android和ios进行编译。你甚至可以使用JavaScript扩展,在浏览器里面运行它!
了解MXNet的更多信息
我们为MXNet而感到激动。如果你想了解更多的信息,可以访问MXNet主页(http://mxnet.io)或GitHub代码库(https://github.com/dmlc/mxnet),了解更多信息,现在就可以入手,使用深度学习AMI,也可以在自己的机器上入手。我们还将在11月30日于拉斯维加斯美丽华酒店召开的AWS re:Invent大会上,主办机器学习“国情咨文”(https://www.portal.reinvent.awsevents.com/connect/sessionDetail.ww?SESSION_ID=10748)和一系列分会及研讨会,介绍使用MXNet方面的情况。
注这个新的机器智能时代而言,现在仍是起步阶段。实际上,我们可能还没有迈出头一步。借助MXNet之类的工具(以及其他深度学习框架),还有EC2之类的服务,将来会是一个激动人心的时期。
云头条编译|未经授权谢绝转载
欢迎加入交流,群主微信:aclood
相关阅读:
以上是关于AWS CTO:解读首选 MXNet 做为 AWS 的深度学习框架的原因的主要内容,如果未能解决你的问题,请参考以下文章
AWS发布深度学习框架MXNet 1.0.0版本,新功能将简化深度学习训练
预告 | MXNet对TensorFlow的挑战——地平线对话亚马逊AWS
会员资讯 | MXNet对TensorFlow的挑战——地平线对话亚马逊AWS
将经过训练的 AWS SageMaker MXNet 模型部署/转换到 iOS 设备