腾讯优图开放手机端深度学习框架,无第三方库依赖,可跨平台使用
Posted AI大事件
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯优图开放手机端深度学习框架,无第三方库依赖,可跨平台使用相关的知识,希望对你有一定的参考价值。
据资料介绍,ncnn 是一个为手机端极致优化的高性能神经网络前向计算框架。ncnn 从设计之初深刻考虑手机端的部属和使用。无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 APP。
深度学习算法要在手机上落地,现成的 caffe-android-lib 项目依赖太多,手机上基本不支持 cuda,需要个又快又小的前向网络实现。单纯的精简 caffe 等框架依然无法满足手机 APP 对安装包大小,运算速度等的苛刻要求。
在作者的严谨分析后,认为只有全部从零开始设计才能做出适合移动端的前向网络实现,因此从最初的架构设计以手机端运行为主要原则,考虑了手机端的硬件和系统差异以及调用方式。经过一年多的持续开发,基本实现了卷积神经网络的所有特性,精细调优后的效率领先目前一切已知的开源框架。
据了解,ncnn 目前已在腾讯许多 APP 中使用,经过大量的实践测试,稳定性很好。作为腾讯对开源社区的贡献,希望能为人工智能的发展助力,将更多的深度学习研究成果落地到用户跟前,提升人类生活品质。
| 对比 | Caffe | TensorFlow | ncnn | CoreML |
|---|---|---|---|---|
| 计算硬件 | CPU | CPU | CPU | GPU |
| 是否开源 | 是 | 是 | 是 | 否 |
| 手机计算速度 | 慢 | 慢 | 很快 | 极快 |
| 手机库大小 | 大 | 较大 | 小 | 小 |
| 手机兼容性 | 好 | 好 | 很好 | 仅支持 ios11 |
对比目前已知的同类框架,ncnn 是 cpu 框架中最快的,安装包体积最小,跨平台兼容性中也是最好的。CoreML 是苹果主推的 iOS gpu 计算框架,速度非常快,但仅支持 iOS 11 以上的 iphone 手机,落地受众太狭窄,非开源导致开发者无法自主扩展功能,对开源社区不友好。
以下内容为 ncnn 的十大主要功能的介绍。
ncnn 支持卷积神经网络结构,以及多分支多输入的复杂网络结构,如主流的 vgg、googlenet、resnet、squeezenet 等。
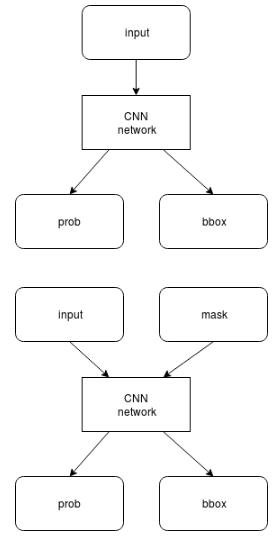
计算时可以依据需求,先计算公共部分和 prob 分支,待 prob 结果超过阈值后,再计算 bbox 分支。
如果 prob 低于阈值,则可以不计算 bbox 分支,减少计算量。
ncnn 不依赖任何第三方库,完全独立实现所有计算过程,不需要 BLAS/NNPACK 等数学计算库。
caffe-android-lib+openblas |
ncnn |
boost gflags glog lmdb openblas opencv protobuf |
无 |
ncnn 代码全部使用 C/C++ 实现,跨平台的 cmake 编译系统,可在已知的绝大多数平台编译运行,如 Linux,Windows,MacOS,Android,iOS 等。由于 ncnn 不依赖第三方库,且采用 C++ 03 标准实现,只用到了 std::vector 和 std::string 两个 STL 模板,可轻松移植到其他系统和设备上。
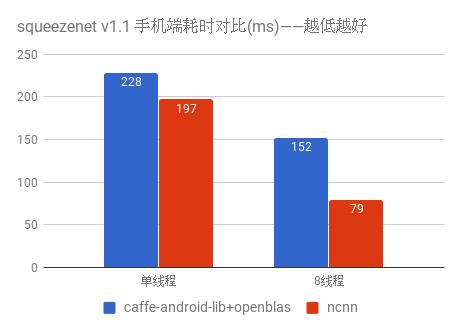
ncnn 为手机端 CPU 运行做了深度细致的优化,使用 ARM NEON 指令集实现卷积层,全连接层,池化层等大部分 CNN 关键层。
对于寄存器压力较大的 armv7 架构,手工编写 neon 汇编,内存预对齐,cache 预缓存,排列流水线,充分利用一切硬件资源,防止编译器意外负优化。
测试手机为 nexus 6p,android 7.1.2
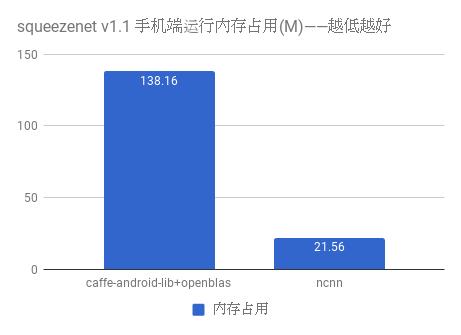
在 ncnn 设计之初已考虑到手机上内存的使用限制,在卷积层、全连接层等计算量较大的层实现中,没有采用通常框架中的 im2col + 矩阵乘法,因为这种方式会构造出非常大的矩阵,消耗大量内存。因此,ncnn 采用原始的滑动窗口卷积实现,并在此基础上进行优化,大幅节省了内存。在前向网络计算过程中,ncnn 可自动释放中间结果所占用的内存,进一步减少内存占用。
内存占用量使用 top 工具的 RSS 项统计,测试手机为 nexus 6p,android 7.1.2
ncnn 提供了基于 openmp 的多核心并行计算加速,在多核心 cpu 上启用后能够获得很高的加速收益。ncnn 提供线程数控制接口,可以针对每个运行实例分别调控,满足不同场景的需求。
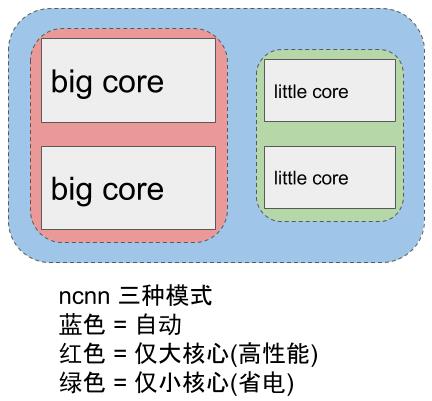
针对 ARM big.LITTLE 架构的手机 cpu,ncnn 提供了更精细的调度策略控制功能,能够指定使用大核心或者小核心,或者一起使用,获得极限性能和耗电发热之间的平衡。例如,只使用 1 个小核心,或只使用 2 个小核心,或只使用 2 个大核心,都尽在掌控之中。
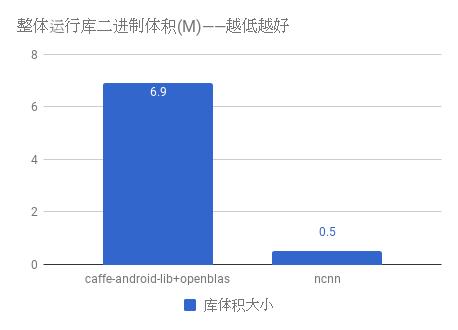
ncnn 自身没有依赖项,且体积很小,默认编译选项下的库体积小于 500K,能够有效减轻手机 APP 安装包大小负担。此外,ncnn 在编译时可自定义是否需要文件加载和字符串输出功能,还可自定义去除不需要的层实现,轻松精简到小于 300K。
可扩展的模型设计,支持 8bit 量化和半精度浮点存储,可导入 caffe 模型ncnn 使用自有的模型格式,模型主要存储模型中各层的权重值。ncnn 模型中含有扩展字段,用于兼容不同权重值的存储方式,如常规的单精度浮点,以及占用更小的半精度浮点和 8bit 量化数。大部分深度模型都可以采用半精度浮点减小一半的模型体积,减少 APP 安装包大小和在线下载模型的耗时。ncnn 带有 caffe 模型转换器,可以转换为 ncnn 的模型格式,方便研究成果快速落地。
在某些特定应用场景中,如因平台层 API 只能以内存形式访问模型资源,或者希望将模型本身作为静态数据写在代码里,ncnn 提供了直接从内存引用方式加载网络模型的功能。这种加载方式不会拷贝已在内存中的模型,也无需将模型先写入实体的文件再读入,效率极高。
ncnn 提供了注册自定义层实现的扩展方式,可以将自己实现的特殊层内嵌到 ncnn 的前向计算过程中,组合出更自由的网络结构和更强大的特性。
以上是关于腾讯优图开放手机端深度学习框架,无第三方库依赖,可跨平台使用的主要内容,如果未能解决你的问题,请参考以下文章
腾讯优图首度开源深度学习框架ncnn主打手机端,同类cpu框架最快