百度研究院在 Kubernetes 上跑深度学习框架 PaddlePaddle
Posted 云头条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度研究院在 Kubernetes 上跑深度学习框架 PaddlePaddle相关的知识,希望对你有一定的参考价值。
PaddlePaddle是什么东东?
PaddlePaddle是一种易于使用的、高效的、灵活的、可扩展的深度学习平台,最初由百度开发,从2014年以来用来将深度学习运用于百度内部。
使用PaddlePaddle开发的创新成果已有50多项,支持百度的15种产品,这些产品包括搜索引擎、在线广告和百度问答和系统安全等。
2016年9月,百度开放了PaddlePaddle的源代码(https://github.com/PaddlePaddle/Paddle),很快从百度外面吸引来了许多贡献者。
为什么在Kubernetes上跑PaddlePaddle?
PaddlePaddle旨在力求简洁,独立于计算基础设施。用户可以在Hadoop、Spark、Mesos、Kubernetes及其他平台上运行它。我们之所以对Kubernetes抱有浓厚的兴趣,是因为它具有灵活性、高效和丰富功能等优点。
虽然我们将PaddlePaddle运用于百度的诸多产品,但是注意到PaddlePaddle主要有两种用途:研究和产品。研究数据并不经常变化,关注的重点是快速实验,从而获得预期的科学测量。产品数据经常变化。它通常来自由Web服务生成的日志消息。
一个成功的深度学习项目包括研究和数据处理管道。有好多参数有待调整。许多工程师同时致力于项目的不同部分。
为了确保项目易于管理,并高效地利用硬件资源,我们想在同一个基础设施平台上运行项目的所有部分。
该平台应提供下列功能:
容错:它应该将管道的每个阶段抽取为服务,服务由通过冗余机制,提供高吞吐量和稳健性的许多进程组成。
自动扩展:在白天,通常有好多活跃用户,平台应该可以横向扩展在线服务。到了夜间,平台应该腾出部分资源,用于深度学习实验。
作业包装和隔离:平台应该能够为同一个节点分配需要GPU的PaddlePaddle训练器进程、需要大容量内存的Web后端服务以及需要磁盘输入输出的CephFS进程,以便全面利用硬件资源。
我们想要这样的平台:在同一个集群上运行深度学习系统、Web服务器(比如nginx)、日志收集工具(比如fluentd)分布式队列服务(比如Kafka)、日志连接工具以及使用Storm、Spark和Hadoop MapReduce编写的其他数据处理工具。我们想在同一个集群上运行所有作业(在线和离线,生产和实验环境),那样我们可以充分利用集群,因为不同类型的作业需要不同的硬件资源。
我们选择了基于容器的解决方案,因为虚拟机带来的开销与我们要实现的效率和利用率这个目标相矛盾。
我们研究比较了市面上基于容器的不同解决方案后,发现Kubernetes最符合我们的要求。
Kubernetes上的分布式训练
PaddlePaddle本身就支持分布式训练。PaddlePaddle集群中有两个角色:参数服务器(parameter server)和训练器(trainer)。每个参数服务器进程维护全局模型的一个片段。每个训练器都有该模型的本地副本,并使用本地数据来更新模型。在训练过程中,训练器将模型方面的更新内容发送给参数服务器,参数服务器负责聚集这些更新内容,那样训练器可以做到本地副本与全局模型实现同步。
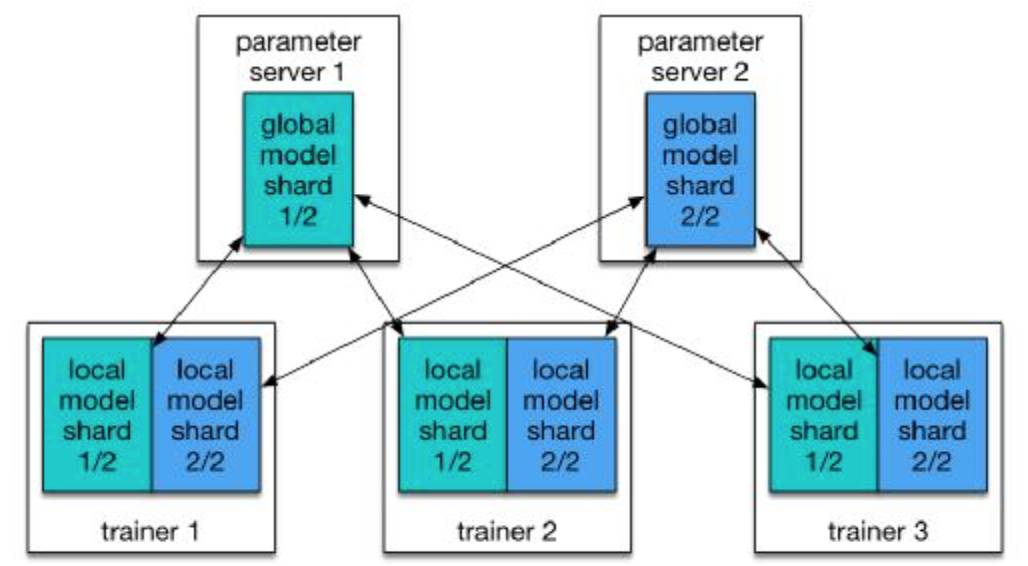
模型被分成了两个片段,分别由两个参数服务器管理
另外一些方法使用一组参数服务器,将一个很庞大的模型共同保存在多个主机上的CPU内存空间中。但是实际上,我们并不常常有这样的庞大模型,因为由于GPU内存的局限性,处理非常庞大的模型非常低效。在我们的配置环境中,多个参数服务器主要用于快速通信。假设只有一个参数服务器进程处理所有训练器,该参数服务器就得聚集来自所有训练器的梯度,因而成为瓶颈。根据我们的经验,一种实验中高效的配置包括相同数量的训练器和参数服务器。我们通常在同一个节点上运行一对训练器和参数服务器。在下列Kubernetes作业配置中,我们启动了运行N Pods的一个作业;每个Pod中都有一个参数服务器和训练器进程。
yaml apiVersion: batch/v1 kind: Job metadata: name: PaddlePaddle-cluster-job spec: parallelism: 3 completions: 3 template: metadata: name: PaddlePaddle-cluster-job spec: volumes: - name: jobpath hostPath: path: /home/admin/efs containers: - name: trainer image: your_repo/paddle:mypaddle command: ["bin/bash", "-c", "/root/start.sh"] env: - name: JOB_NAME value: paddle-cluster-job - name: JOB_PATH value: /home/jobpath - name: JOB_NAMESPACE value: default volumeMounts: - name: jobpath mountPath: /home/jobpath restartPolicy: Never |
我们可以从配置中看到:并行(parallelism)和完成(completions)都设成了3。所以该作业将同时启动3个PaddlePaddle pod,3个pod全部完成后该作业才算完成。
3个pod的作业A和1个pod的作业B在两个节点上运行
每个pod的入口点是start.sh。它从存储服务下载数据,那样训练器可以从pod-local磁盘空间快速读取。下载完成后,它运行一个Python脚本start_paddle.py,该脚本启动参数服务器,一直等到所有pod的参数服务器准备好提供服务,然后在pod中启动训练器进程。
这种等待是必不可少的,因为每个训练器需要与所有参数服务器进行对话,如图1所示。Kubernetes API让训练器能够检查pod的状态,那样Python脚本可以等到所有参数服务器的状态变成“运行中”,之后才触发训练进程。
目前,从数据分片到pod/训练器的映射是静态的。如果我们要运行N个训练器,需要将数据划分成N个分片,并将每个分片静态分配给训练器。同样我们依赖Kubernetes API,让多个pod参与某个作业,那样我们可以将pod/训练器从1索引到N。第i个训练器将读取第i个数据分片。
训练数据通常在分布式文件系统上提供。实际上,我们使用本地集群上的CephFS和AWS上的亚马逊弹性文件系统(Amazon Elastic File System)。如果你有兴趣构建一个Kubernetes集群来运行分布式PaddlePaddle训练作业,请参阅该教程(https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/usage/k8s/k8s_aws_en.md)。
下一步是什么?
我们在努力让PaddlePaddle与Kubernetes更顺畅地协同运行。
你可能注意到了,目前的训练器调度完全依赖Kubernetes,基于静态分区映射。这种方法很容易上手,但可能会导致效率方面的一些问题。
首先,缓慢或死亡的训练器会阻止整个作业。初始部署之后,没有受控制的抢占或重新调度。第二,资源分配是静态的。所以,如果Kubernetes拥有比我们预期更多的可用资源,我们就得手动更改资源需求。这是项乏味枯燥的工作,不符合我们的效率和利用率这个目标。
为了解决上述问题,我们将添加一个PaddlePaddle主节点:它了解Kubernetes API,可以动态添加/删除资源容量,并且以一种更动态的方式将分片分派给训练器。PaddlePaddle主节点使用etcd作为一种机制,以便对从分片到训练器的动态映射实现容错存储。因此,即使主节点崩溃,映射也不会丢失。Kubernetes可以重新启动主节点,作业会继续运行。
另一个可能会有的改进是更好的PaddlePaddle作业配置。我们使用相同数量的训练器和参数服务器方面的经验主要来自使用特殊用途的集群。结果发现,这个策略在我们客户的只运行PaddlePaddle作业的集群上很高效。然而,这个策略在运行多种作业的通用集群上可能不是最佳的。
PaddlePaddle训练器可以利用多个GPU来加速计算。GPU还不是Kubernetes中的“一等公民”资源。我们得半手动管理GPU。我们很愿意与Kubernetes社区合作,改进GPU支持,从而确保PaddlePaddle在Kubernetes上跑得极欢。
云头条编译|未经授权谢绝转载
相关阅读:
以上是关于百度研究院在 Kubernetes 上跑深度学习框架 PaddlePaddle的主要内容,如果未能解决你的问题,请参考以下文章