开发易通用难,深度学习框架何时才能飞入寻常百姓家?
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开发易通用难,深度学习框架何时才能飞入寻常百姓家?相关的知识,希望对你有一定的参考价值。
2018 年 1 月 14 日,袁进辉(老师木)代表 OneFlow 团队在 AICon 北京站做了标题为《深度学习框架技术剖析》的演讲,AI 前线第一时间授权整理了 老师木个人注解版演讲全文。
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
作为框架的开发者,OneFlow 团队(一流科技,老师木的创业公司)发现,虽然框架多种多样,但框架核心技术正呈现收敛的态势,经过几年的发展,在深度学习框架开发者眼里出现一些“共识”,或所谓“最佳实践”,几乎所有框架都去拥抱了这样技术选型,在架构和技术选择上趋同。另一方面,也有一些技术在框架开发者眼里属于举棋不定或无计可施的状态。
这次报告会对已经收敛的技术(“最佳实践”)做一个梳理,读者会发现,开发一个深度学习框架没有那么难。本报告也会简要讨论目前框架未解决的难题,读者也会发现,开发一个超越已有技术的框架有很难的问题。最后,我们会从框架开发者的视角去对主流深度学习框架做一句话点评,供用户在做技术选型时参考。


首先介绍深度学习框架的背景,然后介绍深度学习框架开发中已经收敛的技术和仍未解决的问题,其次点评主流深度学习框架,最后对 2018 年的深度学习框架技术发展做出展望。

本文仅对第四点做一些阐述,用软件实现深度学习算法加速,可分微观和宏观两个层次。
微观层次主要聚焦在单个设备或芯片上的代码优化,设备厂商通常会工作在这个层次,他们会提供高性能的库,譬如 x86 或 arm CPU 上 MKL, OpenBlas,Nvidia GPU 上的 CuBlas, Cudnn 等,在大部分稠密计算场景都能贴近设备的理论性能,优化空间不大(当然在终端设备等低功耗场景有很多发挥空间)。
宏观层次,主要是多设备和多计算节点层面的优化,这要靠分布式框架的支持,是计算力推向更高水平的关键,在性能上仍有巨大优化空间。最后,深度学习软件要解决编程不够快(程序员的效率)和程序运行不够快(计算机的效率)两个痛点,“两个痛点的描述”出自尼克著《人工智能简史》里的一句话。

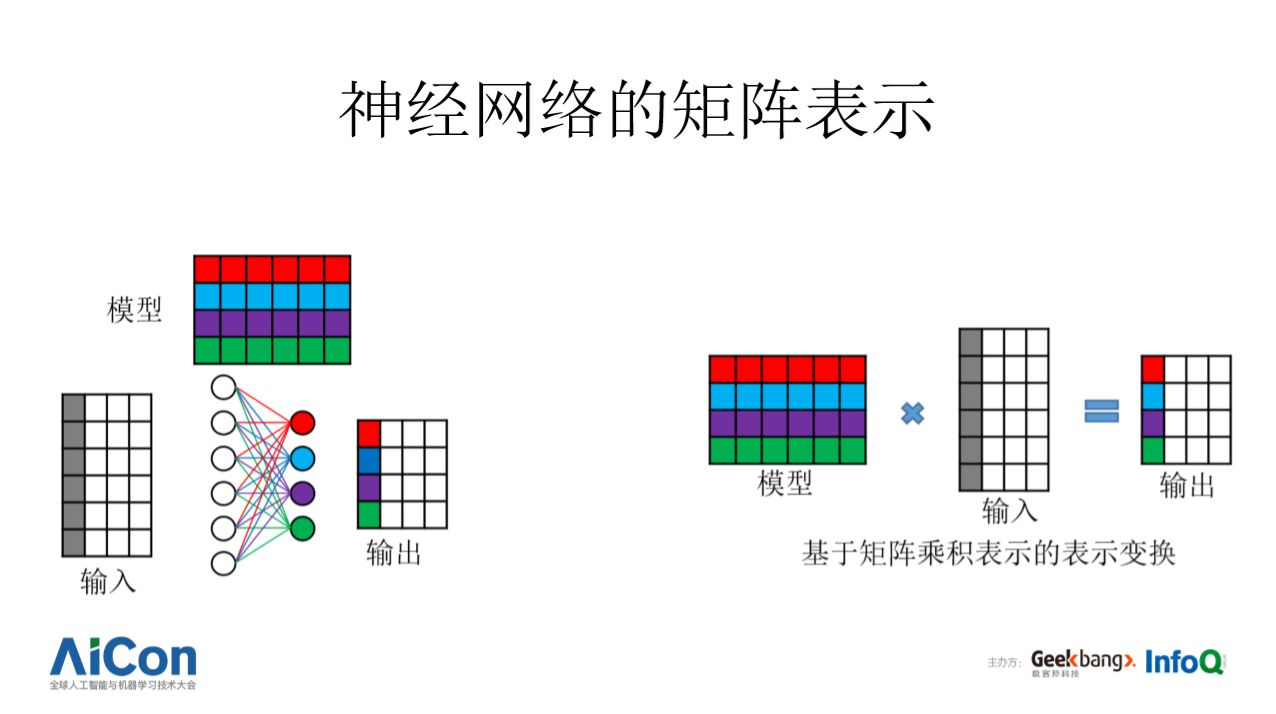
神经网络由若干层次构成,每个层次通常都可以表示成对矩阵的处理,这种稠密计算形式特别适合使用高度并行的硬件加速(GPU、TPU 等)。
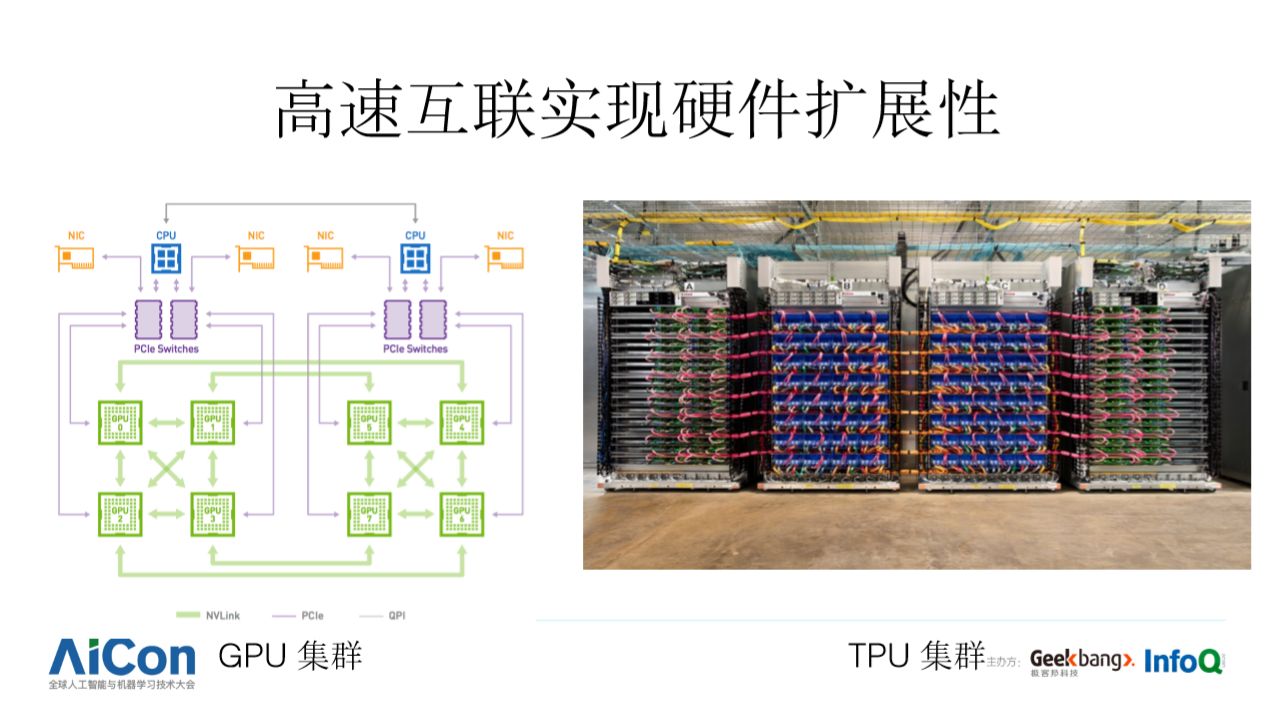
限于硬件制造工艺水平,单个设备(GPU、TPU) 不可能无限大,而工业级应用对计算力的渴求是无止境的,此时就必须用高速互联的多个设备协同来完成大规模计算。上图展示了 GPU 集群和 TPU 集群,在这种配置里,通常是 CPU 和 GPU (或 TPU) 一块儿工作,CPU 负责任务的调度和管理,而 GPU 负责实现稠密计算,这就是经常说的异构计算(Heterogenous computing)。
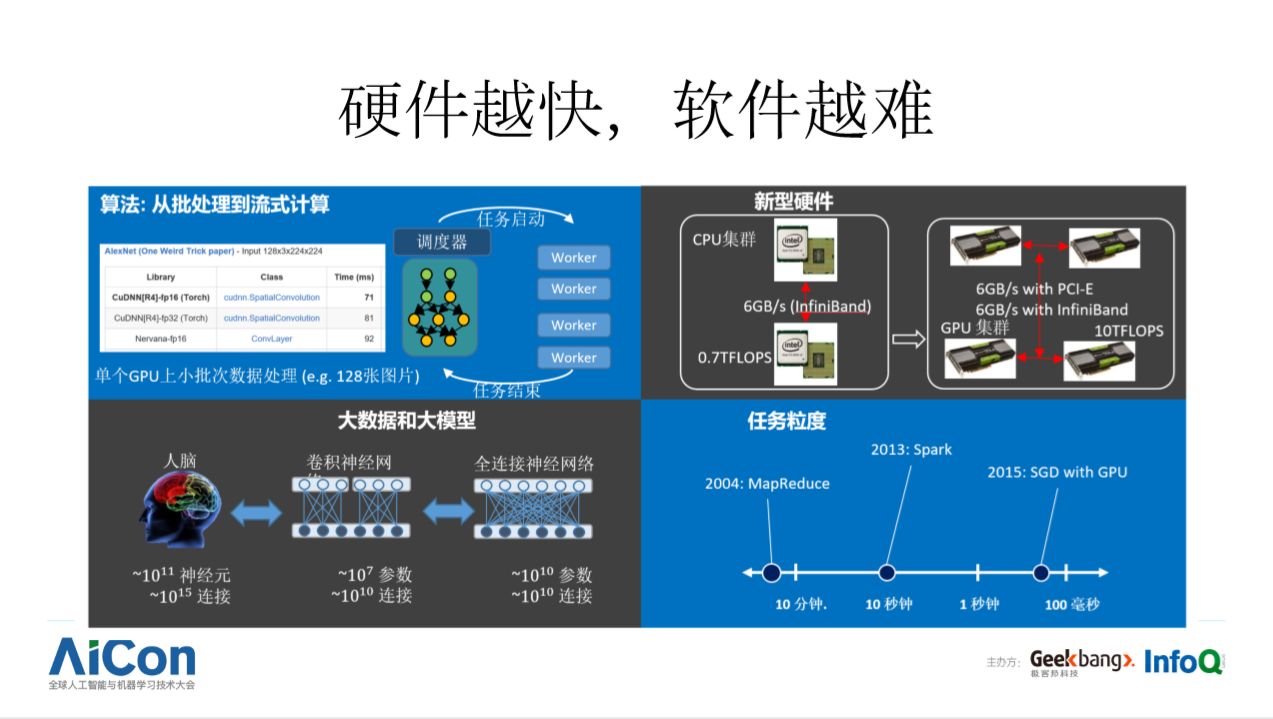
“硬件越快,软件越难”这个观点分享过多次,请参阅《深度学习平台技术演进》一文。
简要说:自上而下看,深度学习模型训练通常使用随机梯度下降(SGD) 算法,是更接近流式计算的一种负载:每处理一小片数据,就引起系统内部状态的变化;自下而上看,深度学习广泛采用异构计算技术,GPU 此类的设备吞吐率非常高,是 CPU 的 10 倍以上,意味着同样大小的计算任务,GPU 可以更快完成。从小粒度和快设备两方面看,深度学习训练中的计算任务粒度非常小,通常是数十毫秒到百毫秒级别。但是,设备互联带宽并没有实质改进,譬如同机内部 PCIe 或多机互联使用的高速以太网或 Infiniband 的传输带宽要低于 GPU 内部数据带宽一两个数量级。以上因素给分布式软件框架带来巨大压力,如果处理不好,就会造成设备利用率低,整体系统性能差的后果。打个比方,虽然高铁要比普通的列车开起来快很多,但如果让高铁每个车站都停两分钟,那么高铁并不会比普通列车快多少。

软件层和硬件层都是属于“计算力”范畴,软件层扮演了传统意义上操作系统(OS,如 Windows, Linux),或者互联网时代浏览器,或者移动互联网时代 android, ios,或者大数据时代 Hadoop 的角色,是上层应用的入口。同时软件生态又定义了底层硬件的角色,会影响底层硬件的发展和命运。
我们首先介绍深度学习框架中已经收敛的技术,理解了这些原理,每个人应该能开发出一个自己的深度学习框架。
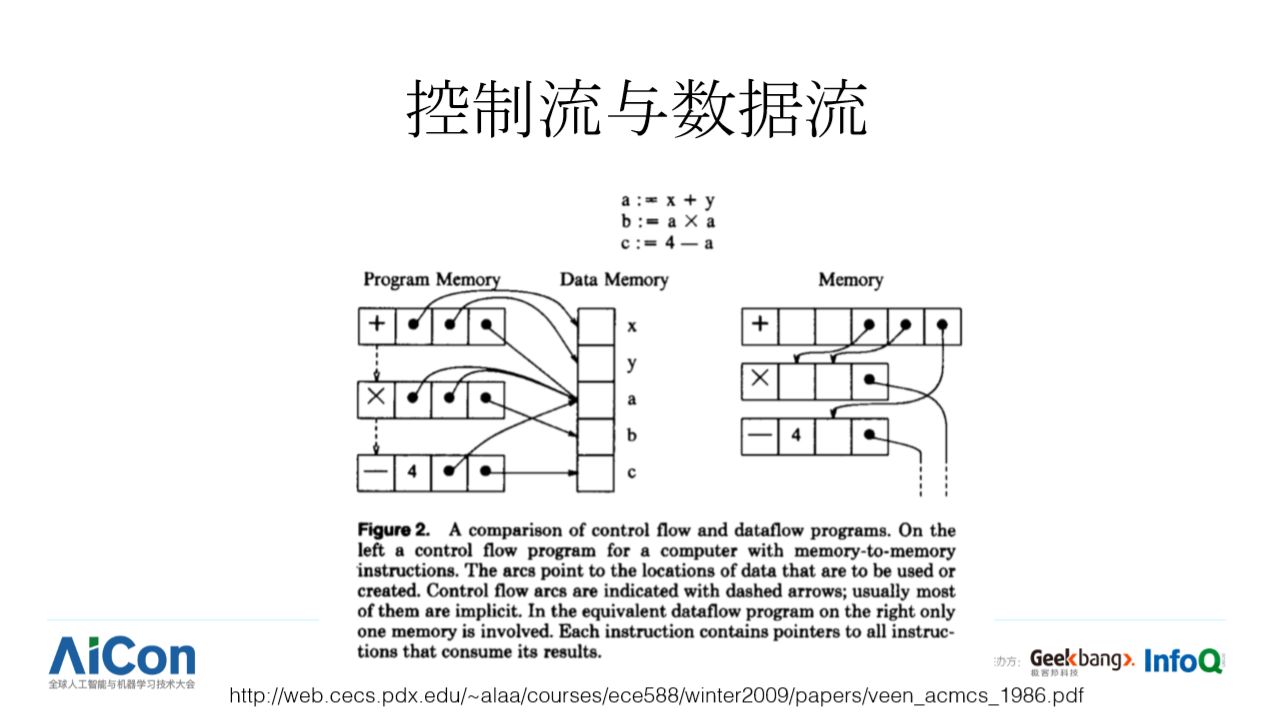
在进入技术细节之前,让我们先来理解两个很重要的概念:控制流(Control flow) 和数据流(Data flow),这俩概念事关后续一些关键的技术选择。以 a = x + y; b = a * a; c = 4 - a; 这样一段简单的程序为例,有两种编程模式,一种是以 C 语言为代表的命令式编程(imperative programming),语句的排列顺序隐式的刻画了程序的执行顺序(左图中虚线箭头表示执行顺序),有哪些语句可以并行执行,并不太明确,如果要在多个线程中执行这几条语句,为了防止出现多个线程间的读写冲突,可能要使用锁 (lock)等技术来保护某一个变量(某一段内存)防止出现 data race。
另一种编程模式是以 Lisp 为代表的函数式编程(functional programming),程序用一系列表达式来刻画,程序的执行不是按表达式的声明顺序来执行,而是从表达式中挖掘出各个表达式之间的数据依赖关系,把数据依赖关系用一个有向无环图来表示,图显式刻画了哪些表达式必须在另一些表达式之前求值,或者哪些表达式之间不存在依赖关系,可以并行执行。在并行和并发越来越多的世界,functional programming 和数据流程序正在越来越受重视。
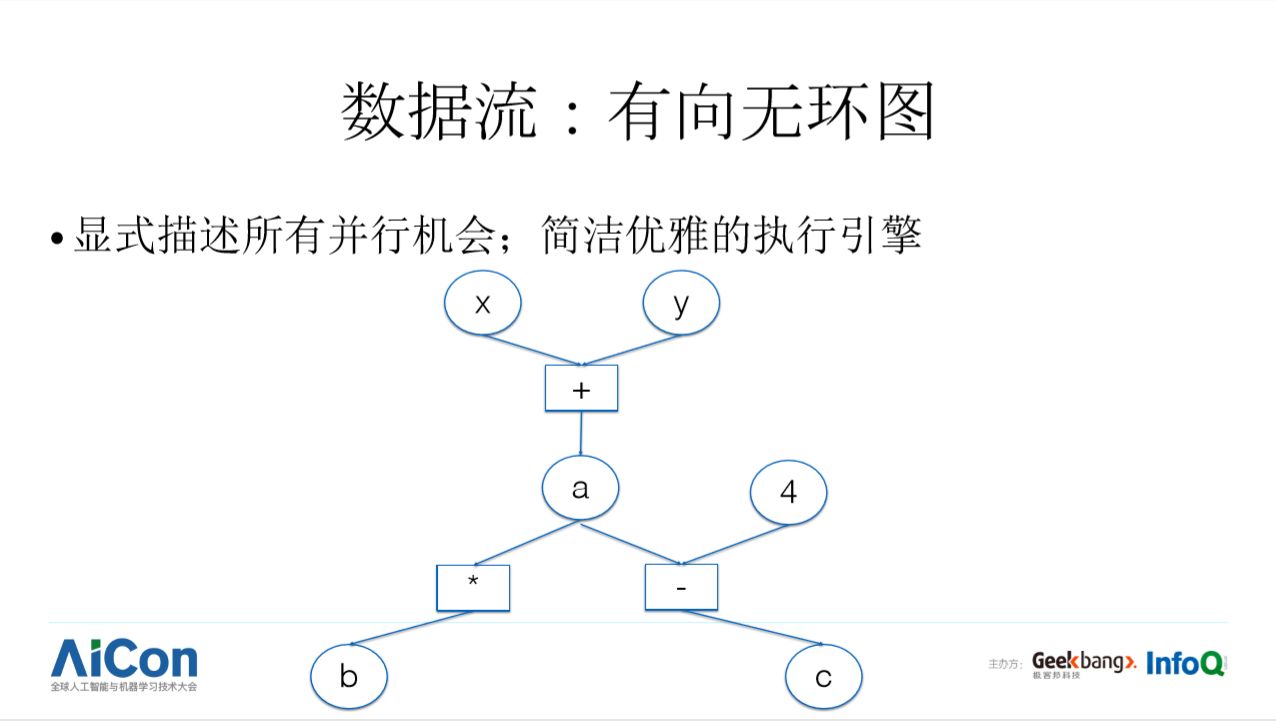
数据流模型一般表示成有向无环图(Directed acyclic graph, DAG)。譬如上一页的 a = x + y; b = a * a; c = 4 - a; 三个表达式可以表示成这样一张图,圆圈表示数据,方块表示算子。算子之间靠数据的生产和消费关系产生依赖。数据流模型的优势主要包括两方面:
(1) 表示上的好处,显式描述了程序中的所有并行机会;
(2)实现上的好处,数据流的执行引擎可以用很简单的方法支持并发和并行,而在控制流程序中对并发和并行的支持就要复杂的多。
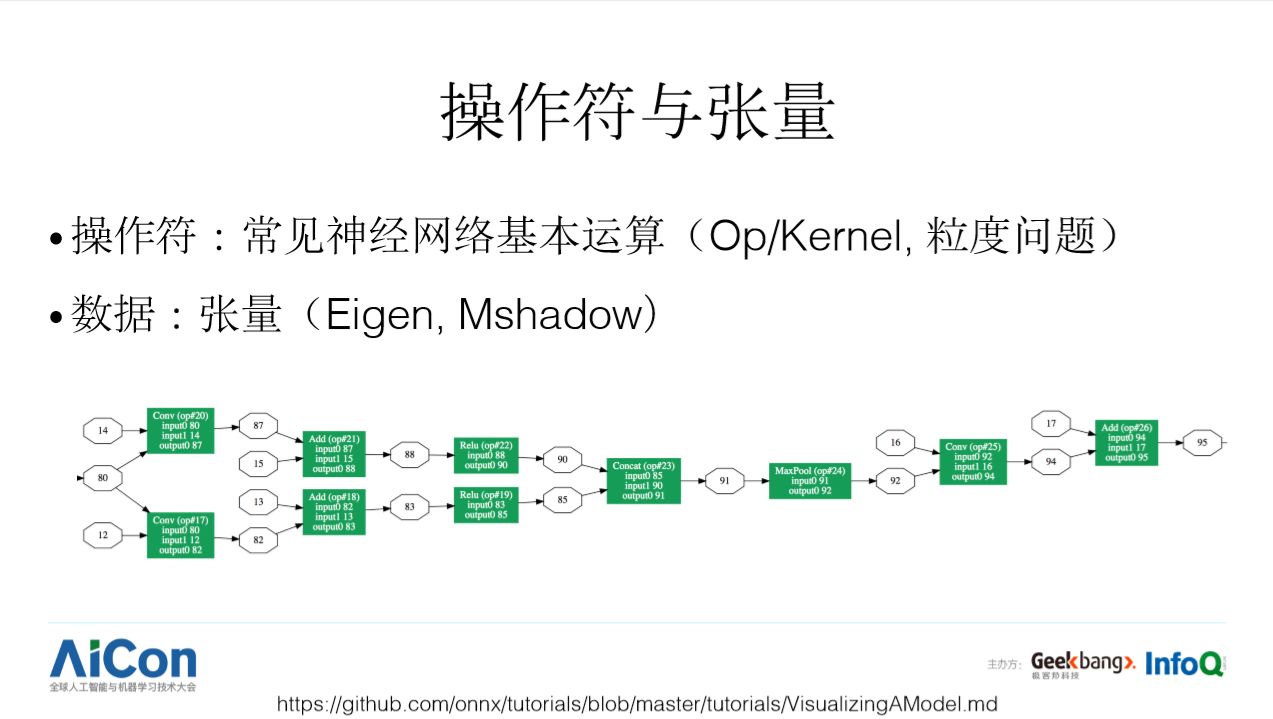
比较早的框架 Caffe 通过 Layer 这种抽象,运算和数据是放在一起的。TensorFlow 出现后,有向无环图中两个最基本的元素,操作符(运算)和张量(数据)是分开表示的,这种抽象模式也被其它框架所采用。具体地,Operator 一般是运算的描述,Kernel 是运算的具体实现,在实现上还要考虑操作符粒度的问题,理论上如果支持了最基本的加减乘除就可以通过图计算自动支持更加复杂的运算(如一些神经网络层次的计算),但粒度太细就对编译器要求特别高,当前编译器生成的代码不一定能超过工程师手工优化的代码,因此在多数框架里都是直接支持一些粗粒度的操作符,譬如卷积操作符,矩阵乘操作符等(值得注意的是 TensorFlow XLA, TVM 在细粒度操作符描述的图优化方面有一些好的实践)。对于张量计算的支持,业界也有很多技巧,譬如一般使用 C++ 模板元编程来实现,借助于编译时计算来提高运行时的效率,TensorFlow 等框架一般基于 Eigen 库,MXNet 使用自己开发的 Mshadow。
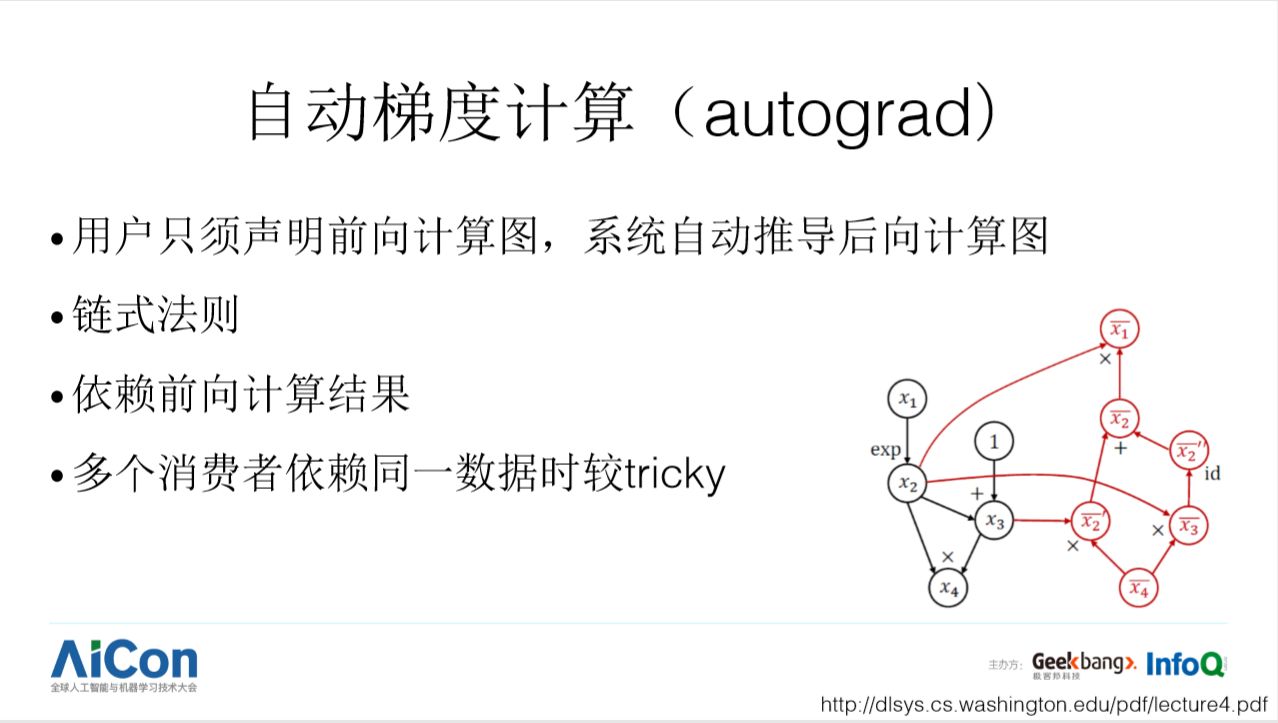
autograd 已经成为深度学习框架的标配。有了 autograd,用户写程序时,只需要描述前向计算是怎么做的,后向计算过程由系统自己推导完成。autograd 通过导数的链式法则实现,逆拓扑序搭建反向计算图。需要注意两点:
(1)后向计算过程可能会依赖于前向计算产生的中间数据,所以前向计算的中间数据可能要一直保持到对应的后向计算完成才能释放,否则就需要在后向计算时重新进行前向计算。
(2)如果前向计算过程有多个操作符消费了同一个数据,后向计算图时就需要把这几个操作符对应的梯度算子上传过来的误差信号进行累加。上面的示意图来自陈天奇在华盛顿大学一门《Deep learning systems》课程的课件,感兴趣的读者可以去课程网站获取更多资料。

给定用户输入的 DAG (称之为逻辑图,logical graph), 系统一般会利用编译器技术对图进行优化重写,上图罗列的一些优化技巧就不一一展开解释了。经过优化最终送到执行引擎执行的图叫物理图(physical graph),物理图可能和输入的逻辑图已经截然不同了。在 TensorFlow, PyTorch, MXNet, Caffe2 中都可以看到这些常见的优化办法。
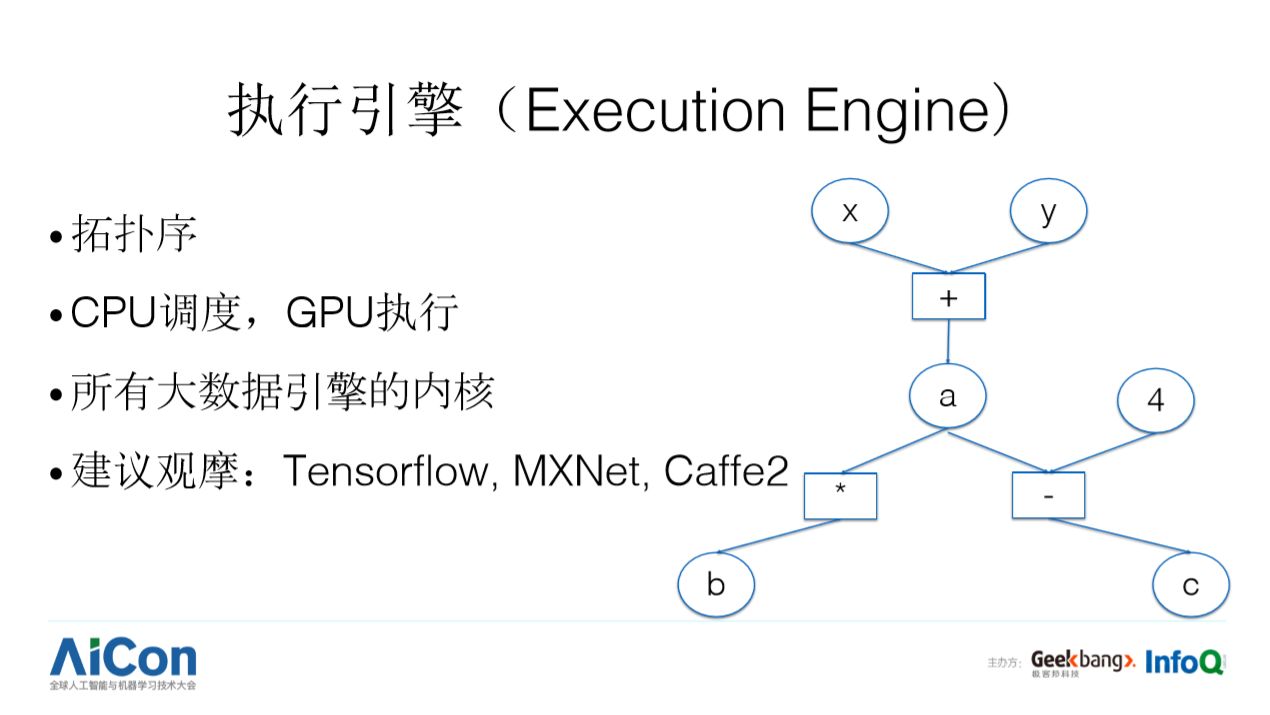
执行引擎是深度学习引擎的核心,基本原理是按拓扑序去执行算子 / 操作符,以上图为例,刚开始,乘法和减法运算无法执行,因为它们依赖的一个数据 a 还没有生成,引擎首先执行输入数据已经就绪的操作符,即加法,当加法完成后,执行引擎会从 DAG 中删掉已经执行的节点,然后发现乘法和减法的执行条件已经满足了,再去执行乘法和减法。事实上,当前所有大数据处理引擎的内核都是用这个原理实现的。在深度学习框架里,需要注意调度器是在 CPU 上执行的,而操作符的真实运算是在 GPU 上完成的,为了高效协调 CPU 和 GPU 之间的工作,在具体实现上有一些技巧。感兴趣的读者可以观摩 TensorFlow, MXNet, Caffe2 的执行引擎,也许你会发现有更好的实现办法。

从执行效率考虑,深度学习框架底层一般基于 C++ 开发,从易用性角度出发,也同时提供 Python 前端便于数据科学家使用。上图来自李飞飞教授在斯坦福的 cs231n 课程课件,展示了 Numpy,TensorFlow 和 PyTorch 对同一个简单神经网络训练过程的实现。
最左侧是 Numpy 代码,它的第一个特色是 imperative programming,是即时求值(eager evaluation),运行完 b = a + z 这条语句,b 的结果就出来了;第二个特色是没有 autograd,所以用户不仅要写前向计算的代码,还要把后向梯度下降的代码写出来,而 TensorFlow 和 PyTorch 都支持了 autograd,在代码中只需要写前向计算的过程,而后向计算过程是系统自动构建的。
TensorFlow 和 PyTorch 的区别则是,前者是 lazy evaluation,后者是 eager evaluation。在 TensorFlow 中,a = x + y; b = a + z 只是一些表达式,构建了一个数据流图,在执行 sess.run 时刻才会被真正执行,而且执行顺序不一定和表达式声明顺序一致。在 PyTorch 中,和 Numpy 原理类似,每条语句都是立刻执行,而且按照语句的排列顺序执行。看上去,PyTorch 的代码的确更加简洁,后文会进一步讨论延迟求值和即时求值的问题。

深度学习框架不只要解决易用性和高效性,还要方便部署运维。当前主流的深度学习框架都是基于检查点机制实现容错,Fail fast and warm start。深度学习框架还需要和上下游的开源工具链有机衔接,譬如分布式数据存储和数据预处理依靠 Hadoop 或者 Spark。部署运维,现在比较推崇基于 Docker 和 Kubernetes 相结合的方案。用户有时需要在多个框架之间切换,随着 ONNX 标准的推出,也大大便利了各种框架间的迁移,譬如使用 PyTorch 描述或训练的模型可以按 ONNX 规范导出,并被 Caffe2 框架使用。除了解决训练问题,深度学习框架还便于上线部署,为此 TensorFlow 推出了单独的 serving 模块。

下面我们探讨一些当前框架开发者还举棋不定或一筹莫展的技术问题。

Define-and-run 和 Define-by-run 近期关注度比较高,PyTorch 靠 Define-by-run 这个特性吸引了很多开发者。这个技术问题还有其它等价的描述,譬如 define-and-run,基本上和 lazy evaluation, 或 declarative programming, data flow 是一回事,通常意味着效率高。define-by-run 则基本上和 eager evaluation, imperative programming 或 control flow 是一回事,通常意味着灵活性。最近,很多框架在积极的推进支持 define-by-run 的运行模式,譬如 TensorFlow 增加了 eager evaluation,MXNet 推出了 gluon 接口,PaddlePaddle Fluid 也是一种 imperative programming 的用法。那这两种技术选择到底是怎么回事呢? 我们认为:
(1)Imperative programming 只不过是大部分程序员更加熟悉的编程方式,实现一个 imperative programming 的深度学习框架要比实现一个 declarative programming 的框架简单(最简只须实现 autograd,复杂点要支持 JIT)。传统的 lazy evaluation 框架增加 imperative programming 接口可以做到和 PyTorch 完全一样的用户体验,只不过要费些周章。
(2)只要 declarative programming 解决了调试困难等问题,就是对用户更友好的一种编程模式,用户只要在写程序时描述 what,而不需要关心 how,底层细节对用户透明,这是现代变编程语言的发展趋势。
(3)并行和并发代表着未来的趋势,那么数据流(声明式编程,函数式编程)代表着未来,data flow 模型在任务描述和系统执行引擎的简洁性上都有天然优势。

并行计算可以扩大处理任务的规模,也可以加速计算。具体到深度学习框架,总体情况是:数据并行已经得到解决,无论是哪个框架都能把适合数据并行的任务做到接近理想加速比,譬如计算机视觉领域各种 CNN 模型;数据并行和流水线并行不支持或支持的不好,导致在某些分布式训练场景,硬件利用率过低,训练周期过长。在集合通信(Collective communication operation)上有基于参数服务器的,MXNet、PaddlePaddle、TensorFlow、也有基于 MPI(或类 MPI)的,譬如 Caffe2。TensorFlow 在宏观架构上还区分了 Client、Master、Worker 节点,在重构版的 PaddlePaddle 也使用了类似的架构。
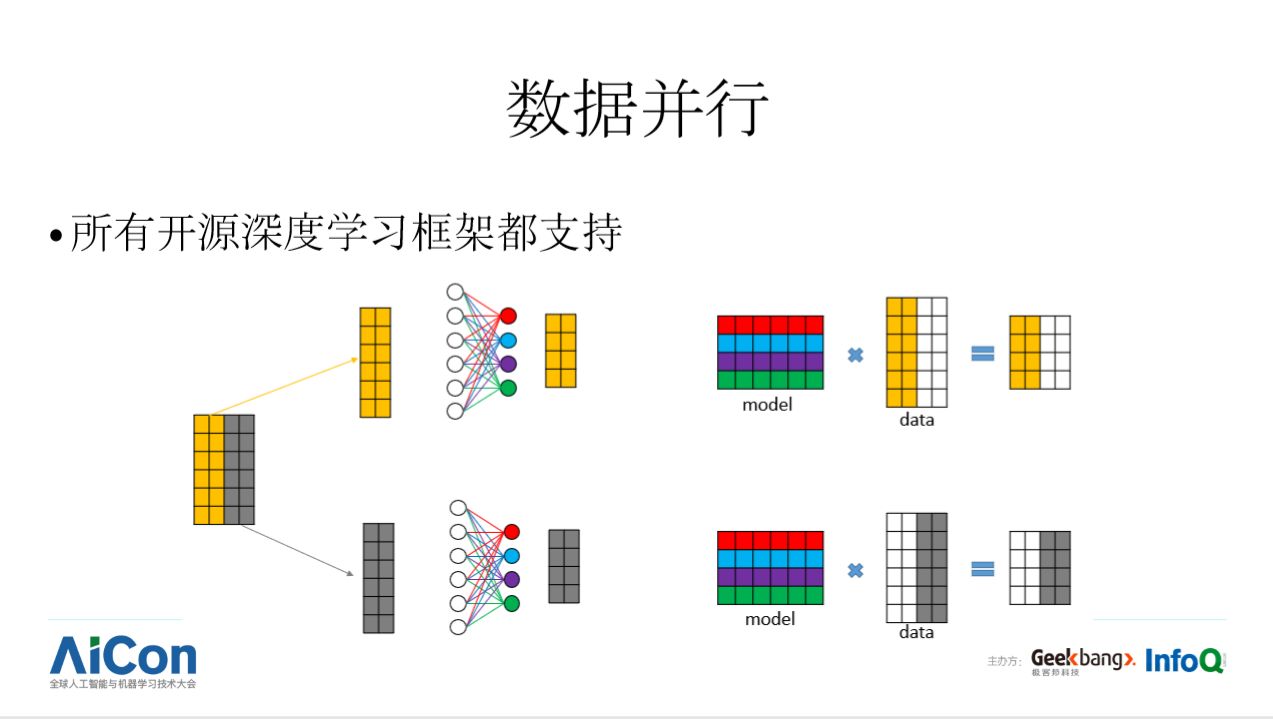
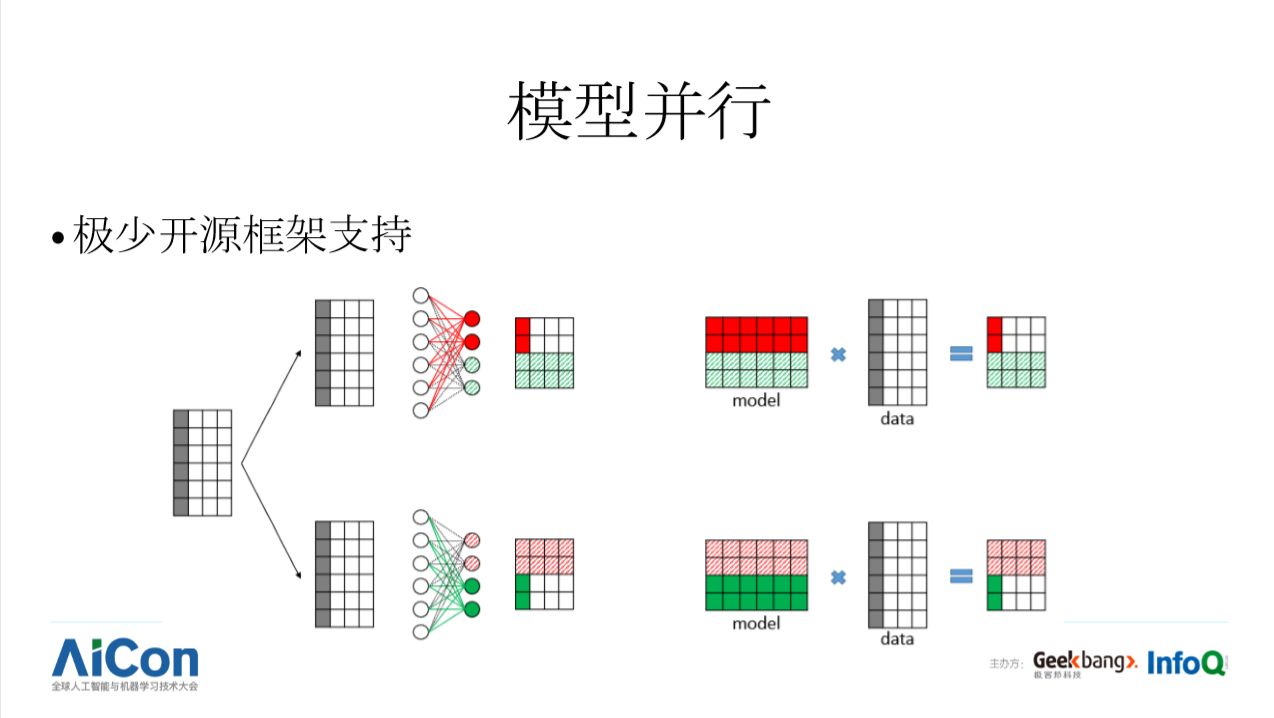
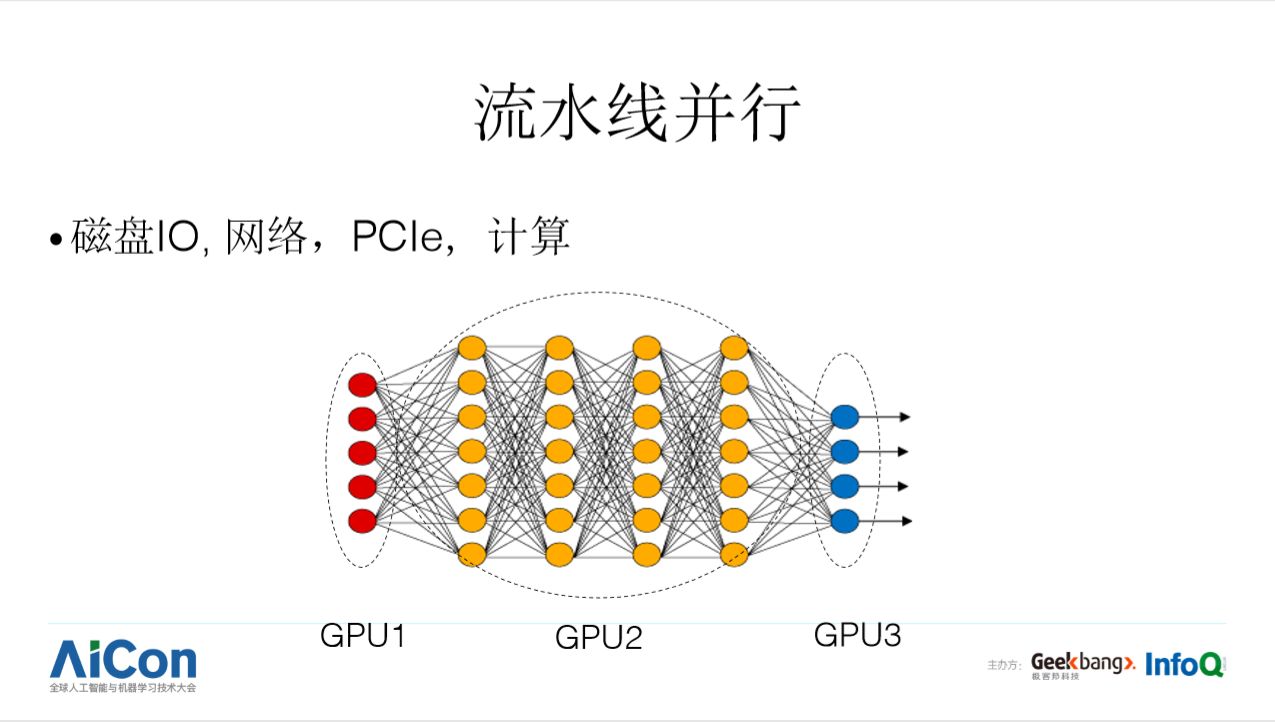
当神经网络模型或中间隐状态体积很大时,譬如超过一张显卡显存的容量,除了使用模型并行,还可以使用流水线并行。流水线并行有点像接力比赛,上图展示了一个简单的例子,第一个 GPU 做完第一层的计算后,把结果传递给第二块 GPU,第二块 GPU 完成中间四层的计算之后,把结果传递给第三块 GPU 完成计算。通常训练深度学习模型时,存在多个阶段,譬如把数据从磁盘加载到主存,把数据从主存搬运到 GPU, GPU 完成一个阶段的计算之后,可能还需要把数据通过网络传送到另一台机器。在这样多阶段任务中,流水线并行对于系统性能至关重要。可以注意到,大部分框架在 IO 阶段会做流水线并行,而在多个计算阶段,或者计算与通信阶段之间都没有相应支持。基于现有框架去支持模型并行,流水线并行还非常困难。

下面分享一些我们对各种框架的理解和判断,如果观点有偏差,敬请理解,欢迎批评指正。

以上框架用户比较多,开发团队技术实力雄厚。深度学习框架的先驱 Theano 已停止更新,它的 autograd 机制已经被这些现代框架所吸收;我们没有研究微软开发的 CNTK;Intel 收购的 Nervana 在开发一个新的框架 NGraph,也值得关注,不过它目前主要聚焦在单设备优化;DMLC 的 NVVM 和 TVM 放在 MXNet 内;有一个来自日本研究人员的框架 Chainer 也比较有特色,Python 前端非常清爽。

但 TensorFlow 的性能也是广受诟病,我们不大清楚 TensorFlow 在 Google 内部是不是性能卓越,在外部用户那里经常能听到用户抱怨 TF 慢,在学界和工业界很多 Benchmark 里,大家也喜欢拿 TensorFlow 做 baseline,譬如 CMU Eric Xing 教授团队发表的 Poseidon 论文,基于 TF 做了一系列优化之后,性能提高非常显著;Uber 团队改造了 TensorFlow 的分布式实现后(把 PS 换成 MPI),CNN 数据并行场景还能提高一倍的性能 (见 Uber Horovod https://github.com/uber/horovod) 。
从框架开发者的角度看,我们以为 TensorFlow 要解决性能问题,须有壮士断腕的决心,推翻一系列原有设计和实现。最后,TensorFlow 毕竟是功能最完整的框架,如果要训练大规模 RNN/LSTM,目前只能选择它,尽管要忍受一下很长的训练周期。

Facebook AI Lab 出品的 PyTorch 是深度学习框架的一匹黑马,靠 Eager evaluation 博得了大批深度学习研究人员的青睐。基于 Imperative programming 的理念和基于 Python 的语言构造(控制流)来搭建神经网络,灵活性高。NLP 领域常有一些动态图的需求,PyTorch 是首选。
我们认为在单机场景下,易用性和灵活性是最重要的用户需求,其它框架为了满足这样的需求,必须在原本为分布式设计的技术架构上做一些妥协,难以和 PyTorch 的最简内核竞争。PyTorch 为了克服 Eager evaluation 的一些问题,也在通过 JIT 来享受一些 Lazy evaluation 的优点,同时也在向分布式场景进军。如前文所述,在大规模分布式应用场景下,用户程序只能是 Lazy evaluation 风格,数据流的执行引擎在高并发高并行的场景有天然的优势,PyTorch 现在的设计实现距离这个目标还比较遥远。
 MXNet 开发团队实力雄厚,现在是 Apache 孵化项目,有 Amazon 官方支持加持。MXNet 的特点是包含很多正对 Geek 品味的实现技巧, 很值得喜欢钻研前沿技术的人去观摩。但不好的地方是,给人一种比较“杂”的感觉,让开发者感到困惑,譬如矩阵库有两套实现 Mshadow 和 NDArray。MXNet 在计算机视觉领域总是能紧跟前沿应用,一些新的模型出来社区总是第一时间支持。MXNet 有一些关联项目,譬如 NNVM 和 TVM,目前来看 TVM 更独特,NNVM 里实现的一些图优化技术在其它框架里也是有对应实现的,而 TVM 和 TensorFlow XLA 应该是处于一个层次:聚焦于单设备程序性能优化。基于 TVM、Halide、TensorFlow XLA ,用户可以在单设备上使用声明式编程,编译器自动生成高效的后端代码。
MXNet 开发团队实力雄厚,现在是 Apache 孵化项目,有 Amazon 官方支持加持。MXNet 的特点是包含很多正对 Geek 品味的实现技巧, 很值得喜欢钻研前沿技术的人去观摩。但不好的地方是,给人一种比较“杂”的感觉,让开发者感到困惑,譬如矩阵库有两套实现 Mshadow 和 NDArray。MXNet 在计算机视觉领域总是能紧跟前沿应用,一些新的模型出来社区总是第一时间支持。MXNet 有一些关联项目,譬如 NNVM 和 TVM,目前来看 TVM 更独特,NNVM 里实现的一些图优化技术在其它框架里也是有对应实现的,而 TVM 和 TensorFlow XLA 应该是处于一个层次:聚焦于单设备程序性能优化。基于 TVM、Halide、TensorFlow XLA ,用户可以在单设备上使用声明式编程,编译器自动生成高效的后端代码。
 Caffe 的用户还非常多,第二代 Caffe2 和第一代已经迥然不同了,但继承了一些简洁的品质在里面。框架的抽象非常简洁,不厚重,Op/Kernel 和引擎主要在 C++ 层实现,而复杂的图拓扑结构在 Python 层面处理。Caffe2 借鉴了 TensorFlow 对 Op/Kernel 的抽象,没有再使用之前 Layer 那种把数据和操作放在一起的设计。同样是 Op/Kernel 抽象,Caffe2 也不是简单的模仿, 代码看上去更加舒服。Caffe2 目前支持数据并行,曾创造了一个小时训练 ImageNet 的记录,对 Caffe 有感情的用户可以尝试。据了解,Caffe2 在 Facebook 内部承担了“工业级应用”和“部署”的重任,也开发了很好的移动端支持,这应该是 Caffe2 的特色。Caffe2 还有一个很有特色的技术,gloo 网络库是定制的 MPI 实现,有“去中心化”集群通信的味道,也便于支持流水线。
Caffe 的用户还非常多,第二代 Caffe2 和第一代已经迥然不同了,但继承了一些简洁的品质在里面。框架的抽象非常简洁,不厚重,Op/Kernel 和引擎主要在 C++ 层实现,而复杂的图拓扑结构在 Python 层面处理。Caffe2 借鉴了 TensorFlow 对 Op/Kernel 的抽象,没有再使用之前 Layer 那种把数据和操作放在一起的设计。同样是 Op/Kernel 抽象,Caffe2 也不是简单的模仿, 代码看上去更加舒服。Caffe2 目前支持数据并行,曾创造了一个小时训练 ImageNet 的记录,对 Caffe 有感情的用户可以尝试。据了解,Caffe2 在 Facebook 内部承担了“工业级应用”和“部署”的重任,也开发了很好的移动端支持,这应该是 Caffe2 的特色。Caffe2 还有一个很有特色的技术,gloo 网络库是定制的 MPI 实现,有“去中心化”集群通信的味道,也便于支持流水线。
 PaddlePaddle 最大的优势是百度内部在广泛使用,经受了实战检验。第一代 PaddlePaddle 是比较接近 Caffe,分布式并行也依赖于 Parameter server。最近一年,Paddle 团队在开展非常激进的重构。以我们的理解,重构版 PaddlePaddle 借鉴了很多 TensorFlow 的设计,所以 Paddle 能否解决 TensorFlow 面临的问题呢? 重构后的 PaddlePaddle 主推命令式编程接口,正像我们评价 PyTorch 时所说的,命令式编程接口固然亲民,但数据流表示在大规模分布式运行场景有天然的优势(表示能力和引擎实现复杂度方面),要很好的支持大规模分布式场景,深度学习框架最终要把“控制流”代码翻译成“数据流”代码在后台运行。
PaddlePaddle 最大的优势是百度内部在广泛使用,经受了实战检验。第一代 PaddlePaddle 是比较接近 Caffe,分布式并行也依赖于 Parameter server。最近一年,Paddle 团队在开展非常激进的重构。以我们的理解,重构版 PaddlePaddle 借鉴了很多 TensorFlow 的设计,所以 Paddle 能否解决 TensorFlow 面临的问题呢? 重构后的 PaddlePaddle 主推命令式编程接口,正像我们评价 PyTorch 时所说的,命令式编程接口固然亲民,但数据流表示在大规模分布式运行场景有天然的优势(表示能力和引擎实现复杂度方面),要很好的支持大规模分布式场景,深度学习框架最终要把“控制流”代码翻译成“数据流”代码在后台运行。

总体来看,深度学习框架开发的绝大部分技术秘密已经公开了,开发一个简单的深度学习框架没有那么难。但从另一方面看,要开发一个易用性和高效性都很卓越的框架是非常困难的,即使是世界上最优秀的开发团队也感到困难重重,克服这些问题需要艰苦卓绝的创新和坚持。


(1) 我们认为在计算机视觉领域也将迎来模型更大的场景,譬如把 Hinton 的 Capsule net 从 Cifar 推向 ImageNet 规模,模型大小就远超当前各种常见的 CNN, 这种情况必须把模型分裂到多个设备上去完成,也就是所谓的模型并行。而且学界很关心神经网络结构学习,元学习,也有必要去探索 CNN 之外的架构,在人脑视皮层尽管存在 CNN 这种神经元分层组织和局部感受野的神经元,但并没有所谓 weight sharing(神经元功能柱有类似的特异选择性,但不是严格一样),这种神经元之间的连接规模非常庞大,如果去掉这个约束会发生什么?如果深度学习框架不能支持模型并行,那么这种设想就只能在 Cifar, MNIST 这种数据集合上去探索,并不能在 ImageNet 甚至更大规模的数据上去探索,而有些规律是在大规模数据上才会“涌现”出来。
(2)未来,通用的深度学习框架会支持模型并行,而且用户使用模型并行易如探囊取物。
(3)深度学习向更多场景渗透,自然而然。
(4)一旦一项技术被验证,各种深度学习框架都会去拥抱它,支持它,正如今天很多框架在提供 imperative programming 接口一样,同质化是比较严重的,未来需要一些新的空气,新的思路去解决那些悬而未决的问题。
(5)在大数据和人工智能时代,数据积累到了临界点,工业界除了有数据存储,数据筛选这些需求,将普遍需要一个大脑(Brain),作为数据驱动业务的引擎,深度学习框架会像 Hadoop 一样经历一个从“旧时王谢堂前燕,飞入寻常百姓家”的过程。
今日荐文
腾讯系阅读 APP 的深度学习方法论
人工智能时代已来,什么才是最佳学习路径?
“AI 技术内参”将为你系统剖析人工智能核心技术,精讲人工智能国际顶级学术会议核心论文,解读技术发展前沿与最新研究成果,分享数据科学家以及数据科学团队的养成秘笈。
点「阅读原文」,免费试读精品文章
以上是关于开发易通用难,深度学习框架何时才能飞入寻常百姓家?的主要内容,如果未能解决你的问题,请参考以下文章
AI作画飞入寻常百姓家——stable diffusion初体验
AI作画飞入寻常百姓家——stable diffusion初体验