利用深度学习框架Tensorflow做图像识别(基于阿里云PAI)
Posted 傲飞的机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用深度学习框架Tensorflow做图像识别(基于阿里云PAI)相关的知识,希望对你有一定的参考价值。
实验介绍
听说深度学习很火,本座就试着用阿里云的深度学习框架进行图片识别的实验。
这个实验,采取标准数据集CIFAR-10(包含了10个不同分类的60000张图片),使用流行的深度学习框架Tensorflow训练一个图像识别的模型,该模型可以识别出新图片中的内容属于哪一个分类。
操作流程
实验使用深度学习框架Tensorflow,根据输入的数据集CIFAR-10训练一个分类模型,然后输入新的图片,让该模型去识别出这些图片中的内容属于哪个分类。
数据介绍
实验使用的训练数据集为CIFAR-10,该数据集是由几个深度学习的大牛(Alex Krizhevsky, Vinod Nair, Geoffrey Hinton)搜集整理的,包括了60000张图片,共十个分类,包括飞机、汽车、鸟、猫、鹿、狗、青蛙、马、轮船、卡车共十个分类,每个分类都有约6000张的图片,其中5000张用于训练,1000张用于测试评估。图片的大小为32*32。
数据集的数据存在一个10000*3072 的数组中,单位是uint8s,3072是存储了一个32*32的彩色图像(每个图像存三组数,前1024位是r值,中间1024是g值,后面1024是b值。所以其大小为1024*3=3072)。
数据我在阿里云官网下载下来:
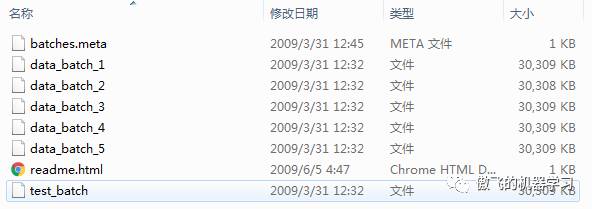
我们看到的文件是按照上述格式处理过的文件,也可以通过一些解压脚本或者工具,将图像复原。
本例中用来预测的图片为bird_bullocks_oriole.jpg,可以通过本实验的附件得到。该图片中有一只鸟:

模型训练完后,使用模型去识别该图片中的内容,看能否识别出该图片属于“鸟”这个分类的图片。
开始实验
1.首先登陆PAI平台
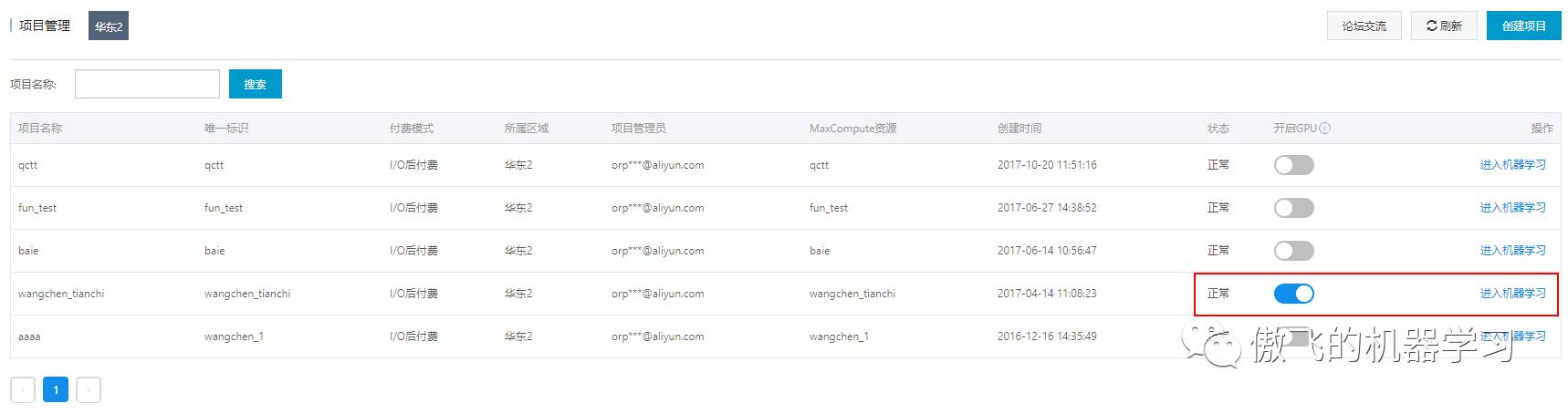
然后选择开通了GPU的项目(深度学习需要有GPU,没有的话点击开通下)
9.上传数据到文件夹中。点击cifar-10-batches-py,进入该文件夹: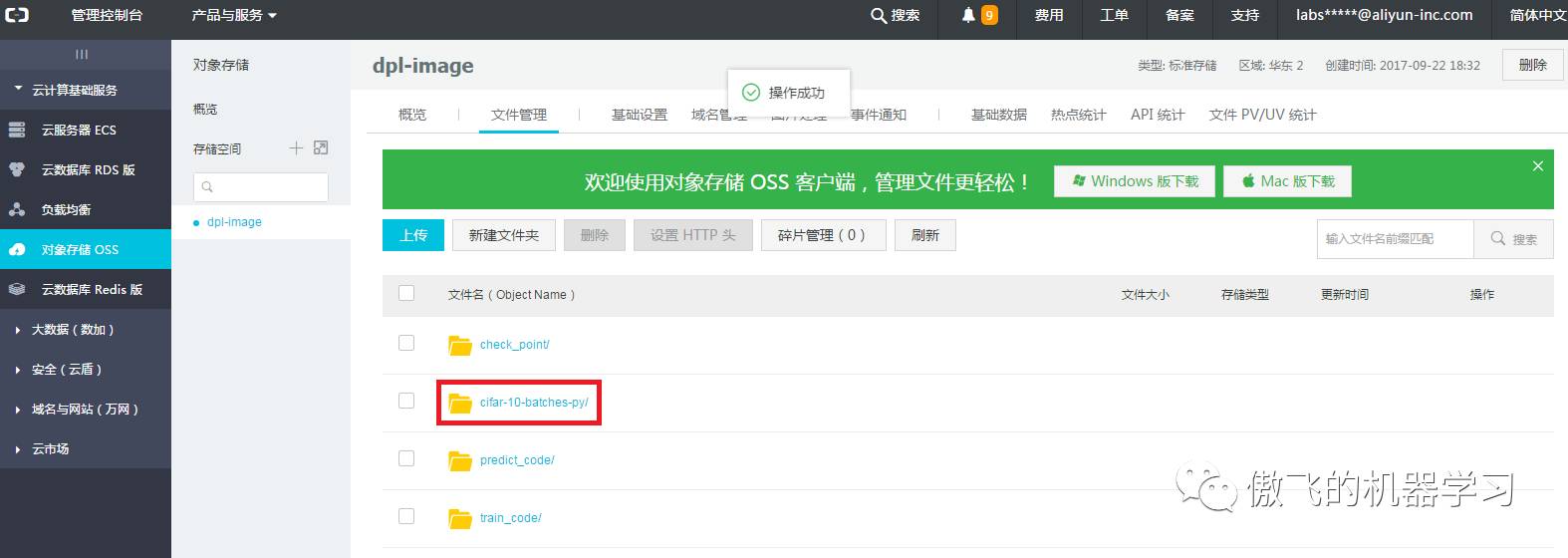
点击上传:
在上传选项中点击直接上传:
在打开窗口中,找到解压后的目录cifar-10-batches-py,选中其中所有的文件,点击打开,上传文件:
照此步骤,将文件bird_bullocks_oriole.jpg上传到文件夹cifar-10-batches-py中;
照此步骤,将文件cifar_pai.py上传到文件夹train_code中;
照此步骤,将文件cifar_predict_pai.py上传到文件夹predict_code中.
上传完成后,查看文件夹中内容如下:
cifar-10-batches-py中: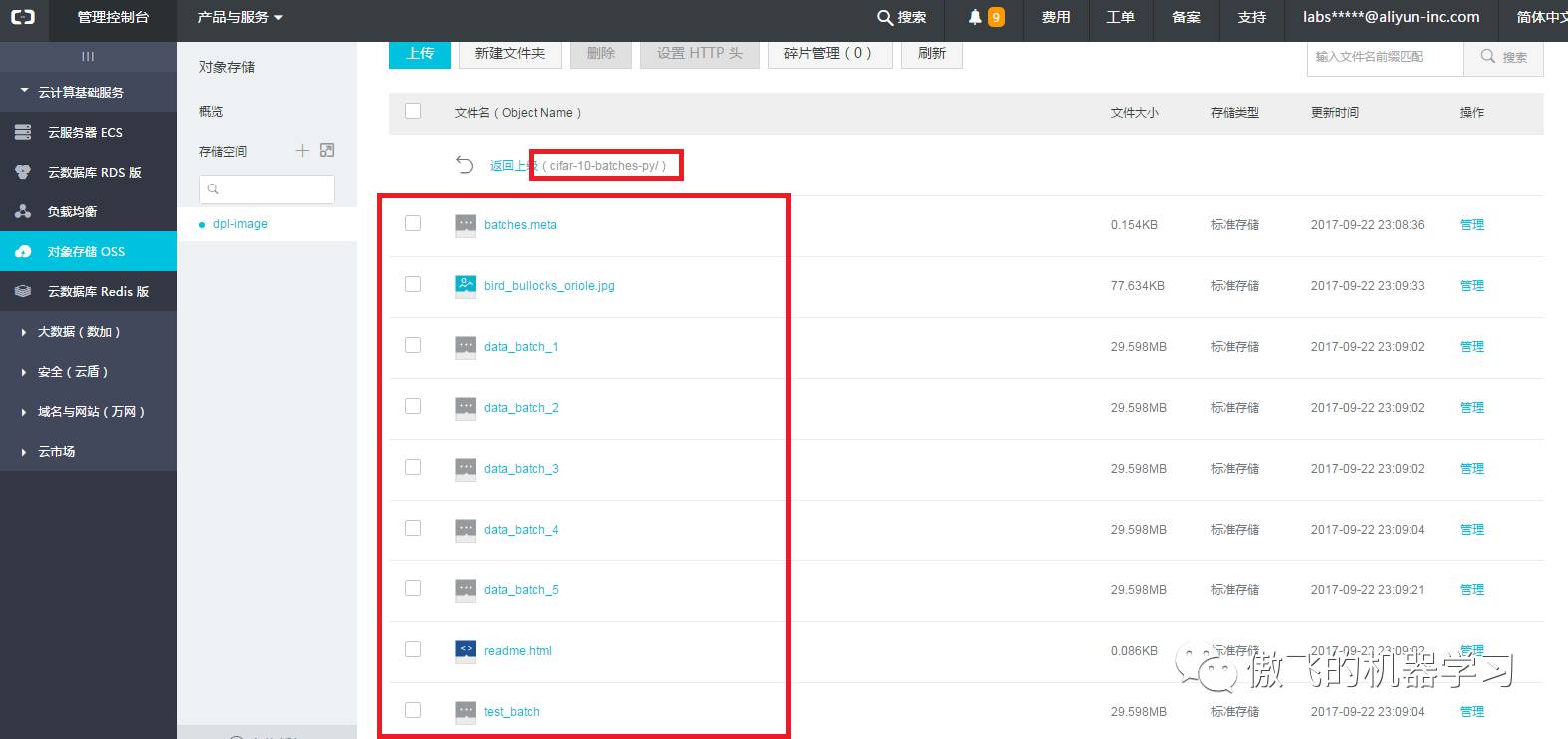
predict_code中: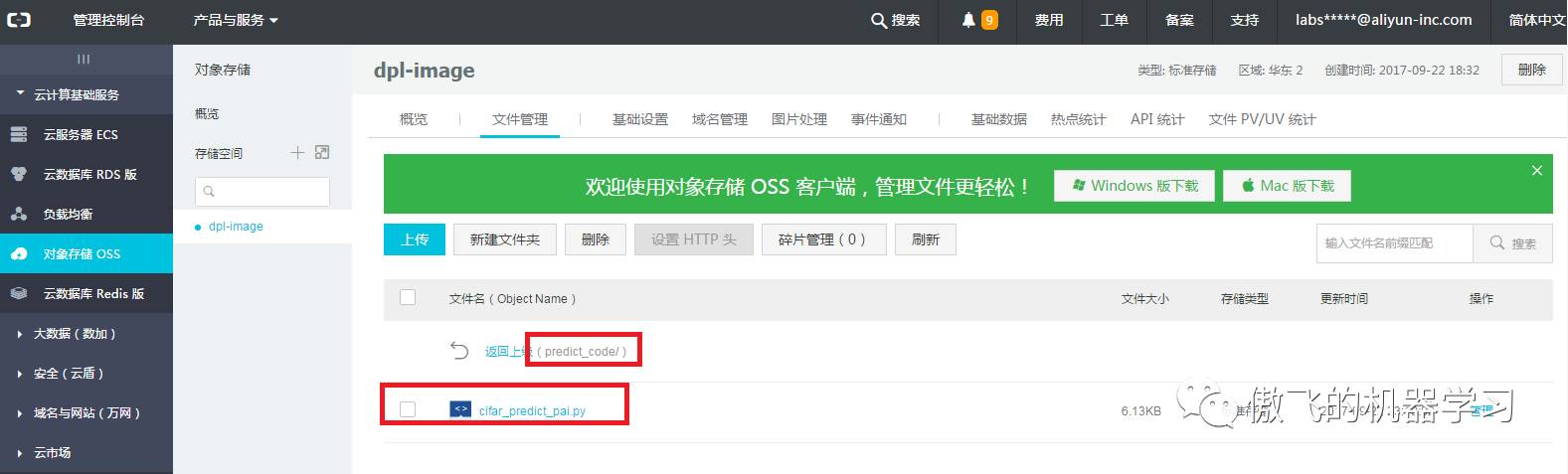
train_code中: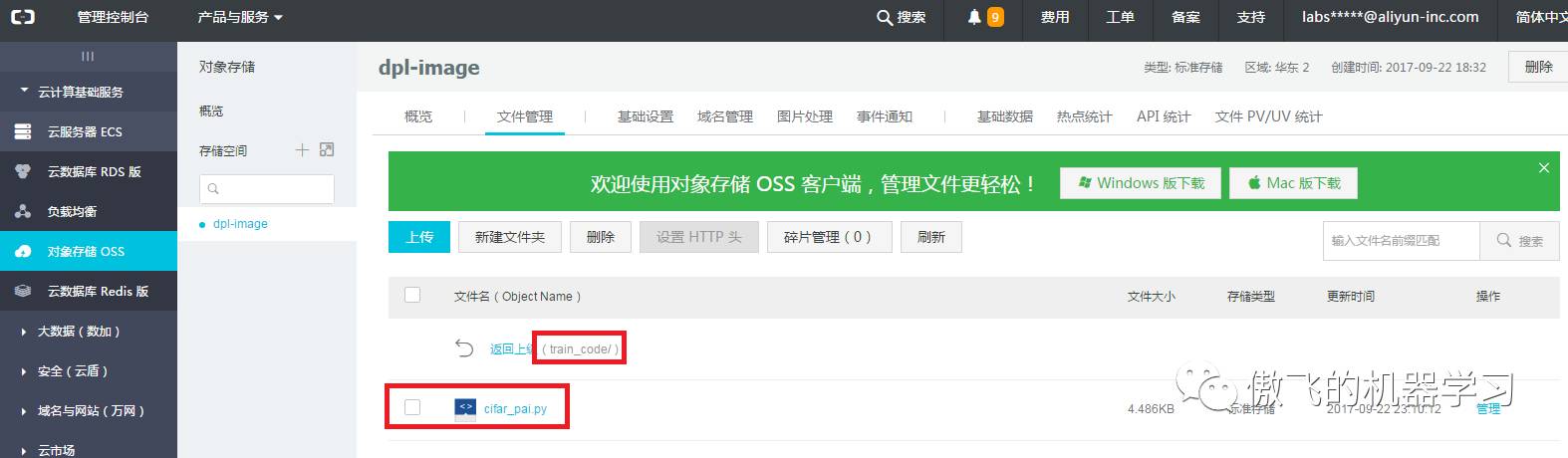
至此,数据和脚本准备完成。本例中深度学习用到的数据和脚本,已经由离线(本地文件)转为在线(将数据和脚本加载至云端的OSS中),后续会直接从OSS访问这些数据和脚本。
正式开始用深度学习做实验:
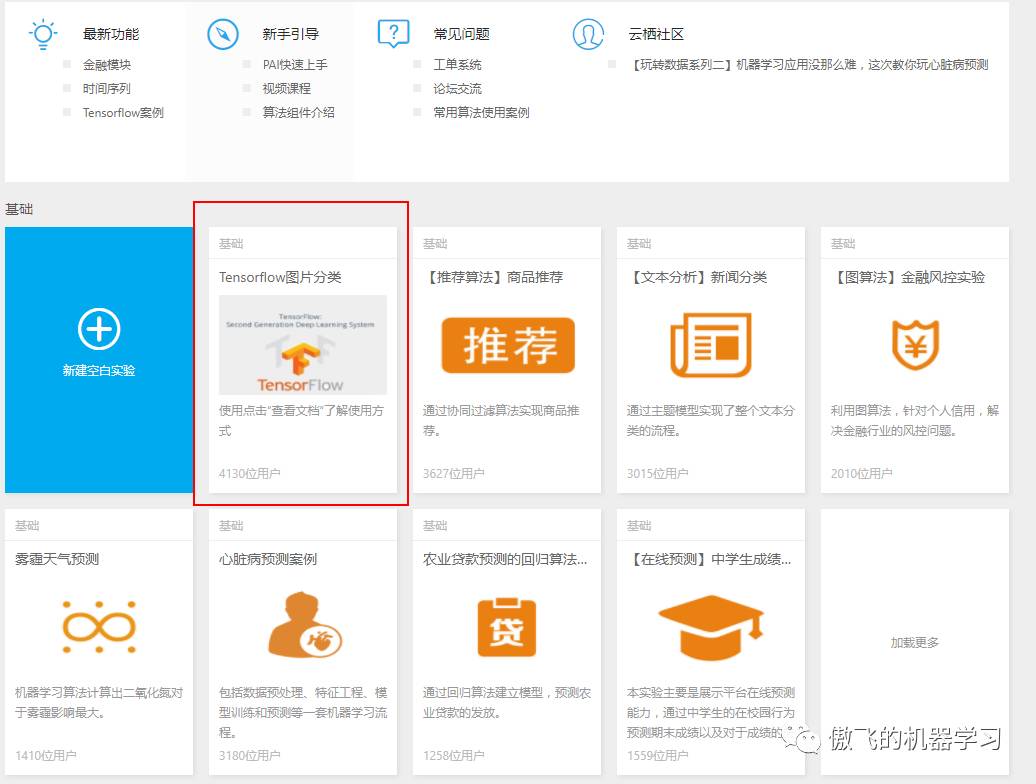
1,用模板创建实验:
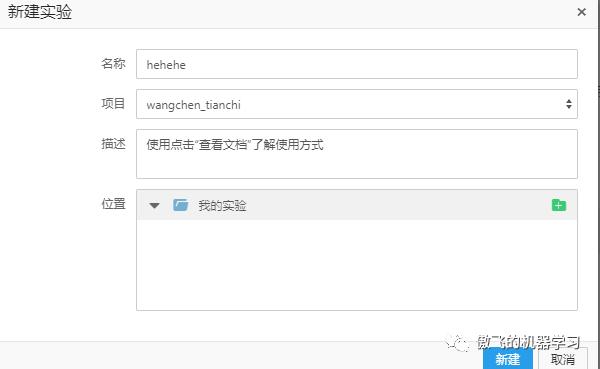
2.填写实验名称,指定项目为前面步骤创建的项目,点击新建:
3.页面跳转至实验开发面板
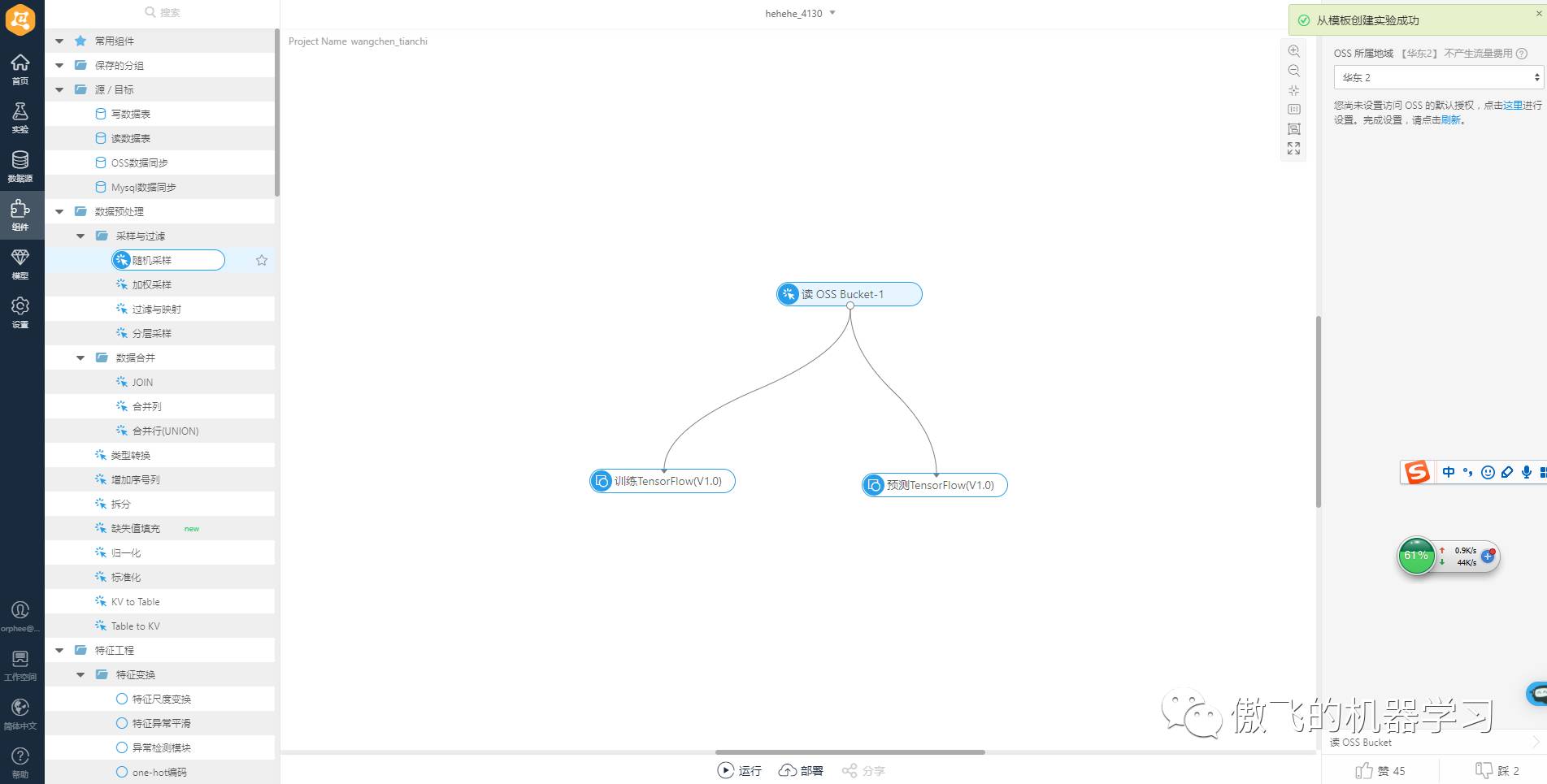
4.设置Python代码文件位置。在参数设置Tab页中,点击Python代码文件后的文件夹图标: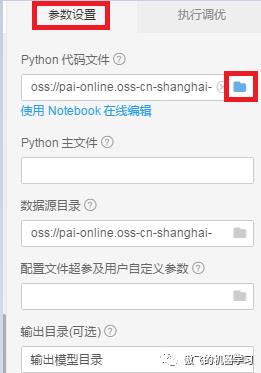
在OSS资源选择中,选择之前上传过数据和代码的bucket: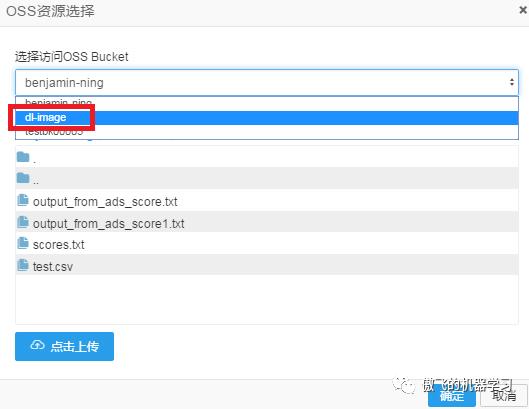
上一步完成后,选择文件框中的内容会刷新,刷新后的结果中,双击train_code: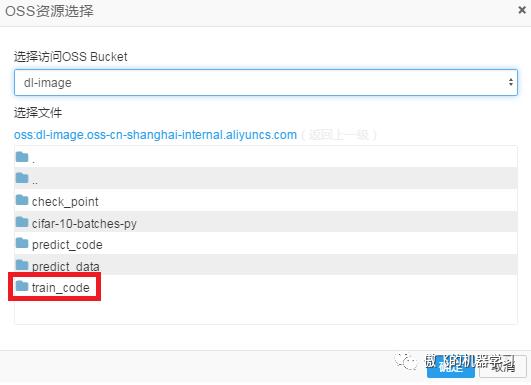
选中.所在行(即选中当前目录),点击确定: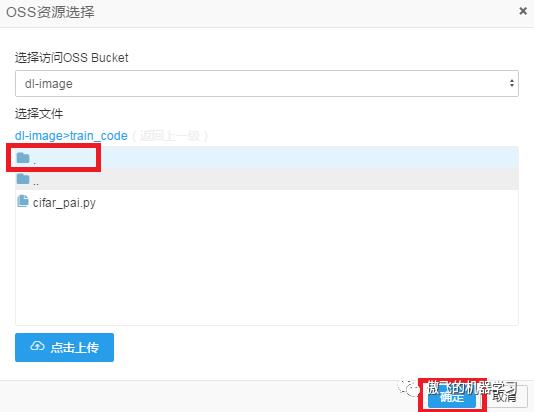
返回参数设置页面后,可以将设置完成的路径拷贝出来查看,其值应该设置成为了:oss://dl-image.oss-cn-shanghai-internal.aliyuncs.com/train_code/【注】这个值依赖于自己试验环境中的bucket名字,注意上述路径中标红的部分一致即可。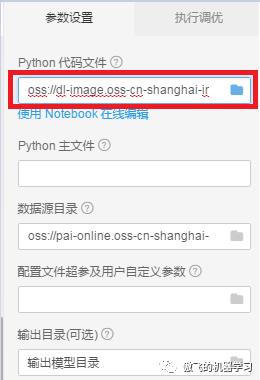
7.设置数据源目录。点击数据源目录后的文件夹图标: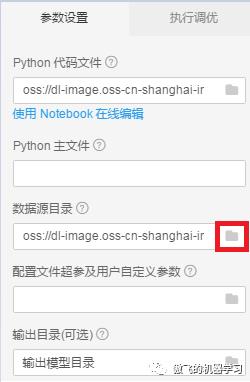
在OSS资源选择中,选择之前上传过数据和代码的bucket:
上一步完成后,选择文件框中的内容会刷新,刷新后的结果中,双击cifar-10-batches-py: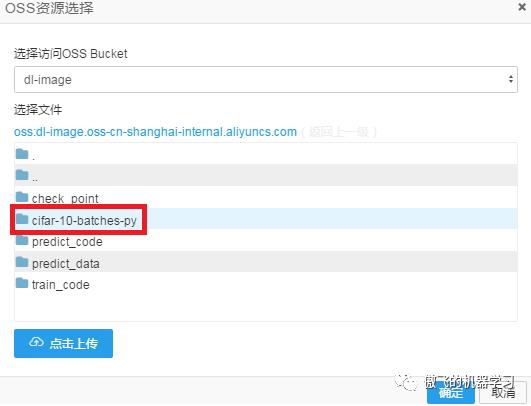
选中.所在行(即选中当前目录),点击确定: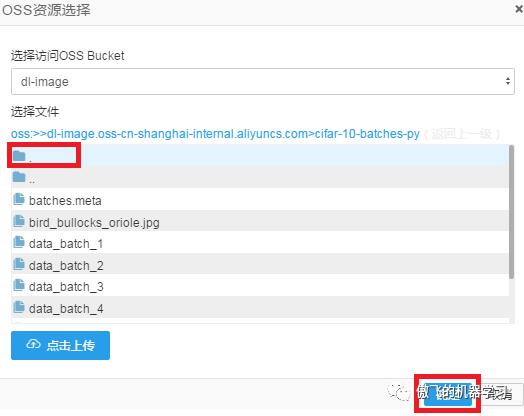
返回参数设置页面后,可以将设置完成的路径拷贝出来查看,其值应该设置成为了:oss://dl-image.oss-cn-shanghai-internal.aliyuncs.com/cifar-10-batches-py/【注】这个值依赖于自己试验环境中的bucket名字,注意上述路径中标红的部分一致即可。
8.设置输出目录。将其设置为check_point: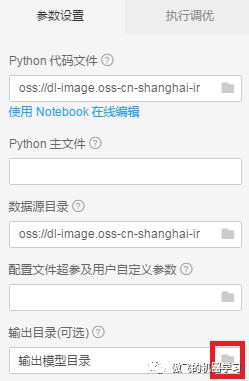
选择保存着训练数据和代码的OSS Bucket,双击其中的目录check_point: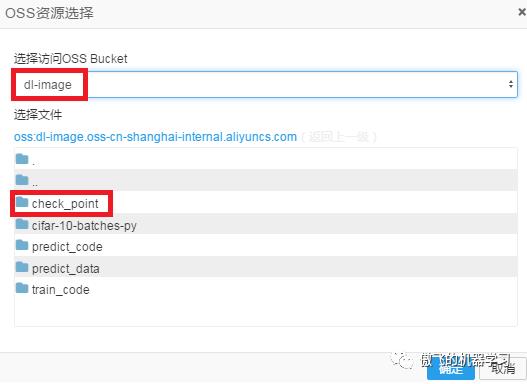
选择.所在的行(即选中当前目录),点击确定,完成设置: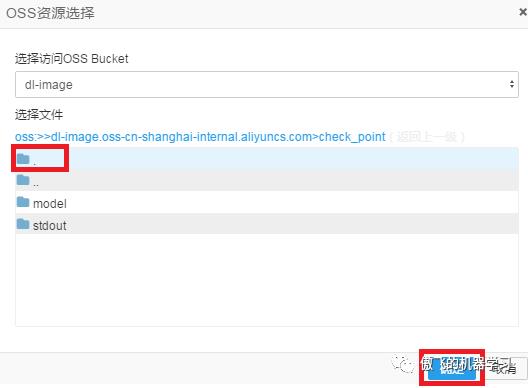
9.选中训练Tensorflow组件,点击右键,选中执行到此处,开始进行模型训练: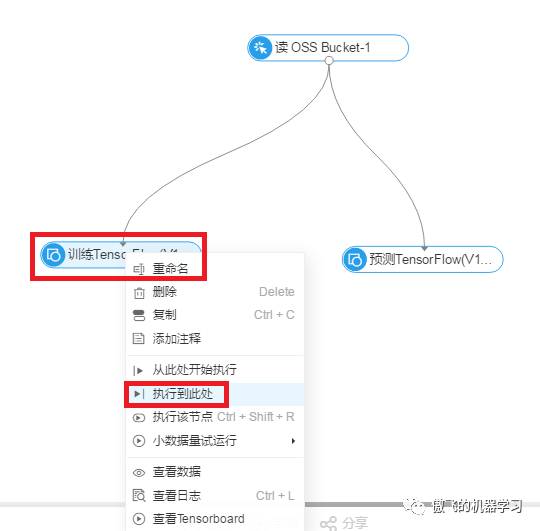
10.执行成功后,组件上显示绿色的的对号: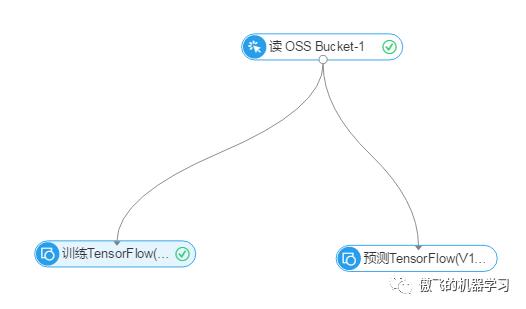
11.可以去OSS bucket的check_point目录中查看模型信息: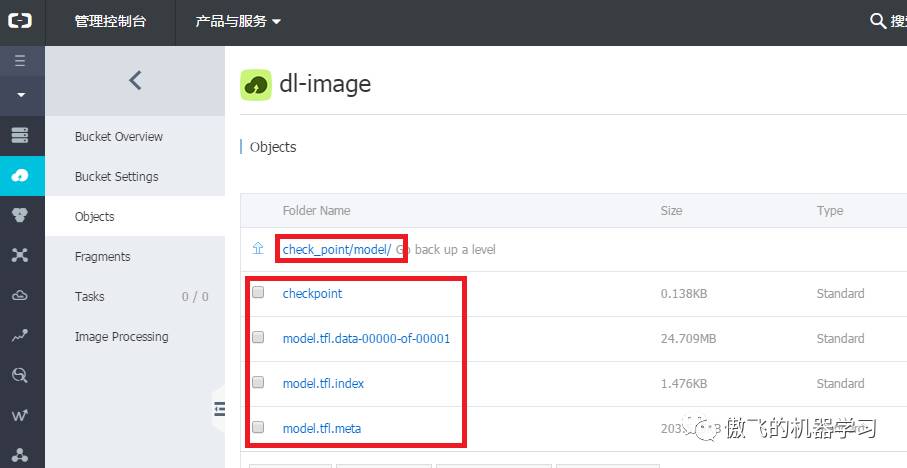
至此,模型训练完成,保存在了oss bucket的check_point目录下。
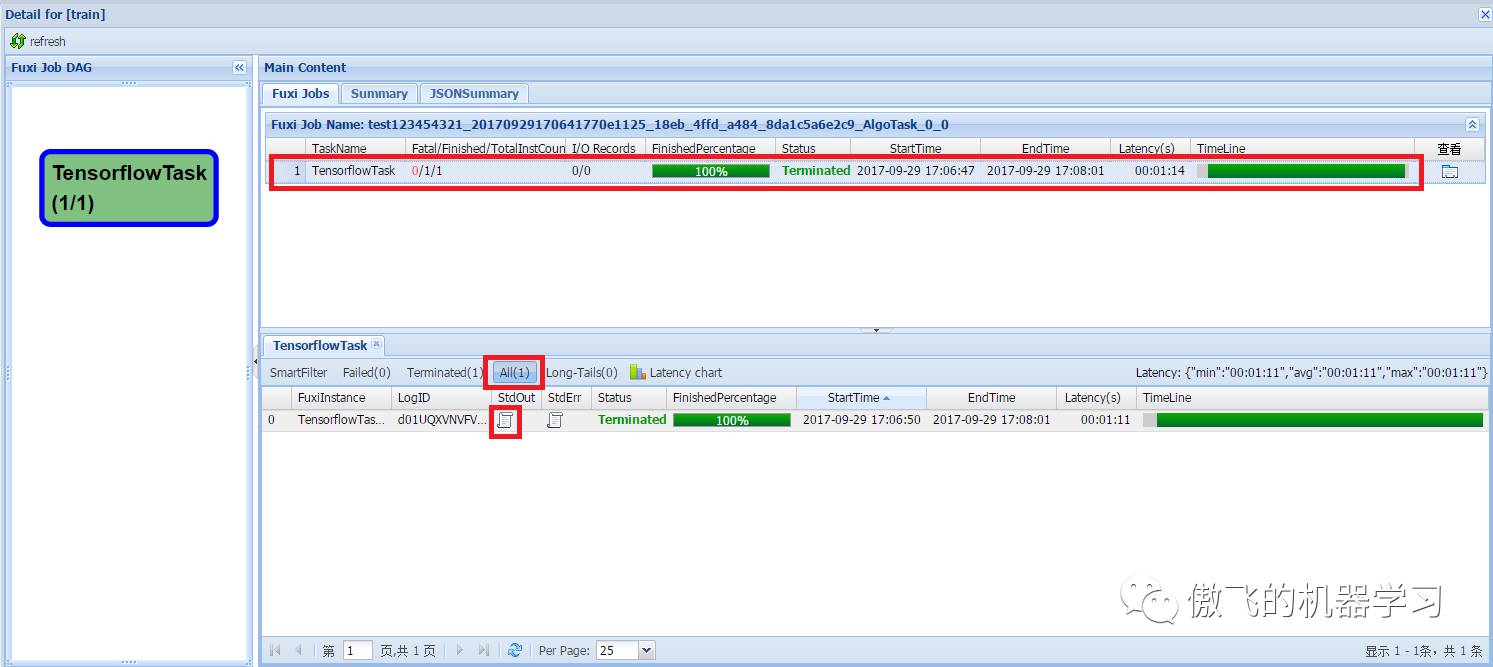
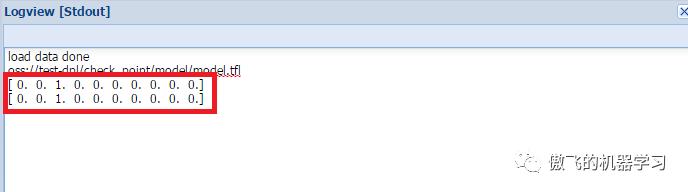
可以看到输入图片被预测为第三类,查看一下最初的训练集,可以看到第三类为“bird”,预测正确: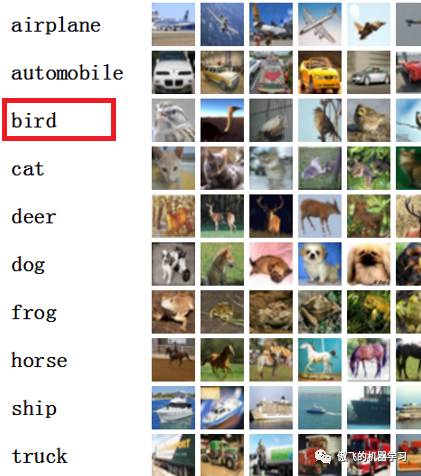
至此,整个图片识别过程完成。
由于深度学习过程中存在随机性,有一定的几率预测结果不准确。需要重新返回训练模型,进行参数调整,重复执行训练节点和预测节点(结果会自动覆盖OSS中对应的文件)。直到取得较好的效果为止。
本例中的简单调优办法为,修改训练脚本中的参数n_epoch(即最大训练迭代数),具体方法如下:
1.单击选中训练Tensorflow组件,点击右侧配置面板中的使用NoteBook在线编辑:
2.会花通过Docker启动一个Jupyter Notebook,在线编辑代码。点击“点击查看”,进入编辑界面:
3.在第120行,找到参数n_epoch,其值默认为50,可以对该值进行修改,重新运行模型(建议在50-100之间):
个人总结
实验流程还是比较复杂的,但是并不是非常复杂,实验的核心部分我认为是在python源码上。所以后期我会更多的学习深度学习中python代码的应用。
以上是关于利用深度学习框架Tensorflow做图像识别(基于阿里云PAI)的主要内容,如果未能解决你的问题,请参考以下文章