基于CNN的深度学习框架设计进展概述
Posted 人工智能导论
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于CNN的深度学习框架设计进展概述相关的知识,希望对你有一定的参考价值。
CNN(Convolution Neural Network,卷积神经网络)作为一种经典的 DNN 结构,上世纪90年代就已经被提出了,却沉寂近20年。近些年,CNN 在语音处理、NLP 领域也发展迅速。本文会介绍 CNN 的相关概念,并具体介绍一些有趣的 CNN 架构。
CNN 其实可以看作 DNN 的一种特殊形式。它跟传统 DNN 标志性的区别在于两点,Convolution Kernel 以及 Pooling。
Convolution Kernel
说起 Convolution Kernel,首先要解释一下 Convolution(卷积)。一般我们接触过的都是一维信号的卷积,也就是
在信号处理中,x[n]是输入信号,h[n]是单位响应。于是输出信号y[n]就是输入信号x[n]响应的延迟叠加。这也就是一维卷积本质:加权叠加/积分。
那么对于二维信号,比如图像,卷积的公式就成了
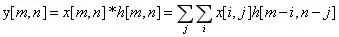
假设现在 Convolution Kernel 大小是3*3,我们就可以化简公式为

看公式很繁琐,我们画个图看看,假如 Convolution Kernel 如下图
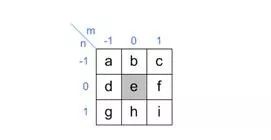
那么,从 Input Image 到 Output Image 的变化如下:
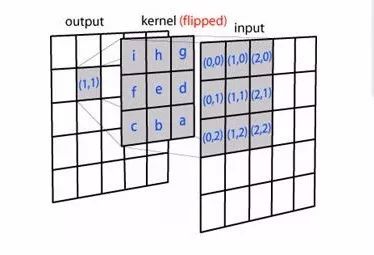
可以看出,其实二维卷积一样也是加权叠加/积分。需要注意的是,其中 Convolution Kernel 进行了水平和竖直方向的翻转。
Convolution Kernel 的意义
Convolution Kernel 其实在图像处理中并不是新事物,Sobel 算子等滤波算子,一直都在被用于边缘检测等工作中,只是以前被称为 Filter。图像处理的同学应该有印象。
Convolution Kernel 的一个属性就是局部性。即它只关注局部特征,局部的程度取决于 Convolution Kernel 的大小。比如用 Sobel 算子进行边缘检测,本质就是比较图像邻近像素的相似性。
也可以从另外一个角度理解 Convolution Kernel 的意义。学过信号处理的同学应该记得,时域卷积对应频域相乘。所以原图像与 Convolution Kernel 的卷积,其实对应频域中对图像频段进行选择。比如,图像中的边缘和轮廓属于是高频信息,图像中区域强度的综合考量属于低频信息。在传统图像处理里,这些物理意义是指导设计 Convolution Kernel 的一个重要方面。
CNN 的 Convolution Kernel
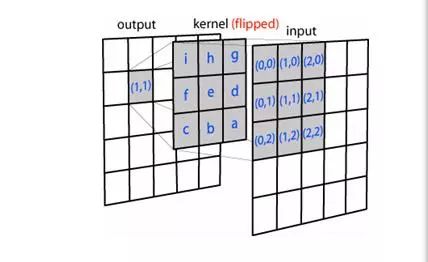
跟传统的 Convolution Kernel 本质没有什么不同。仍然以图像为例,Convolution Kernel 依次与 Input 不同位置的图像块做卷积,得到 Output,如下图。
同时,CNN 有一些它独特的地方,比如各种定义,以及它属于 DNN 的那些属性:
1.CNN 可以看作是 DNN 的一种简化形式,Input 和 Output 是 DNN 中的 Layer,Convolution Kernel 则是这两层连线对应的w,且与 DNN 一样,会加一个参数 Bias b。
2.一个 Convolution Kernel 在与 Input 不同区域做卷积时,它的参数是固定不变的。放在 DNN 的框架中理解,就是对 Output Layer 中的神经元而言,它们的w和b是相同的,只是与 Input Layer 中连接的节点在改变。在 CNN 里,这叫做 Shared Weights and Biases。
3.在 CNN 中,Convolution Kernel 可能是高维的。假如输入是m * n * k维的,那么一般 Convolution Kernel 就会选择为d * d * k维,也就是与输入的 Depth 一致。
4.最重要的一点,在 CNN 中,Convolution Kernel 的权值其实就是w,因此不需要提前设计,而是跟 DNN 一样利用 GD 来优化
5.如上面所说,Convolution Kernel 卷积后得到的会是原图的某些特征(如边缘信息),所以在 CNN 中,Convolution Kernel 卷积得到的 Layer 称作 Feature Map。
6.一般 CNN 中一层会含有多个 Convolution Kernel,目的是学习出 Input 的不同特征,对应得到多个 Feature Map。又由于 Convolution Kernel 中的参数是通过 GD 优化得到而非设定的,于是w的初始化就显得格外重要了。
Pooling
Pooling 的本质,其实是采样。Pooling 对于输入的 Feature Map,选择某种方式对其进行压缩。如下图,表示的就是对 Feature Map 2 *2邻域内的值,选择最大值输出到下一层,这叫做 Max-Pooling。于是一个2N *2N的 Feature Map被压缩到了N *N。
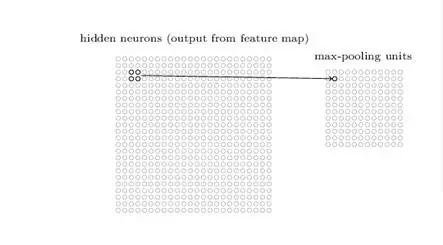
除此之外,还有Mean-Pooling,Stochastic-Pooling 等。它们的具体实现如名称所示,具体选择哪一个则取决于具体的任务。
Pooling 的意义,主要有两点:
第一个显而易见,就是减少参数。通过对 Feature Map 降维,有效减少后续层需要的参数。
另一个则是 Translation Invariance。它表示对于 Input,当其中像素在邻域发生微小位移时,Pooling Layer 的输出是不变的。这就增强了网络的鲁棒性,有一定抗扰动的作用。
我们可以从上面看出来,CNN 里结构大都对应着传统图像处理某种操作。区别在于,以前是我们利用专家知识设计好每个操作的细节,而现在是利用训练样本+优化算法学习出网络的参数。在实际工程中,我们也必须根据实际物理含义对 CNN 结构进行取舍。
但是,随着 Convolution 的堆叠,Feature Map 变得越来越抽象,人类已经很难去理解了。为了攻克这个黑箱,现在大家也都在尝试各种不同的方式来对 CNN 中的细节进行理解,因为如果没有足够深的理解,或许很难发挥出 CNN 更多的能力。不过,这就是另外一个很大的课题了。
接下来的部分,会介绍 CNN 一路发展以来,一些有趣架构。
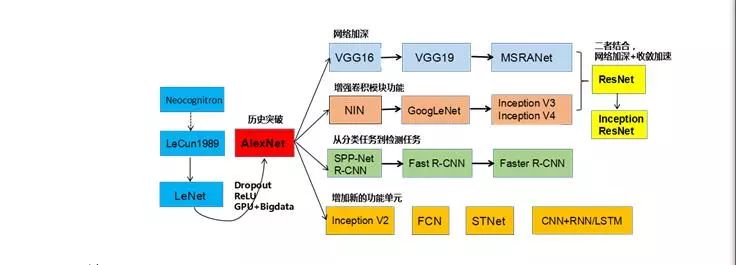
CNN 架构的变迁史。
LeNet-5 是最经典的 CNN 架构,上面介绍的 Convolutional Kernel 和 Pooling 它都有了。它在1998年由 LeCun 提出,用于对“Mnist手写数字数据集”进行分类。不过效果并不比当时手工设计的特征有明显提升,因此并没有太大反响。
十来年后,Alex Krizhevsky 在2012年提出 AlexNet,凭借它在 ILSVRC2012 的 ImageNet 图像分类项目中获得冠军,且错误率比上一年冠军下降十多个百分点。举圈震惊。
随后几年,CNN 卷席整个图像处理领域,ILSVRC 每年被刷榜,也就出现了我们常见的这张错误率下降趋势的图。当然,也伴随着如图所示的 Layer 数的激增。
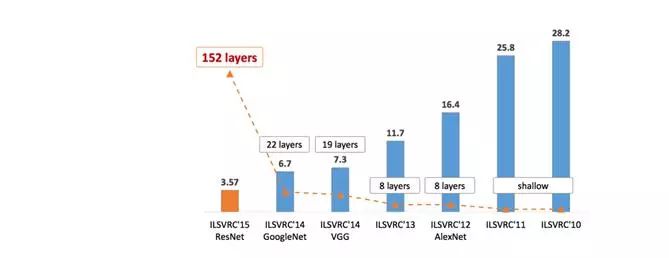
我们对一些有趣的架构进行详细介绍:
LeNet-5[1]
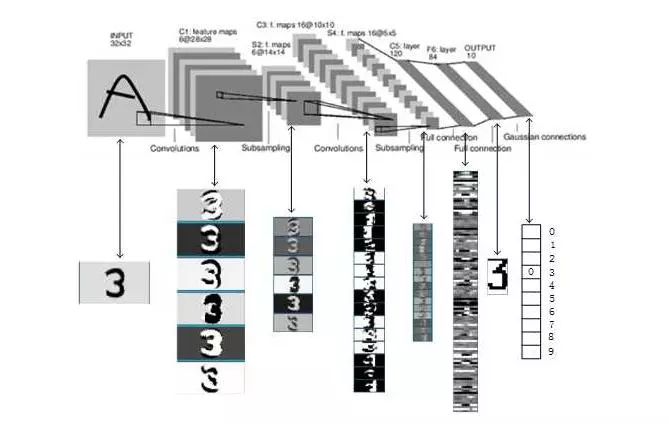
LeNet5 是 LeCun 在1998年“Gradient-Based Learning Applied to Document. Recognition”中提出的网络架构。用于对“Mnist手写数字数据集”进行分类。其具体的结构如下图
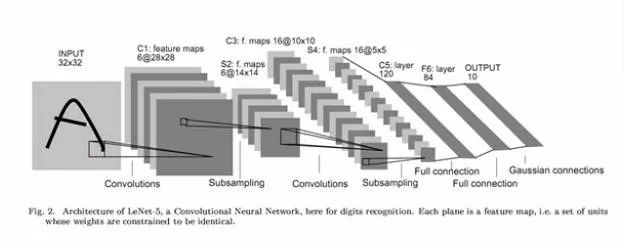
Input 是一个手写图像。
C1 层由6个 Feature Map 组成,其中每个神经元与 Input 的5 *5的邻域相连。这些连接对应的w就是上面所说的 Convolution Kernel。当然,与 DNN 一样,这里还有一个参数 Bias b。所以,此层有(5*5+1)*6=156个参数。而如果不使用共享权重,则会需要(5x5+1)x(28x28)x6 = 122304个参数。
S2 层即下采样层,对应着现在的 Pooling 操作后的层。其依然是6个 Channel,每个神经元与上一层2* 2的邻域相连。作者在此层进行的操作是加权平均,再加上 bias,并将结果输入到激活函数 Sigmoid 函数中。因此,此层共有2*6=12个参数。
C3 层由16个 Feature Map 组成,其中每个神经元与 S2 的5 *5的邻域相连。不过,当时作者对连接进行了一些设计,让每个 Feature Map 仅与上一层部分 Channel 相连。只是这种 trick 现在也很少用到,这里就不细讲了。
S4 层也是下采样层,与 S2 是意义一样。由于有16个 Channel,因此共2*16=32个参数。
C5 层由120个 Feature Map 组成,其中每个神经元与 S4 每个 Channel 的5 *5的邻域相连。恰巧,这里 C3 的每一个 Feature Map 都是1 * 1,显得好像跟 S4 是全连接,不过这仅仅是恰巧罢了。
F6 由84个神经元组成,与 C5 全连接。并将结果输入到激活函数,得到每个神经元的状态。这里激活函数使用的是双曲正切函数(tanh)。此层共(120+1)*84=10164个参数。而之所以使用84个神经元,是因为有人曾将 ASCII 码绘制于12 *7的 bit-map 上,如下图,作者希望此层的输出有类似的效果。

Output 是10个神经元,分别代表十个数字。作者还使用欧式径向基函数(Euclidean Radial Basis Function)对数据进行了一些变换,有兴趣的同学可以自行参考原文。
网络结构设计好之后,选择 Loss Function,并利用 GD 学习网络参数,这些都是套路了。最后,LeNet-5 每一层的输出可以用以下这张图来辅助理解。
AlexNet
AlexNet 是 Alex Krizhevsky 于2012年在“ImageNet Classification with Deep Convolutional Neural Networks”中提出的网络架构。Alex Krizhevsky 凭借它在 ILSVRC2012 的 ImageNet 图像分类项目中获得冠军,错误率比上一年冠军下降十多个百分点。其具体的结构如下图,第一个图为作者论文中的辅助理解的图示,第二个图为将 AlexNet 每一层的细节进行总结的图。
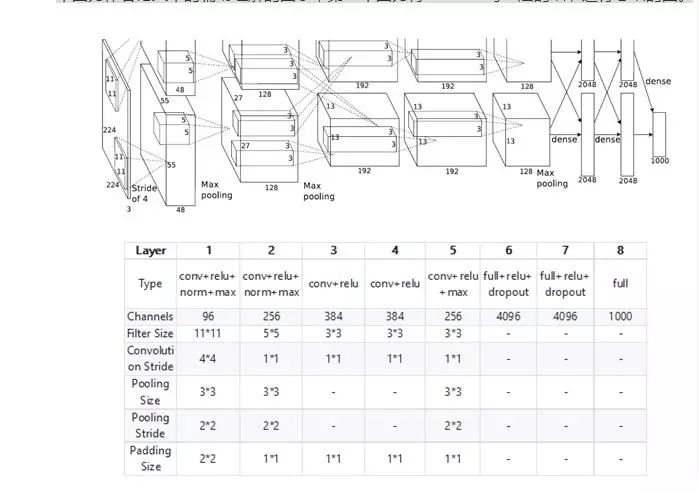
从上图可以看出,AlexNet 在结构上没有大改变。
它真正区别于传统 CNN 的,在于对网络参数的选择上,而其中很多方法如今依然在用:
不同于传统 CNN 使用 Sigmoid 或者 Tanh 作为激活函数,AlexNet 使用的是 Relu。Relu 能有效抑制 Gradient Vanish 以及 Gradient Explode 的问题,现在仍然是最常用的激活函数。关于 Gradient Vanish 和 Relu 的更多理论细节,可以参看“当我们在谈论 Deep Learning:DNN 与它的参数们(壹)”[2]中"Activation Function"一部分。
AlexNet 开始使用了 Droupout 来防止过拟合,这是一种简单且有效减少过拟合的方法,如今依然是手常用方法之一。关于 Droupout 更多理论细节,在“当我们在谈论 Deep Learning:DNN 与它的参数们(贰)”[3]中已经详细介绍过了。
AlexNet 使用 LRN(Local Response Normalization)对网络中的数据进行归一化。当然现在 LRN 已经不太使用,使用的较多的是效果好得多的 Batch Normalization。但是 AlexNet 当时已经开始注意对数据进行归一化,这一点还是很厉害的。Batch Normalization 相关的细节在“当我们在谈论 Deep Learning:DNN 与它的参数们(叁)”[4]部分
AlexNet 使用了 GPU 来加速网络中的运算,现在 GPU 来加速计算已经是标配了
AlexNet 中这些技巧,很多已经成了现在的标准方法,足见其影响力之大。
NIN
NIN 出自文章“Network in Network”,主要是提出了两点新的构想,以下简单描述:
使用多层1* 1的 Convolution Kernel,来代替传统 CNN 一层的若干个N* N的 Convolution Kernel。原因在于,单层的 Convolution Kernel + Activation 只是扩展的线性变换,表达能力有限;但是多层 Convolution Kernel + Activation 的堆叠,后面几层的抽象能力会大大增强,所以表达能力比以前强,而参数可能还比以前少。
使用 Global Average Pooling 代替传统 CNN 中最后一层的 Fully Connected 层,其中 Global Average Pooling 表示取每个 Feature Map 的均值。因此,对多类分类,最后一层的每个 Feature Map 即对应一个类别,在大大减少了 CNN 参数的同时,强制 Feature Map 学习不同类别的特征。
Inception V1,BN,V3,V4
Inception V1 就是 GoogLeNet ,出自2015年的“Going Deeper with Convolutions”。它继承并扩展了 NIN 中使用小 Convolution Kernel 来代替或者表示大 Convolution Kernel 的思想,在网络能力不减的情况下大大降低参数量。
Inception BN [6]出自2015年的“Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”。在本文中,作者提出了大名鼎鼎的 Batch Normalization,现在是 DNN 调参的一个重要手段,提高了 DNN 对参数的稳定性。BN 的具体细节请参考“当我们在谈论 Deep Learning:DNN 与它的参数们(叁)”[4]。
Inception V3 出自2016年的“Rethinking the Inception Architecture for Computer Vision”[5]。其在 Inception V1 的基础上,利用 Factorization 进一步降低 Convolution Kernel 中的参数数量。
Inception V4 [7]出自2016年的“Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning”。如其名所说,它就是结合了 Inception 和 ResNet 的思想。关于 ResNet 下文会有详细介绍。
可以看出,除了 Inception BN 主题有点跑偏,其他的 Inception 都是在 GoogLeNet 的基础上的改进。所以,以下我会详细介绍 GoogLeNet。
GoogLeNet
GoogLeNet 其实属于 Inception 网络结构系列,其启发是 NIN(Network In Network),而后整个 Inception 系列共发展出四个版本。这里,先简单介绍这几种结构。
GoogLeNet 最大的特点就是下面这种结构,暂且称之为原始的 Inception。
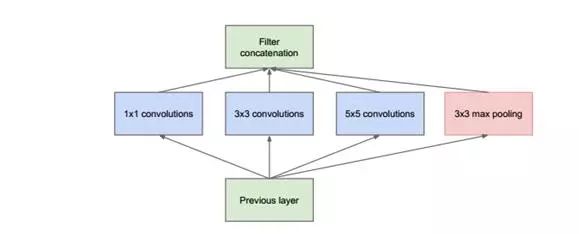
可以看出它本质跟 NIN 一样,使用 Network 来代替原来的一个 Convolution Kernel。但跟 NIN 只使用1*1不同,这里使用了更大的 Convolution Kernel,以及 Pooling Layer,原因在于提取视野更大、或者提取类型不同的特征。但是由于这种 Network 的参数会非常大,所以作者先进行了降维,就得到了真正的 Inception 结构,如下图
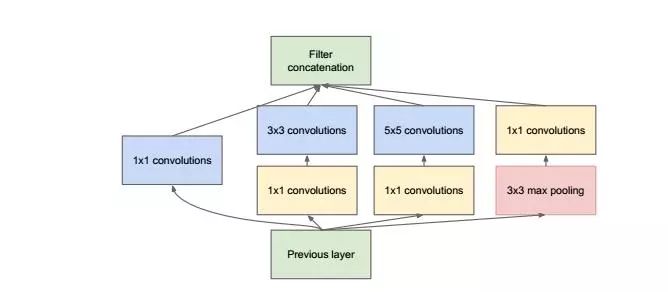
1*1 Kernel 在这里的作用就是为了在叠加 Inception 模块时,不至于让网络参数数量爆炸,所做的降维。在理解了 Inception 模块后,整个 GoogLeNet 的结构上就很容易看懂了,基本就是 Inception 模块、Pooling Layer 的不停叠加而已。其结构如下图
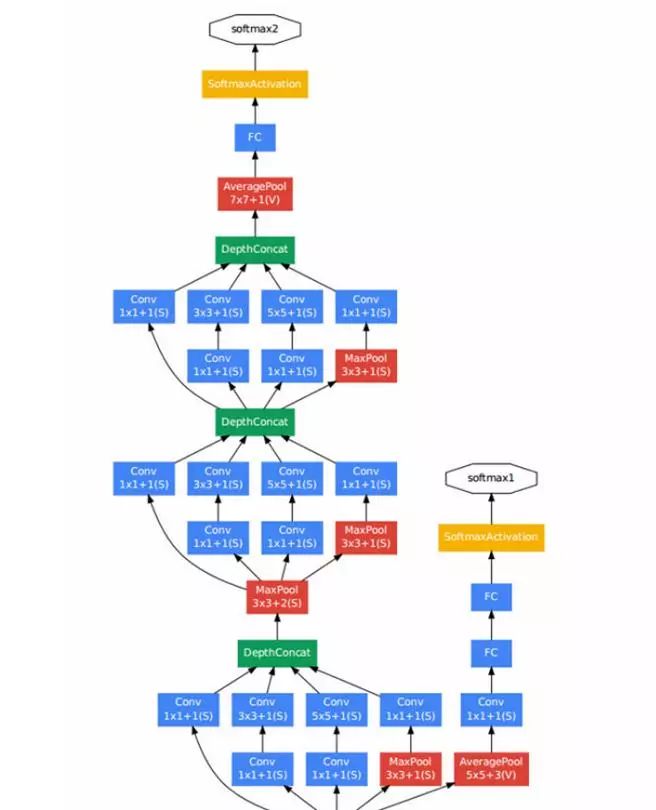
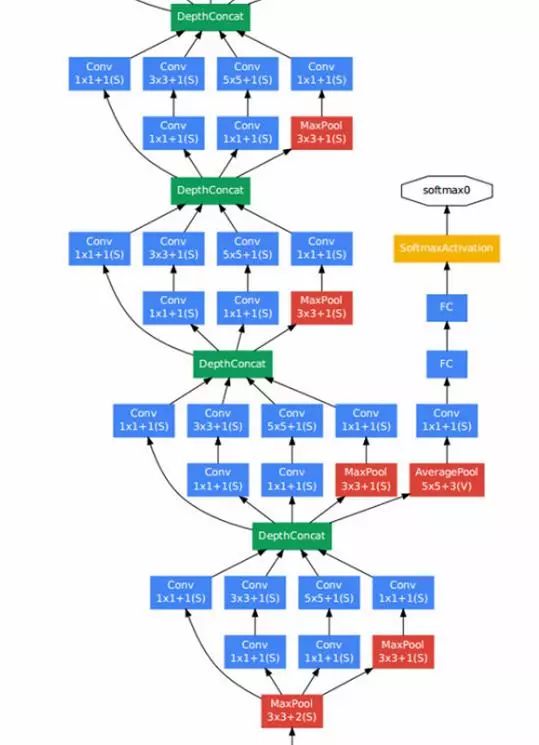
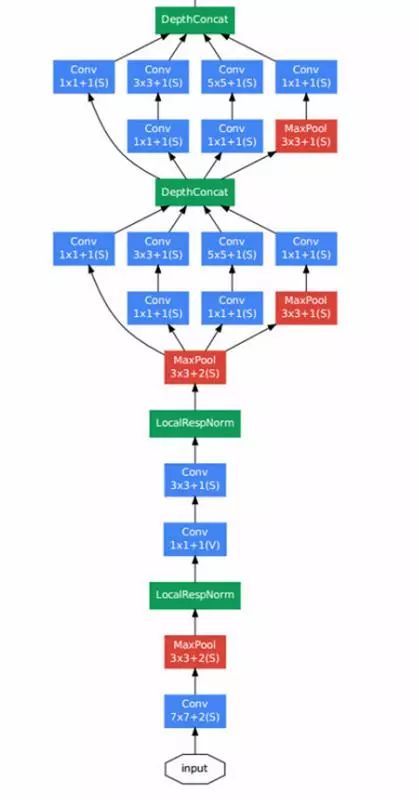
上图中我们能看到有一点比较特殊,就是除了最上层的 softmax2 分类器外,中间还有一些层连接了分类器(softmax0、softmax1)。
按照作者初期的说法,这是因为网络太深,Gradient Vanish 导致无法高效的更新参数,所以加了两个较浅的分类器辅助 BP 以加快网络收敛速度。可是在 Inception V3 中,发现其实它们对网络收敛速度并没什么帮助,更多的是起到了 Regularizer 的作用。
Inception 提出了新的 CNN 结构,并在 ILSVRC2014 使错误率再创新低。可它在深层网络 Gradient Vanish 的问题上并未找到好的解决办法,这就制约了网络进一步的加深。就在大家看似都一筹莫展时,另一个大佬微软掏出了 ResNet。
ResNet
ResNet [8]出自“Deep Residual Learning for Image Recognition,2016”。它源于作者一些实验:在 Relu、BN 已经缓解了深层的网络无法收敛的问题后,随着网络层数的增加,训练和测试错误率仍然呈现先减后增的趋势。这时,就不再是过拟合的问题,而表明太深的网络其参数难以优化。比如对于恒等变换H(x)=x,更深的网络其对此函数的拟合效果甚至不如较浅的网路。
为了解决上述H(x)=x难以拟合的问题,作者提出了一种设想:我们不去拟合H(x),改之去拟合F(x)=H(x)-x。而最终网络输出的是H(x)=F(x)+x,如下图
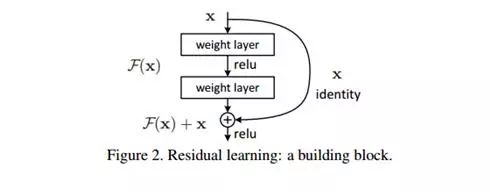
这种做法会涉及到两个问题:
在恒等变换中我们拟合的函数变成了F(x)=0,它为什么比原始的H(x)=x更容易拟合呢?作者表示,此时参数们只需要逼近0即可,这看起来比优化到其他值简单(这个虽然抽象,但似乎还有点道理)。
实际情况中H(x)不太可能都是恒等变换,这种拟合残差的做法为何有好处呢?作者表示,首先我们要假设它更好优化,其次我们的实验证明了它确实效果更好(这里估计很多 ML 学者希望亮出那张“尴尬又不失得体的笑”的表情图)。
上面是戏谑一下 RessNet 在起初时的理论匮乏。其实在后续,分析其理论依据的文章也相继有提出,如
1.在“Identity Mappings in Deep Residual Networks,2016”中,作者从实验和理论两方面来说明为什么 ResNet 使用 Identity Mappping 来计算残差是合理的,且稳定性更强
2.在"Residual Networks Behave Like Ensembles of Relatively Shallow Networks,2016"中,作者则用实验表明 ResNet 可能效果显著的原因在于其 Ensemble 的性质,即它的 Shortcut 层可以看作多种不同的路径的 Ensemble,如下图。同时作者也表示 ResNet 真实选择路径时其实选的都是较短的路径,因此本质上并不算解决了深层网络 Gradient Vanish 的问题
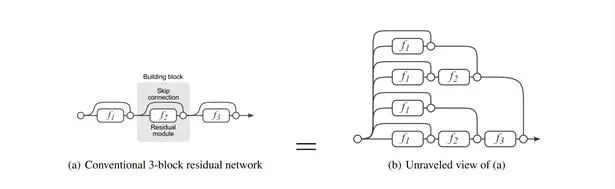
无论如何,ResNet 虽然理论不足,却被大量检验证明能有效改善网络参数的优化,一方面是即使网络深度剧增依然能够很好的学习参数,保持较好的网络分类效果;另一方面,参数收敛速度也更快。最终的 ResNet 架构如下,可以看出层数已经超深了
毫无疑问 CNN 还处于高速进化阶段,后续到底是会“返璞归真”,开始注重单层 Layer 的质量,毕竟现在堆砌的 Layer 其实很多都被浪费了;还是继续“没有最深,只有更深”地往前奔,现在看着仍是未知数。未来需要不断的探寻。
引用来源
[1]出自1998版Gradient-Based Learning Applied to Document. Recognition
[2]https://zhuanlan.zhihu.com/p/26122560
[3]https://zhuanlan.zhihu.com/p/26392287
[4]https://zhuanlan.zhihu.com/p/26682707
[5]出自2016版Rethinking the Inception Architecture for Computer Vision
[6]出自2015版atch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
[7]出自2016版Inception-ResNet and the Impact of Residual Connections on Learning
[8]出自2016版Deep Residual Learning for Image Recognition
[余文毅论文]https://zhuanlan.zhihu.com/p/27235732
https://zhuanlan.zhihu.com/p/27023778
以上是关于基于CNN的深度学习框架设计进展概述的主要内容,如果未能解决你的问题,请参考以下文章