深度学习框架源码解读-ch0-talk is cheap
Posted 黑客与画家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习框架源码解读-ch0-talk is cheap相关的知识,希望对你有一定的参考价值。
为什么要做源码解读系列?
Talk is cheap. Show me the code.
小张意识到,微信上的 DL 文章转发再多都是学不会 DL 的,作为工程师,必须得读源代码。DL 的开源框架有很多,出名的有:
Caffe,C++
Torch,Lua
Theano,Python
出于对 C++ 的信仰,小张第一时间选择了 Caffe
git clone https://github.com/BVLC/caffe.git
马上就后悔了,依赖的第三方库过多(这一点原作者 贾扬清 也承认了),适合拿来用,但不适合 hack 和阅读理解,同时官方版本不支持 Windows,Visual Studio 党完全无法接受。
幸好,Princeton 大学发布了 Marvin,这个名字是双关,既是《银河系漫游指南》中的忧郁机器人,也是人工智能之父 Marvin Minsky。
Marvin 是一个基于 CUDA 和 C++ 的深度学习框架,和 Caffe 相比它有以下优点:
代码结构简单直接,方便原型开发
没有复杂的 C++ 语法技巧
GPU-only,代码更少,不再需要写上一堆抽象类,CPU 和 GPU 各实现一次。
除了 CUDA 和 CUDNN 外不依赖任何第三方库,用 N 卡做深度学习,这两个库是必备的:)
git clone
整个框架的核心代码只有两个文件 marvin.cu 和 marvin.hpp。
神经网络 101,class Net{}
在贴大段大段的代码之前稍微介绍下什么是神经网络。
神经网络中是由很多层(layer)组成的,layer 是对输入数据的操作。
下图的 layer 输出的运算结果 y 是 x1 * w1 + x2 * w2 + x3 * w3 + 1 * b
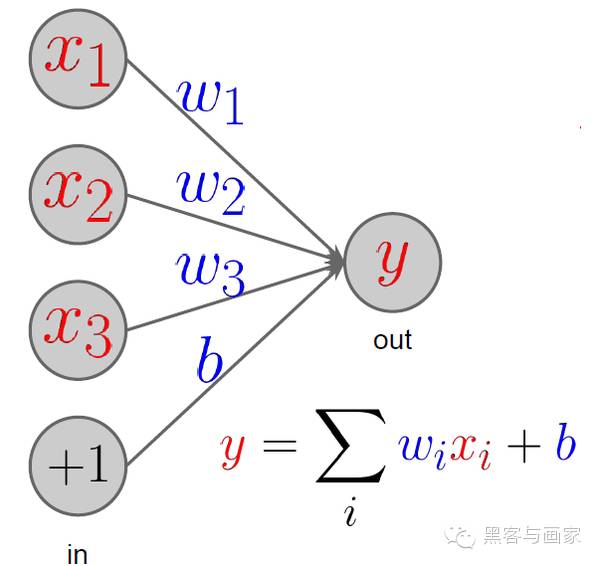
layer 的输入(X)和输出(y)被称为响应(Response)。

layer 有许多其他形式,Marvin 中预设的有:
DataLayer,负责提供原始数据给神经网络,包括 TensorLayer、MemoryDataLayer 以及 DiskDataLayer。
ConvolutionLayer
InnerProductLayer
DropoutLayer
SoftmaxLayer
ActivationLayer
PoolingLayer
LRNLayer
ReshapeLayer
ROIPoolingLayer
ROILayer
ElementWiseLayer
ConcatLayer
LossLayer
这些 layer 的功能及代码实现将在后续文章中一一介绍。我们先看下最重要的 Net 类包括什么成员变量:
class Net {
public: Phase phase; std::vector<Layer*> layers; std::vector<Response*> responses; std::vector<LossLayer*> loss_layers; int GPU; bool debug_mode; int train_iter; int test_iter; cudnnHandle_t cudnnHandle; cublasHandle_t cublasHandle;
...
};结合下图的神经网络,Net::layers 变量保存所有的层,即图片中的箭头 。Net::responses 对应的是圆圈。DataLayer 是第一层的类型,负责读取磁盘或内存中的图片,并将数据转化为 Marvin 可以理解的内部格式(这种格式叫 Tensor,即 N 维数组,以后会讲)。这个网络的最终输出为两个0 ~ 1之间的浮点数,表示网络认为输入的图片是 cat 的概率以及 not cat 的概率。这个例子中 cat 的值为 0.9,表示很像猫。
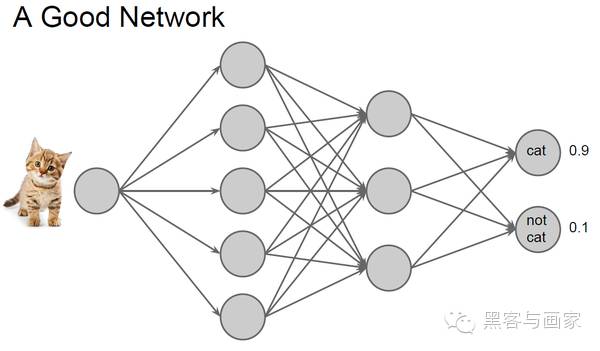
但是,并不是每个网络都这么智能,比如这位 ,居然认为这不是一只猫。
对此,我们需要结合网络输出的结果(Network Output)和真实的训练数据(Ground Truth),对没有达标的网络进行惩罚。通过这种惩罚机制,使得网络的输出结果接近训练数据。我们的目标是对所有的训练图片,最小化惩罚值。这正是 Net::loss_layers 存在的意义。
今天的专栏就到这里,休息,休息一会。
以上是关于深度学习框架源码解读-ch0-talk is cheap的主要内容,如果未能解决你的问题,请参考以下文章
Spark Streaming源码解读之Job动态生成和深度思考
解读对比13个深度学习框架后的选择——专访TensorFlow贡献者黄文坚