碎片时间 ▏Caffe 深度学习框架
Posted 启迪之星杭州
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了碎片时间 ▏Caffe 深度学习框架相关的知识,希望对你有一定的参考价值。
点击蓝字
卷积神经网络(CNN)已被证明在复杂的图像识别问题上非常有效。 本文将讨论如何使用Nallatech公司基于Altera OpenCL软件开发套件编程的FPGA加速产品来加速CNN卷积神经网络的计算。 可以通过调整计算精度来优化图像分类性能。 降低计算精度可使FPGA加速器每秒处理越来越多的图像。
Caffe 深度学习框架
Caffe是一个深度学习框架,具有表达力强、速度快和模块化的思想,由伯克利视觉学习中心(BVLC)和社区贡献者开发。网站 http://caffe.berkeleyvision.org/
Caffe框架使用XML接口来描述特定CNN卷积神经网络所需的不同处理层。 通过实施层的不同组合,用户能够根据其给定的需求快速创建新的网络拓扑。
Caffe框架最常用的处理层主要有:
• 卷积层:卷积层将输入图像与一组可学习的滤波器进行卷积,每个滤波器在输出中产生一个特征图
• 池化层:池化最大可以将输入图像分割成一组非重叠的矩形,并且对于每个这样的子区域,输出最大值
• 线性修正(ReLU)层:给定输入值x,如果x> 0,则ReLU层将计算输出为x,如果x <= 0则计算输出为negative_slope * x。
• IP/FC层:将图像视为单个向量,每个点对新输出向量的每个点有贡献
通过将这4层移植到FPGA,绝大多数正向处理网络可以使用Caffe框架在FPGA上实现。要访问加速卡上的FPGA版本的代码,用户只需要更改Caffe XML网络描述文件中的CNN - 卷积神经网络层的描述,这等同于修改FPGA代码版本。
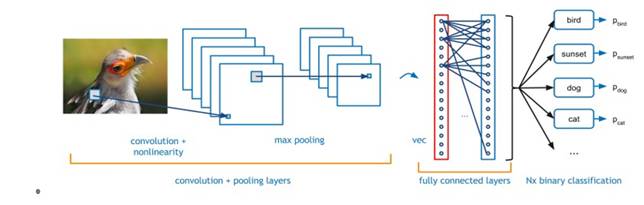
图1:典型的CNN - 卷积神经网络的示例图
ImageNet卷积神经网络
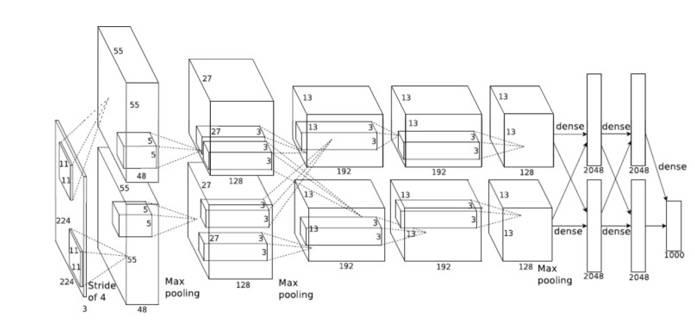
图2:ImageNet CNN - 卷积神经网络
ImageNet是一个备受推荐且使用最为广泛的CNN卷积神经网络,具有免费的训练数据集和基准。 本文讨论了针对ImageNet CNN - 卷积神经网络的FPGA实现,当然这里使用的方法同样适用于其他网络。
图2显示了ImageNet CNN - 卷积神经网络所需的不同网络层。 有5个卷积和3个FC层。 这些层占用该网络处理时间的99%以上。 对于不同的卷积层,有3种不同的滤波器尺寸,分别为11×11,5×5和3×3。 因为每个层的计算时间根据所应用的滤波器的数量和输入图像的大小而不同,所以为不同的卷积层优化不同的层将效率是比较低的。 为了避免这种低效率,使用最小的滤波器(3×3)作为较大卷积块的基础。 由于它们处理的输入和输出特征的数量,3×3卷积层是计算量最大的
较大的滤波器尺寸可以用较小的3×3滤波器的多次表达。 这虽然会降低内核处理的效率,但允许不同层之间的逻辑重用。 这种方法的成本如表1所示。

表1:卷积核效率
3×3卷积核也可以被FC层使用。
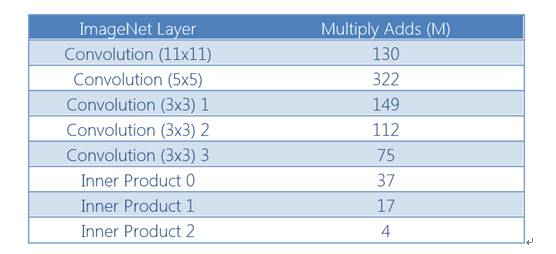
表2:使用3×3滤镜时的ImageNet层计算要求
FPGA 逻辑器件
FPGA器件具有两种处理资源类型,即DSP和ALU逻辑。 DSP逻辑是针对大型(18×18位)浮点乘法或乘法运算器优化的专用逻辑。 这比使用ALU逻辑更有效率,因为这样的乘法资源消耗很大。 鉴于DSP操作中的乘法通用性,FPGA供应商为此提供了专门的逻辑。 Altera做的更进一步,允许重新配置DSP逻辑来执行浮点运算。 为了提高CNN卷积神经网络处理的性能有必要增加在FPGA中实现的乘法次数。 另一种方法是降低位精度。
Bit 精度
大多数CNN实现使用浮点精度来进行不同的层计算。 对于CPU或GPU实现这不是问题,因为浮点IP是芯片架构的固定部分。 对于FPGA来说,逻辑元素不是固定的。 Altera的Arria 10器件嵌入了可以用于固定点乘法的浮动DSP模块。 实际上,每个DSP组件可以用于两个独立的18×19位乘法。 通过使用18位固定逻辑执行卷积,与单精度浮点相比,可用运算符的数量加倍。
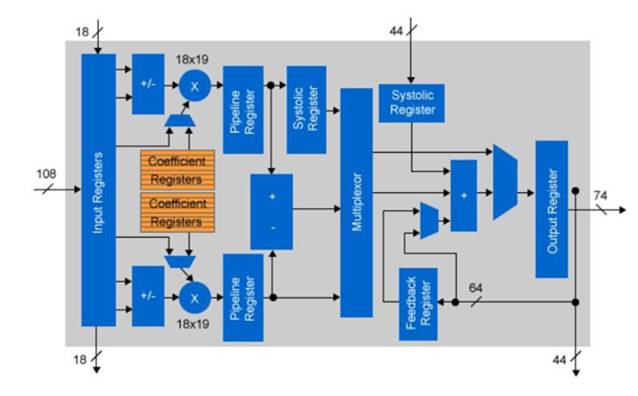
图3:Arria 10定点DSP配置
根据CNN卷积神经网络的应用性能要求,可以进一步降低位精度。 如果乘法的位宽可以减少到10位或更少,则可以仅使用FPGA ALU有效地执行乘法。 与使用FPGA DSP逻辑相比,这样可以增加可乘数。
OpenCL库函数
Altera提供了将用户定义和优化的IP组件纳入其编译器工具流程的能力。 这允许使用标准库符号创建和包含这样的优化功能。 库组件允许有经验的HDL程序员以汇编语言程序员创建的方式创建高效的实现,并且包含x86优化的函数。
对于ImageNet使用的CNN - 卷积神经网络层,简单的定点实现可以采用10位系数来获得的最小减少量,这相对于单精度浮点运算保持小于1%的误差。 因此创建10位3×3卷积的优化库,受FPGA资源的限制,这个库被实现(复制)多次。
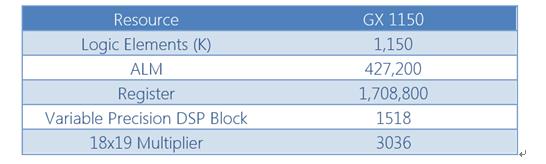
图4:Arria 10 GX1150资源
Arria10最大的可用设备是GX 1150.该设备具有约512个卷积块的资源以及应用程序控制逻辑。
Nallatech 510T硬件平台
卷积内核的并行运算增加的数量加大了对输入带宽要求。 为了避免全局内存成为瓶颈,一次计算多个图像时候可以为每个不同的图像重新使用卷积滤镜权重。 这对于FC层是特别重要的,其中对于每个点对点连接需要新的一组滤波器权重,其中从全局存储器检索权重的瓶颈是瓶颈。 幸运的是,卷积层重用了特征图像中每个点的权重数据。 最小卷积特征图像为13×13像素,因此卷积权重仅在最坏情况下每169次迭代更新一次。

图5:Nallatech 510T加速器
选择硬件平台Nallatech 510T实现CNN - 卷积神经网络,Nallatech 510T是 与大多数服务器平台的GPU相兼容的FPGA加速卡,旨在兼容英特尔至强Phi或GPGPU加速器。 Nallatech 510T具有两个Altera Arria 10 GX 1150 FPGA,具有60 GBytes / sec的外部存储器带宽用于加载权重、输入和输出数据。 510T的典型功耗仅为150W,不到高端GPU功耗的一半。 使用10位系数数据进行FPGA实现的另一个好处是可以从全局存储器读取的重量数据量与浮点数据的三倍。
使用Nallatech 510T加速器,可以处理16个并行图像,每个图像具有并行处理的64个内核。 这是通过并行生成8个输出特征和8个像素来实现的。 总共提供了1024个并行的3×3内核。
在我们的实现中,我们为1个图像创建了一个OpenCL内核系统,并在FPGA资源限制的情况下复制了这个多次。 卷积权重对于每个图像重新使用,因此当缩放到多个并行图像时,对全局内存要求的增加最小。
结果分析
通过应用上述FPGA系统,每个图像需要9毫秒才能被FPGA分类。 使用510T处理的12个并行图像,平均每个图像的时间为748 微秒。 每天超过1.15亿张图片。
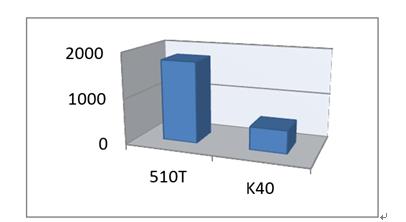
图6:每秒分类的图像。 Nalllatech 510T对Nvidia K401
功耗分析
与Nallatech 510T的150W相比,Nvidia K40 GPGPU的标称功耗为235W。 这使得FPGA实现与GPU相比具有显着的性能/功耗优势。
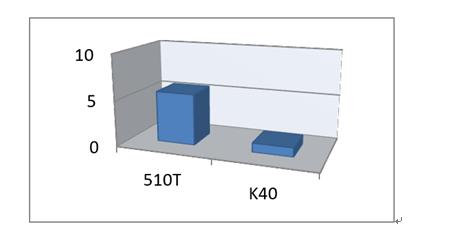
图7:相对图像/功率 Nallatech 510T对Nvidia K401
1 Caffe implementation of ImageNet. http://caffe.berkeleyvision.org
结论及应用
FPGA架构的独特灵活性允许将逻辑精度调整到特定网络设计所需的最小值。 通过限制CNN卷积神经网络计算的比特精度,可以显着增加每秒可处理的图像数量,从而提高性能并降低功耗。
FPGA实现的非批处理方法允许在9毫秒(单帧周期)中的对象识别,对于低延迟至关重要的情况是理想的,例如障碍物避让,可以做到大于100Hz的帧速率分类图像。
FPGA实现证明内在的可扩展性可以用来在越来越小的和较低功耗的FPGA上实现复杂的CNN卷积神经网络,虽然这样牺牲了一些性能。 在极低功耗FPGA器件上实现不太苛刻的应用特别适用于嵌入式解决方案。 比如在接近传感器端计算场景。

图8:用于近距离传感器处理的微型封装模块(FPGA,存储器和支持电路)
把传感器和FPGA一起做到硬件封装里,这样在传感器端就具备了CNN - 卷积神经网络图像识别功能,从而确保低延迟以及优化传感器和主机之间的带宽。

Jack
北航毕业,Nokia工程师,比较关注FPGA在深度学习领域的应用,希望能够和更多的朋友一起交流学习。

相关历史消息,点击了解
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
USSTAR International
Entrepreneurial Base

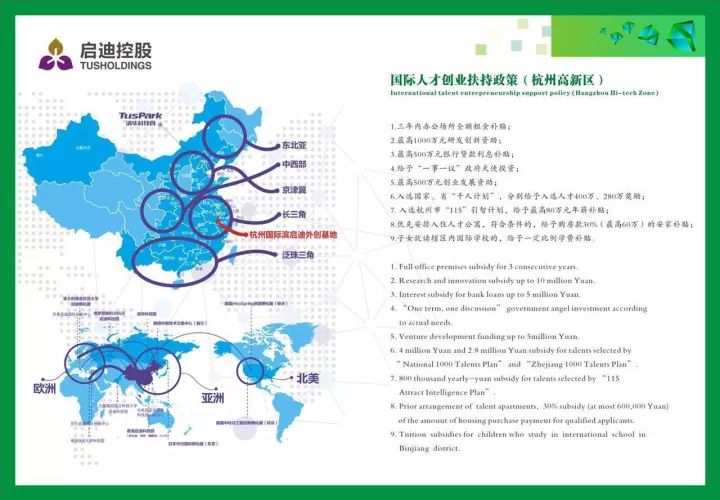
USSTAR (Hangzhou·Binjiang)
启迪之星(杭州·滨江)
启迪之星(杭州·滨江)是由清华科技园启迪控股,浙江清华长三角研究院和中国普天东方通信战略合作设立的孵化器。
启迪之星(杭州·滨江)搭载一个中心和两个平台,为入驻孵化器项目提供从产品设计、中试到产业化全方位服务。
同时,启迪之星(杭州·滨江)搭建创业导师、创业大咖与入驻项目团队一对一帮扶指导的桥梁。
2016年,启迪之星(杭州·滨江)被评为杭州市市级孵化器。
2017年3月28日,启迪之星(杭州·滨江)建设杭州国际滨启迪外创基地,专门致力于为在杭外国人创业提供科技孵化服务,并得到政府在内的社会各界的广泛关注与大力支持。
2017年7月24日,在各级政府领导、杭州外国专家代表以及多家媒体的见证下,杭州国际滨启迪外创基地作为杭州国际人才创业创新园三试点之一与滨江区签署合作协议。
2017年9月5日,杭州国际滨启迪外创基地在高新区(滨江)政府领导的见证下发布了杭州市第一本外创服务手册,汇总了外国人在杭工作创业指南。
联系人:蔡梦琪 15068773916
邮箱:caimq@tusstar.com
网址:www.tusstar.com
编辑、排版:Chua
以上是关于碎片时间 ▏Caffe 深度学习框架的主要内容,如果未能解决你的问题,请参考以下文章