如何为深度学习框架构建性能模型?
Posted PKUFineLab
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何为深度学习框架构建性能模型?相关的知识,希望对你有一定的参考价值。
▼
2012年提出的AlexNet有8个隐层,2014年提出的VGG有19个隐层,GoogleNet有22个隐层,2015年提出的ResNet的隐层数量高达152层。随着深度神经网络模型层数越来越深,模型参数不断增多,仅依靠单个机器难以训练如此大规模的深度神经网络,分布式深度学习框架应运而生。近年来,深度学习框架层出不穷。工业界有Microsoft提出的CNTK[1],Google提出的Tesnsorflow[2],学术界有Moritz等人提出的SparkNet[3],Iandola等人提出的FireCaffe[4],Chen T等人提出的MXNet[5] 等。那么在训练深度神经网络时究竟应该选择哪一个分布式框架呢?应该搭建多少个节点的集群呢?本文将结合Sayed等人的工作[6]和Hang Qi等人的工作[7]介绍一种为深度学习框架构建性能模型的方法,帮助您解决以上难题。
▼
正文
一、传统分布式平台的性能模型
性能模型通过对决定系统性能的主要因素进行建模,预测系统性能(本文中的系统性能指任务执行时间)传统的分布式平台(如Hadoop,Spark等)的性能模型大致可以分为三类:白盒模型、黑盒模型和灰盒模型。白盒模型通过分析程序运行的具体过程,依赖专家知识定义性能模型。白盒性能模型可以用具体的数学公式表示。黑盒模型通过收集历史训练数据,采用机器学习方法拟合数据特征与执行时间的关系。灰盒方法是将两者相结合,在初始数据量较少的阶段使用白盒方法,数据量增加后使用黑盒方法提高准确率。
由于训练大规模深度神经网络需要耗费大量时间,且训练过程基本为一次性行为,所以黑盒和灰盒方法均不适用。不同分布式深度学习框架训练网络的过程大致相同,因此即使采用白盒方法训练性能模型,也能有很好的泛化能力。
二、分布式深度学习框架的性能模型
与传统的分布式平台有所区别,不同的分布式深度学习框架在训练深度神经网络时过程大致相同。在训练时,将数据分发到计算节点上,每个计算节点独立训练数据,然后将计算出的权重值发送给管理节点,并从管理节点获取最新的权重值。管理节点负责对各节点发送的权重进行处理和数据同步。重复这一过程直到模型收敛或者达到最大训练次数。因此,深度神经网络的训练时间可以分为三部分:计算时间,数据移动时间和通信时间。
计算时间
单个节点上的计算时间如公式1所示,Tprocess表示计算节点端的数据处理时间,其中n表示有n条数据,cp为一个常量,表示处理一条数据所需的平均时间。Tupdate为管理节点处理权重所需的时间。cb为一个常量,表示管理节点处理权重所需的平均时间。 数据移动时间
数据移动时间又可以分为磁盘时间和内存时间。在训练DNN时,首先需要将各个计算节点上的数据从磁盘读入内存中。这部分时间为磁盘时间表示为公式2的Tdisk,其中rd为一个常量,表示磁盘读取一个字节所需时间,nf表示数据的特征维度。在更新权重时,需要从内存中读取数据特征用以计算,然后从内存中读入最新的权重进行更新,并将更新后的权重写回内存中。这一部分表示为公式3的Tmemory,其中rm与wm分别代表从内存中读和写一个字节所需时间,b为计算梯度时的batch大小。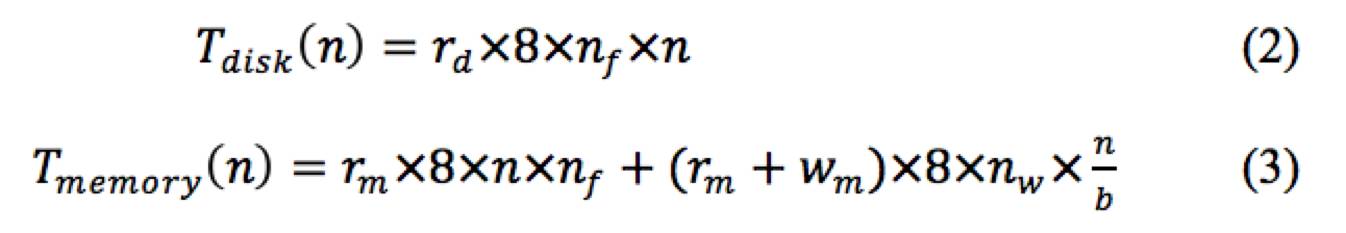 通信时间
通信时间
在训练深度神经网络时,由于模型参数众多,所以计算节点与管理节点间的网络通信非常频繁。公式4Tsend表示计算节点向管理节点发送信息所需时间。rnet表示通过网络传输一个字节所需的平均时间,为网络带宽倒数。nw表示权重向量维度,n表示一个计算节点处理的数据量,b表示batch大小。因为每训练一个batch大小的数据,更新一次权重,所以仅需向管理节点发送n/b次权重。整个网络通信时间可以表示为公式5,由于计算节点需要上传权重并获取管理节点最新权重,所以需要两个Tsend时间。w代表计算节点个数,cu代表服务器端同步所需平均时间。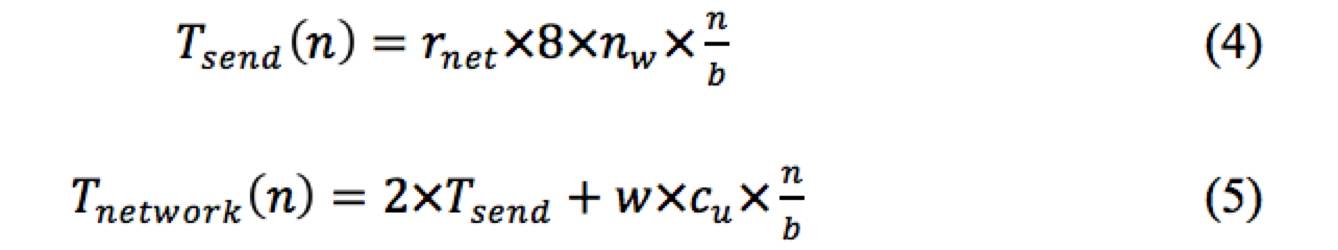
性能模型
如果采用ASP(Asynchronous Parallel),SSP(Stable SynchronousParallel)同步,计算节点上传权重后立刻从管理节点获取最新权重,网络传输与数据训练并行,则使用w个计算节点处理d条数据的性能模型可以表示为公式6。
如果框架采用BSP(Bulk SynchronousParallel)同步策略,每次计算节点等待管理节点同步所有计算节点后才获取最新权重,则使用w个计算节点处理d条数据的性能模型可以表示为公式7。
公式中的常量cp,cb,cu,rd,wd,rm,wm,rnet,由于与不同硬件类型,深度学习框架,神经网络模型等密切相关,为提高性能模型的准确率,可以通过跑少量数据集获取这些常数。这里仅介绍了OneToAll结构(一个管理节点与多个计算节点通信)的网络通信模式,如果采用了Tree AllReduce(树形拓扑)或ButterflyAllReduce (蝶型拓扑)结构的网络通信模型,可以参考Hang Qi等人的工作。
三、结语
分布式深度学习框架可以通过增加硬件资源的方式减少深度神经网络的训练时间。但是对于CNTK,TensorFlow等分布式深度学习框架的性能和可扩展性还缺少深入的研究。因此,本文介绍了一种分布式深度学习框架的性能模型,用以预测深度神经网络的训练时间,指导深度神经网络模型的部署。同时可以研究深度神经网络框架的可扩展性,寻找框架的性能瓶颈,帮助研发人员优化框架性能。
参考资料:
[1] http://cntk.codeplex.com
[2] Abadi M, Agarwal A, Barham P, et al.Tensorflow: Large-scale machine learning on heterogeneous distributedsystems[J]. arXiv preprint arXiv:1603.04467, 2016.
[3] Moritz P, Nishihara R, Stoica I, et al.Sparknet: Training deep networks in spark[J]. arXiv preprint arXiv:1511.06051,2015.
[4] Iandola F N, Moskewicz M W, Ashraf K,et al. Firecaffe: near-linear acceleration of deep neural network training oncompute clusters[C]//Proceedings of the IEEE Conference on Computer Vision andPattern Recognition. 2016: 2592-2600.
[5] Chen T, Li M, Li Y, et al. Mxnet: Aflexible and efficient machine learning library for heterogeneous distributedsystems[J]. arXiv preprint arXiv:1512.01274, 2015.
[6] Qi H, Sparks E R, Talwalkar A. Paleo: Aperformance model for deep neural networks[J]. 2016.
[7] Hashemi S H, Noghabi S A, Gropp W.Performance Modeling of Distributed Deep Neural Networks[J]. arXiv preprintarXiv:1612.00521, 2016.
以上是关于如何为深度学习框架构建性能模型?的主要内容,如果未能解决你的问题,请参考以下文章