如何免费云端运行Python深度学习框架?
Posted 玉树芝兰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何免费云端运行Python深度学习框架?相关的知识,希望对你有一定的参考价值。
想运行TuriCreate,却没有苹果电脑,也没有Linux使用经验,怎么办?用上这款云端应用,让你免安装Python运行环境。一分钱不用花,以高性能GPU,轻松玩儿转深度学习。
痛点
《如何用Python和深度神经网络识别图像?》一文发布后,收到了很多读者的留言。大家对从前印象中高不可攀的深度神经网络图片识别来了兴趣,都打算亲自动手,试用一下简单易用的TuriCreate框架。
有的读者尝试之后,很开心。

有的读者却遇到了问题:
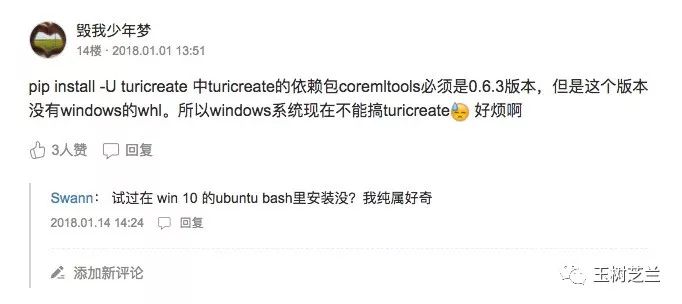
我在《如何用Python和深度神经网络寻找近似图片?》一文中,对这个疑问做了回应——TuriCreate目前支持的操作系统有限,只包括如下选项:
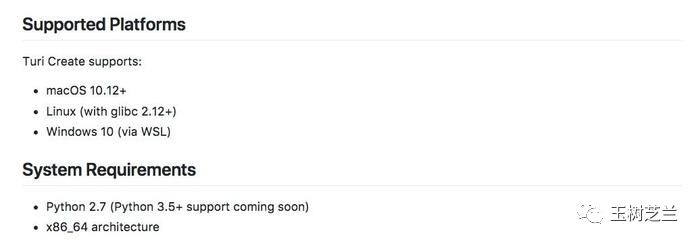
如果你用的操作系统是Windows 7及以下版本,目前TuriCreate还不支持。
解决办法有两种:
第一种,升级到Windows 10,并且使用WSL。
第二种,采用虚拟机安装好Linux。
这两种解决方法好不好?
不好。
它们都是没有办法的办法。
因为都需要用户接触到Linux这个新系统。
对于IT专业人士来说,Linux确实是个好东西。
首先,它免费。因此可以把软硬件的综合使用成本降到最低;
其次,它灵活。从系统内核到各种应用,你都可以随心所欲定制。不像Windows或者macOS,管你用不用西班牙语和文本语音朗读功能,统统默认一股脑给你装上;
第三,它结实。Linux虽然免费,但是从创生出来就是以UNIX作为参考对象,完全可以胜任运行在一年都不关机一回的大型服务器上。
但是,Linux这些优点,放到我专栏的主要阅读群体——“文科生”——那里,就不一定是什么好事儿了。
因为Linux的学习曲线,很陡峭。
所以,如果你固执地坚持在自己的电脑上运行TuriCreate,又不愿意学Linux,那可能就得去买台Macbook了。
但是,谁说运行代码一定要在自己的机器上呢?
云端
你可以把TuriCreate安装在云端——只要云端的主机是Linux就好。
你可能怒了,觉得我是在戏耍你——我要是会用Linux,就直接本地安装了!本地的Linux我都不会用,还让我远程使用Linux?!你什么意思嘛?
别着急,听我把话说完。
云端的Linux主机,大多是只给你提供个操作系统,你可以在上面自由安装软件,执行命令。
这样的云端系统,往往需要你具备相当程度的IT专业知识,才能轻松驾驭。
更要命的是,这种租用来的云主机,要么功能很弱,要么很贵。
那种几十块钱一个月的主机,往往只有一个CPU核心。跑深度学习项目?只怕你还没获得结果,别人的论文都发出来了。
有没有高性能主机?当然有。
例如亚马逊的AWS,就提供了p2.xlarge这样的配置供你选择。有了它,运行深度学习任务游刃有余。
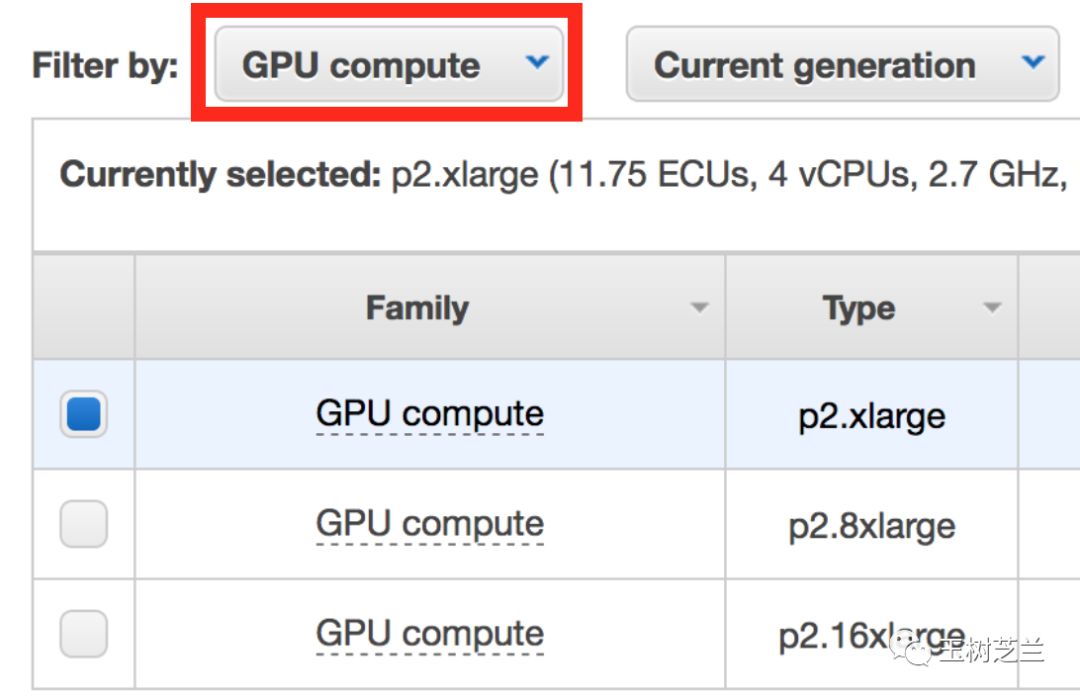
但是它很贵。
有人计算过,如果你需要长期使用深度学习功能,还是本地组装一台高性能电脑比较划算。
另外,虽然亚马逊已经帮你做了很多准备工作。你从开始折腾这台云主机到真正熟练掌握使用,还是要花些功夫。
从网上找一篇靠谱的教程后,经过自己的反复实践,不断求助,最终你会掌握以下技能:
硬件配置含义;
云平台信用卡支付方式;
控制面板使用;
计费原理;
竞价规则;
实例使用限制;
定制实例类型选择;
安全规则设定;
公钥私钥的使用;
加密通讯ssh连接;
文件权限设定;
其他……
了解了如何最省钱地运行高配置AWS虚拟主机,知道该在何时启动和关闭实例。一个月下来,你看着账单上的金额如此之少,会特别有成就感吧。
问题是,你最初是想要干什么来着?
你好像只是打算把手头的照片,利用TuriCreate上的卷积神经网络快速做个分类模型出来吧?
所以,这种折腾不是正道。
在某些时刻,做出正确的选择比盲目付出努力重要得多。
你应该选择一个云平台,它得具有如下特色:
你不必会Linux,也不用从头装一堆基础软件。打开就能用,需要哪个额外的功能,一条指令就搞定。提供高性能GPU用来运行深度学习代码……最好还免费。
你是不是觉得我在做梦?犹豫着要不要赶紧喊我醒过来?
这不是做梦,真的有这样的好事儿。
发现
本文推荐给你的云运行环境,是由Google提供的Colaboratory,下文简称Colab。
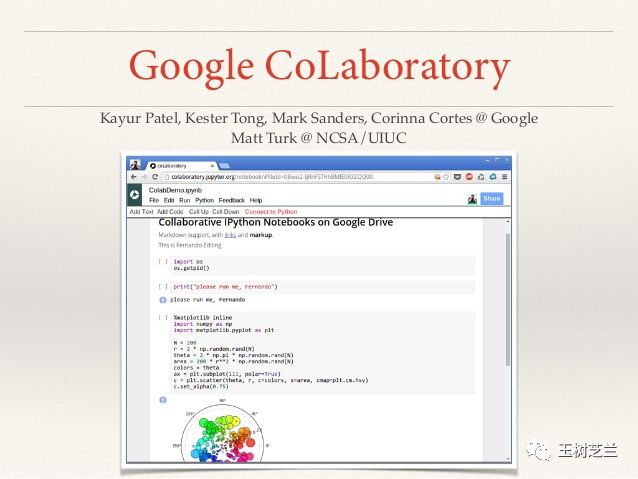
其实这个工具已经存在了好几年了。
最初版本由Google和Jupyter团队合作开发。只是最近才迭代到渐入佳境的状态。经过这篇Medium文章的推广,吸引了很多研究者和学习者的关注。
官方的介绍是:
Colaboratory 是一款研究工具,用于进行机器学习培训和研究。它是一个 Jupyter 笔记本环境,不需要进行任何设置就可以使用。
请用Google Chrome浏览器打开这个链接,你可以看到这份“Colaboratory简介”。
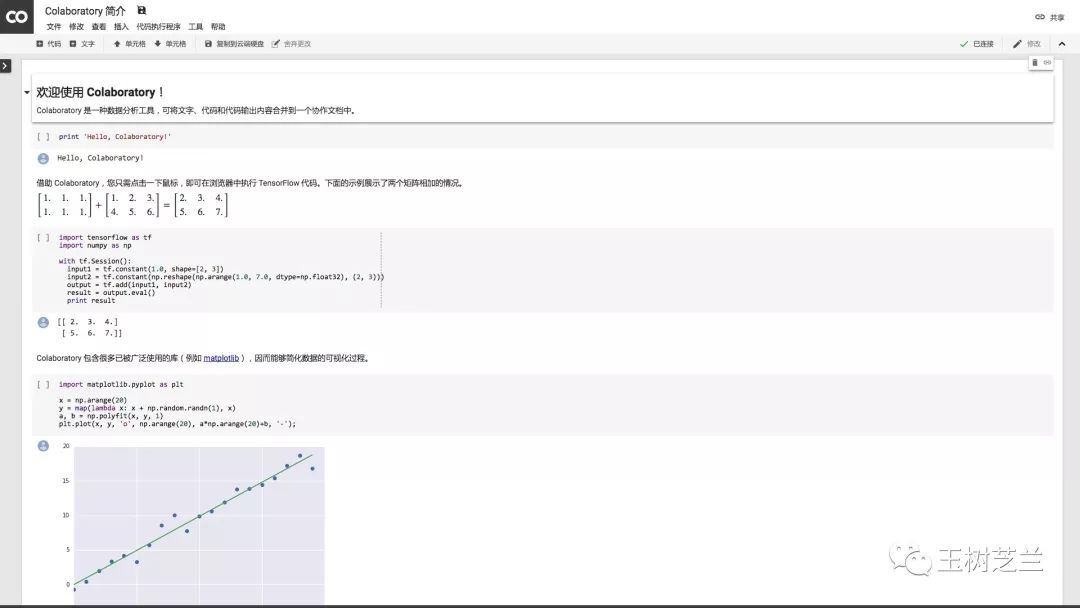
虽然外观不同,但是它实际上就是一份Jupyter Notebook笔记本。
我们尝试运行一下其中的语句。
注意这个笔记本里面的语句,其实是Python 2格式。但是默认笔记本的运行环境,是Python 3。
所以,如果你直接执行第一句(依然是用Shift+Enter),会报错。
解决办法非常简单,打开上方工具栏中的“代码执行程序”标签页。
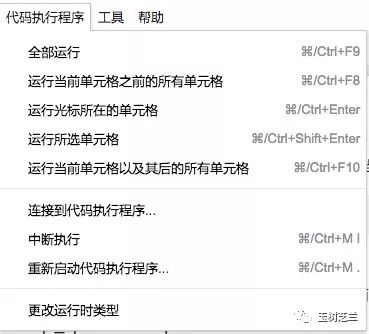
选择最下方的“更改运行时类型”。

将默认的Python 3改成Python 2之后,点击右下角的保存按钮。
然后我们重新运行第一个代码区块的语句。这次就能正常输出了。

语句区块2就更有意思了。它直接调用Google自家的深度学习框架——tensorflow软件包。

我曾经专门为tensorflow的安装写过教程。但是在这里,你根本就没有安装tensorflow,它却实实在在为你工作了。
不仅是tensorflow,许多常用的数据分析工具包,例如numpy, matplotlib都默认安装好了。
对于这些基础工具,你一概不需要安装、配置、管理,只要拿过来使用就行。
我们运行最后一个代码单元。
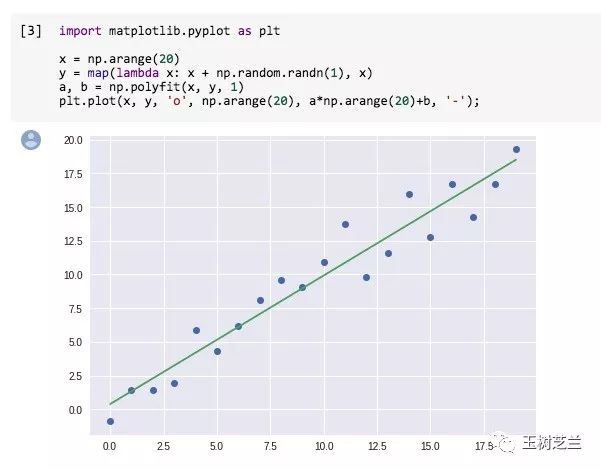
看,图片输出都毫无问题。
编程环境领域的即插即用啊!太棒了!
可是兴奋过后,你可能觉得不过如此——这些软件包,我本地机器都正确安装了。执行起来,再怎么说也是本地更方便一些啊。
没错。
但是安装TuriCreate时,你的Windows操作系统不支持,对不对?
下面我为你展示如何用Colab运行TuriCreate,进行深度学习。
数据
我把需要分类的图像数据以及ipynb文件都放到了这个github项目中。请点击这个链接下载压缩包。
下载后解压到本地硬盘。
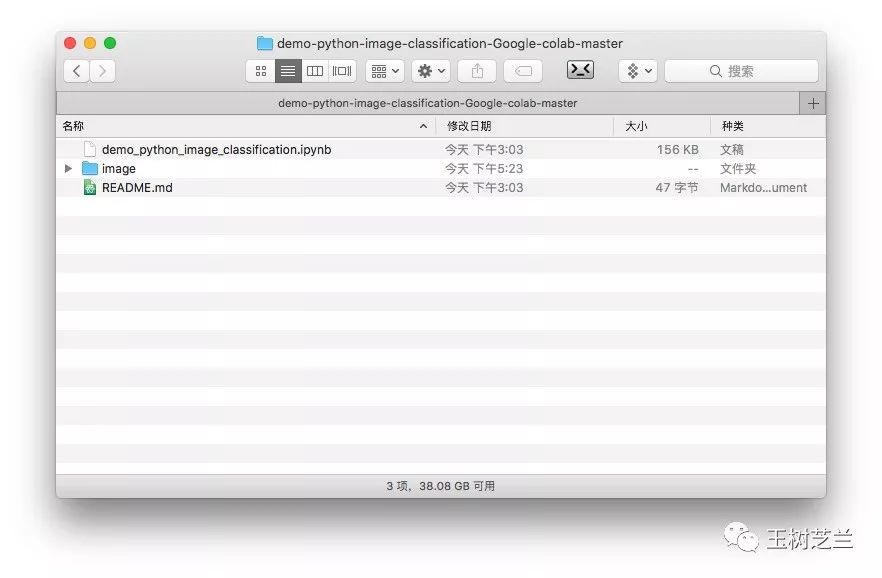
可以看到,其中包含一个ipynb文件和一个image目录。
image目录内容,就是你之前在《如何用Python和深度神经网络寻找近似图片?》一文中已经见过的哆啦a梦和瓦力的图片。
这是蓝胖子的图片:
这是瓦力的图片:
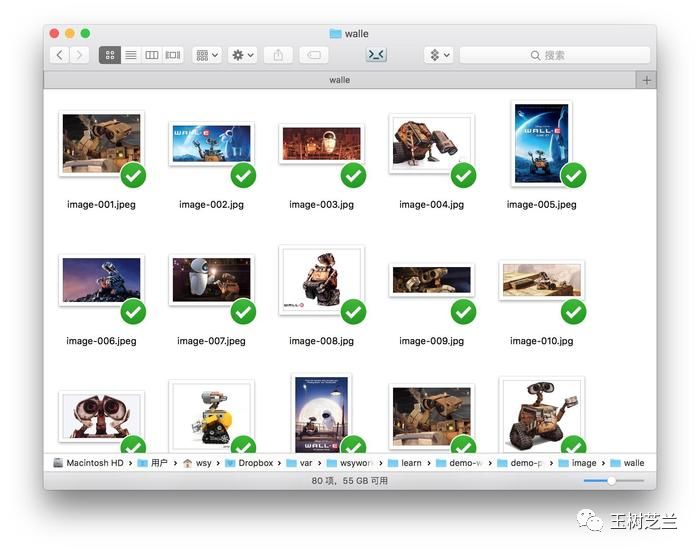
请用Google Chrome浏览器(目前Colab尚不支持其他浏览器)打开这个链接,开启你的Google Drive。
当然,如果你还没有Google账号,需要注册一个,然后登录使用。
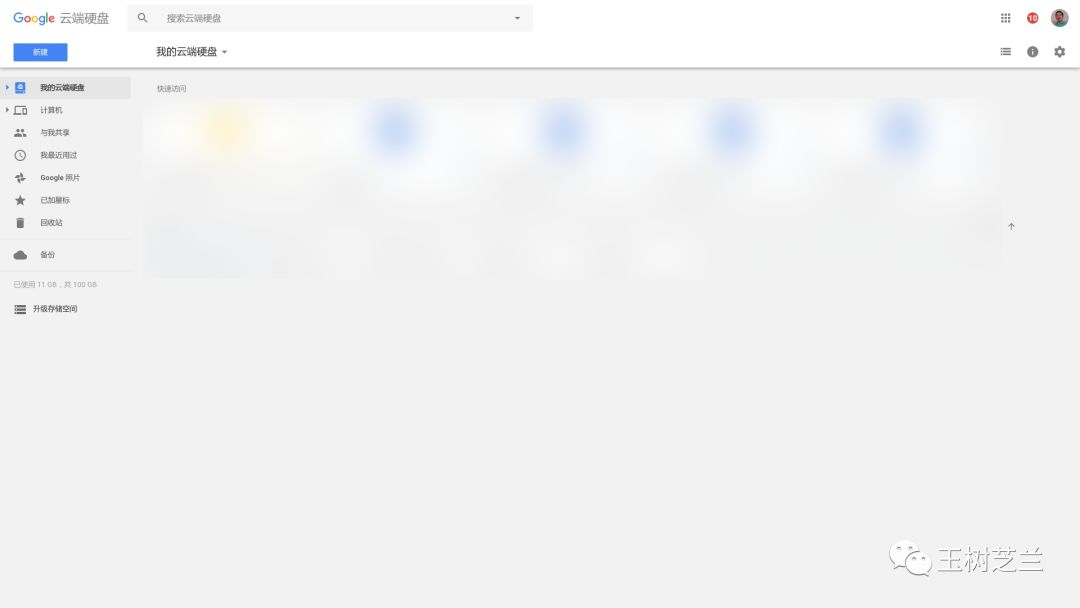
下面,把你刚刚解压的那个文件夹拖拽到Google Drive的页面上,系统自动帮你上传。
上传完成后,在Google Drive里打开这个文件夹。
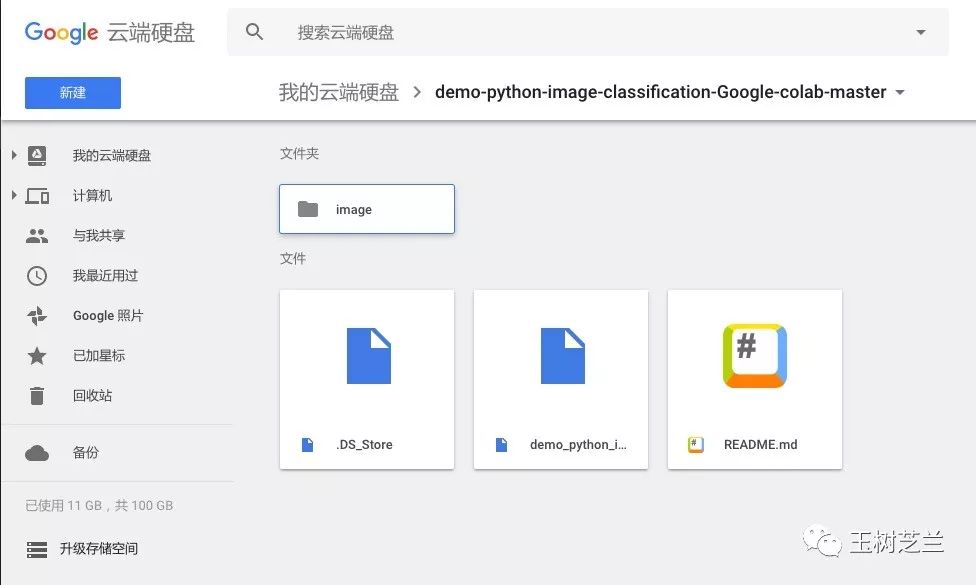
在demo_python_image_classification.ipynb文件上单击鼠标右键。选择打开方式为Colaboratory。
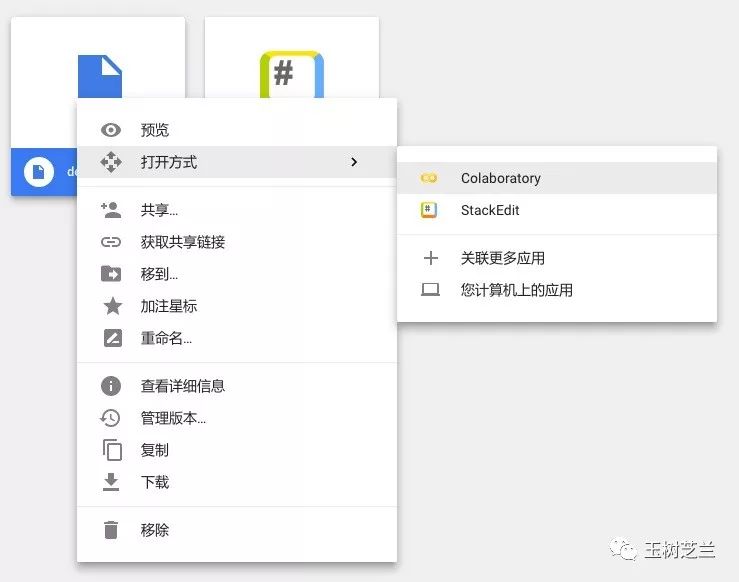
Colab打开后的ipynb文件如下图所示。
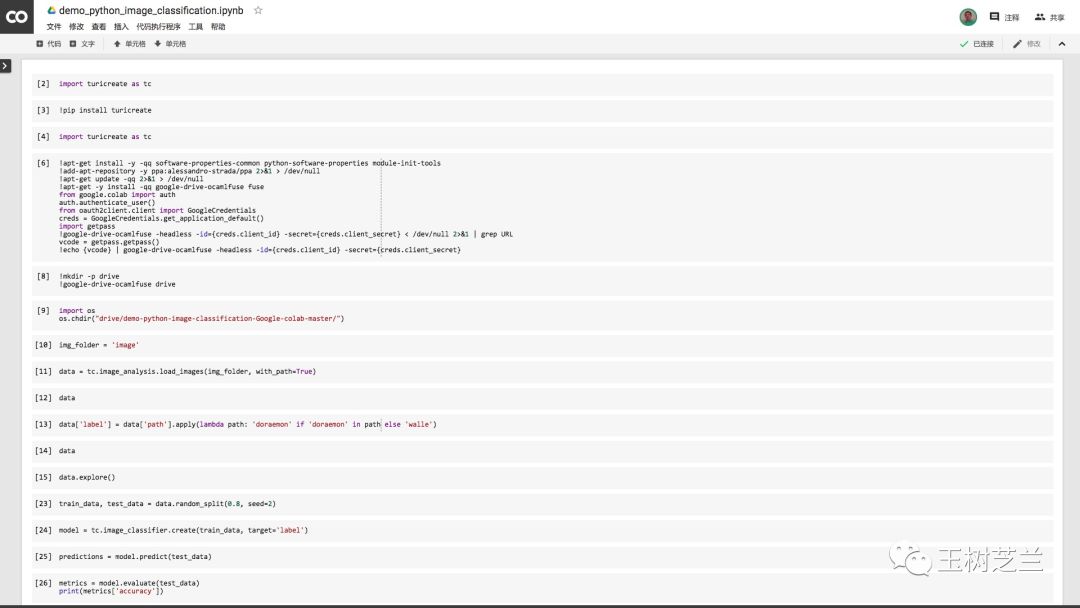
我们首先需要确定运行环境。点击菜单栏里面的“修改”,选择其中的“笔记本设置”。
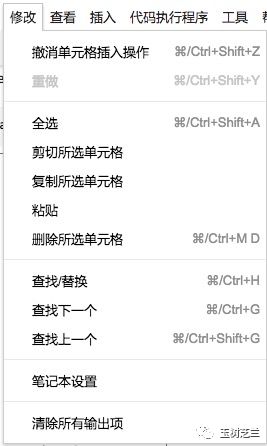
确认运行时类型为Python 2,硬件加速器为GPU。如果不是这样的设置,请修改。然后点击保存。
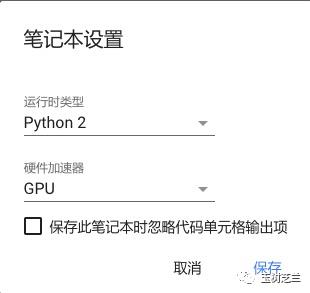
数据有了,环境也已配置好。下面我们正式开始运行代码了。
代码
我们尝试读入TuriCreate软件包。
import turicreate as tc
结果会有如下报错。
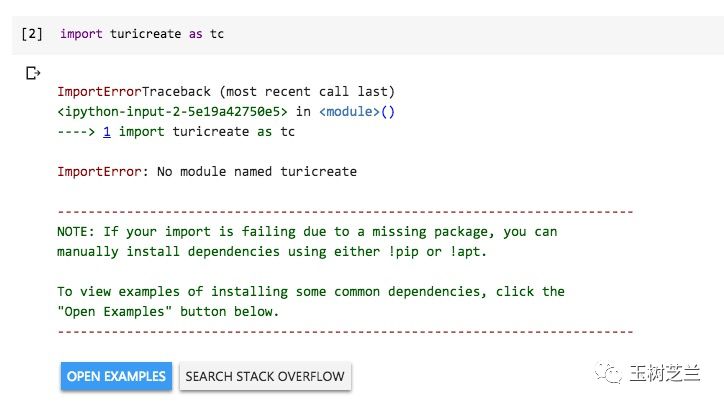
遇到这个报错很正常。
因为我们还没有安装TuriCreate。
不是说不需要安装深度学习框架吗?
那得看是谁家的深度学习框架了。
Colab默认安装Tensorflow,因为它是Google自家开发的深度学习框架。
而TuriCreate是苹果的产品,所以需要咱们手动安装。
手动安装很麻烦吗?
才不会。
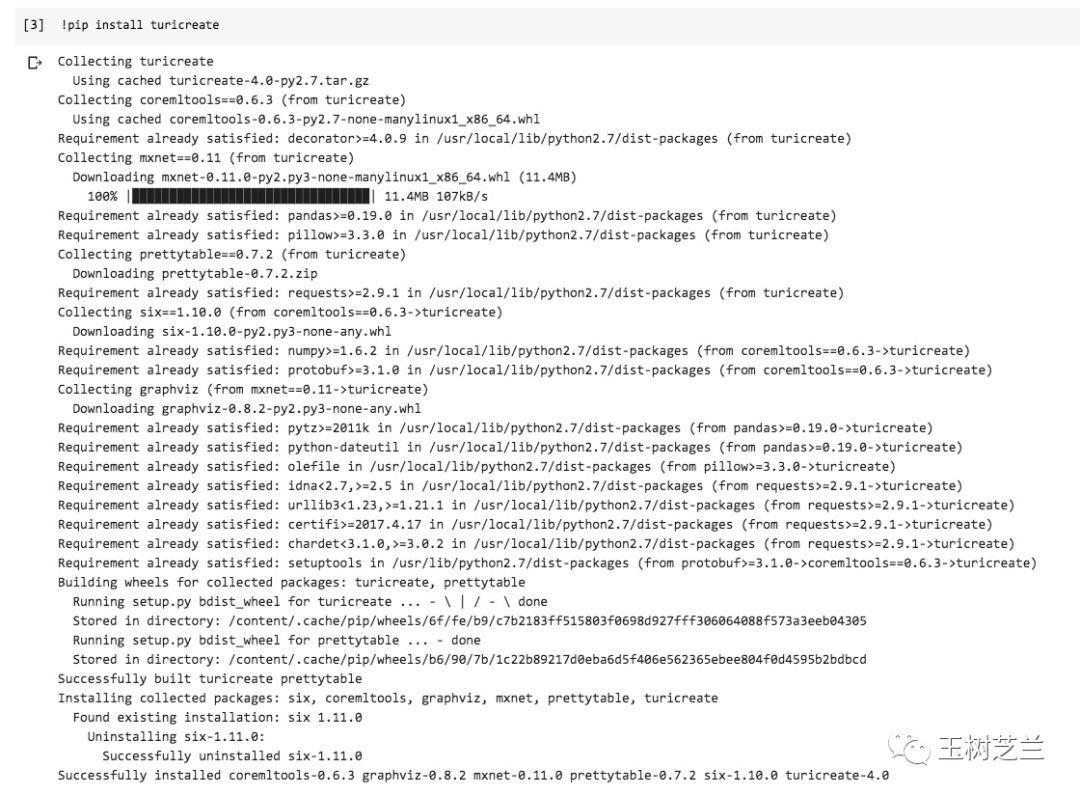
新开一个代码单元,然后输入以下一行语句:
!pip install turicreate
你就可以看到Colab帮你辛勤地安装TuriCreate以及全部依赖包了,根本不用自己操心。瞬间就安装好了。
我们重新调用TuriCreate。
import turicreate as tc
这次成功执行,再没有出现报错。
下面我们需要做一件事情,就是让Colab可以从我们的数据文件夹里面读取内容。
可是默认状态下,Colab根本就不知道我们的数据文件夹在哪里——即便我们本来就是从Google Drive的演示文件夹下面打开这个ipynb文件的。
我们首先要让Colab找到Google Drive的根目录。
这原本是一个相对复杂的问题。但是好在我们有现成的代码,可以拿来使用。
请执行下面这个单元格的代码。看不懂不要担心。因为你不需要调整其中的任何语句。
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
执行刚开始,你会看到下面的运行状态。
过了一小会儿,你会发现程序停了下来。给你一个链接,让你点击。并且嘱咐你把获得的结果填入下面的文本框。

点击链接,你会看到下图。
点击你自己的Google账号。
然后会提示你Google Cloud SDK的权限请求。
点击允许后,你就获得了一长串字符了。复制它们。

回到Colab页面上,把这一长串字符粘贴进去,回车。

你可能认为运行完毕。不对,还需要第二步验证。
又出来了一个链接。

点击之后,还是让你选择账号。
然后Google Cloud SDK又提出了权限要求。注意和上次的请求权限数量不一样。
你需要再复制另外的一串新字符。

粘贴回去,回车。这次终于执行完毕。

好了,现在Colab已经接管了你的Google Drive了。我们给Google Drive云端硬盘的根目录起个名字,叫做drive。
!mkdir -p drive
!google-drive-ocamlfuse drive
然后,我们告诉Colab,请把我们当前的工作目录设定为Google Drive下的demo-python-image-classification-Google-colab-master文件夹。
import os
os.chdir("drive/demo-python-image-classification-Google-colab-master/")
好了,准备工作完毕,我们继续。
我们需要告诉TuriCreate,图像数据文件夹在哪里。
img_folder = 'image'
然后,我们读入全部图像文件到数据框data。
data = tc.image_analysis.load_images(img_folder, with_path=True)
这里,你会发现读入速度比较慢。这确实是个问题,是否是因为TuriCreate的SFrame数据框在Colab上有些水土不服?目前我还不能确定。
好在咱们样例中的文件总数不多,还能接受。
终于读取完毕了。
我们看看data中包含哪些数据吧。
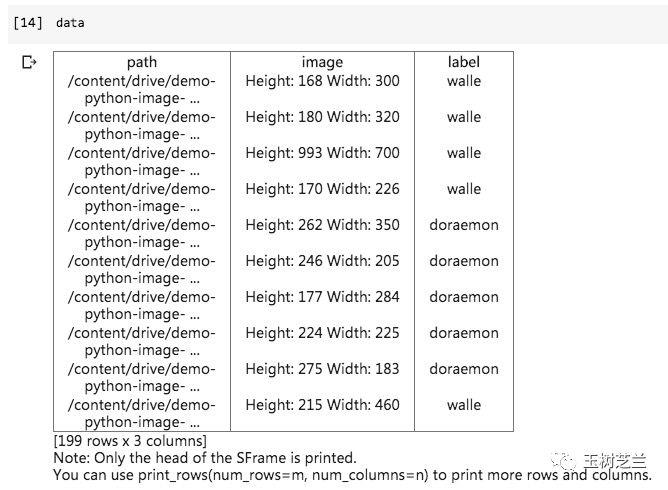
data
跟Jupyter Notebook本地运行结果一致,都是文件路径,以及图片的尺寸信息。

下面,我们还是给图片打标记。
来自哆啦a梦文件夹的,标记为doraemon;否则标记为walle。
data['label'] = data['path'].apply(lambda path: 'doraemon' if 'doraemon' in path else 'walle')
再看看data数据框内容。
data
可见,标记已经成功打好。
我们尝试用explore()函数浏览data数据框,查看图片。
data.explore()
但是很不幸,TuriCreate提示我们,该功能暂时只支持macOS.
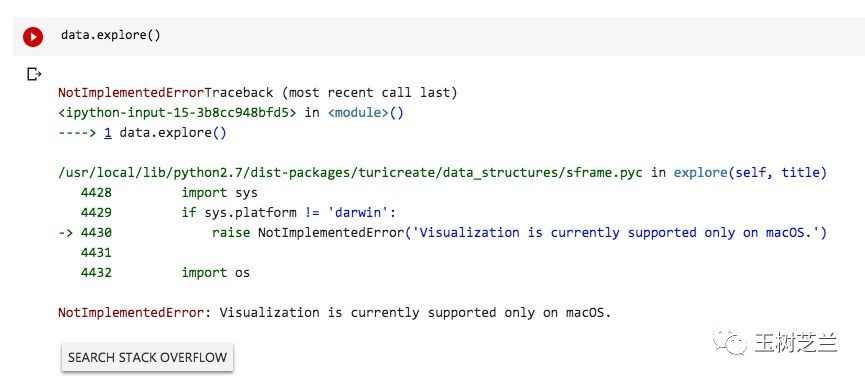
别忘了,我们现在使用的,是Linux操作系统,所以无法正常使用explore()函数。不过这只是暂时的,将来说不定哪天就支持了。
幸好,这个功能跟我们的图像分类任务关系不大。我们继续。
把数据分成训练集与测试集,我们使用统一的随机种子取值,以保证咱们获得的结果可重复验证。
train_data, test_data = data.random_split(0.8, seed=2)
下面我们正式建立并且训练模型。
model = tc.image_classifier.create(train_data, target='label')
运行的时候,你会发现,原本需要很长时间进行的预训练模型参数下载,居然瞬间就能完成。
这是怎么回事儿?作为思考题,留给你自行探索解答。给你一个小提示:云存储。
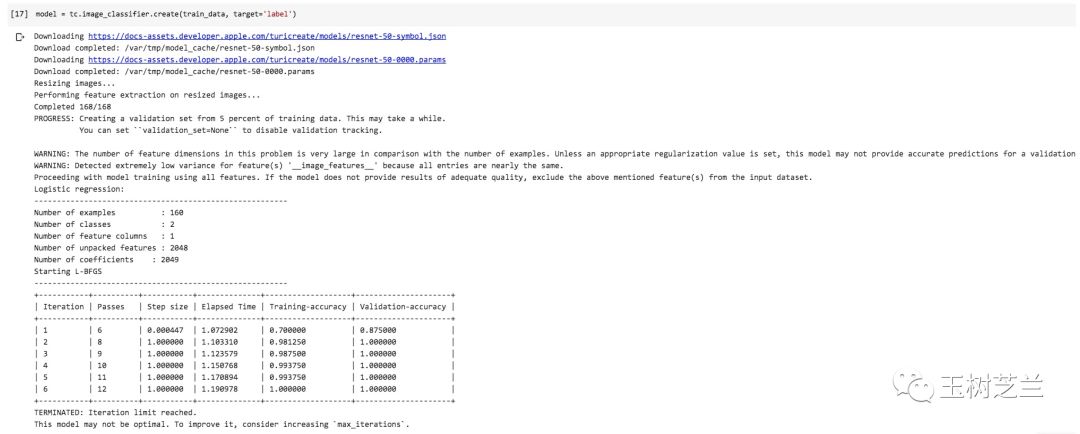
TuriCreate自动帮我们处理了图像尺寸归一化,并且进行了多轮迭代,寻找合适的超参数设置结果。
好了,我们尝试用训练集生成的模型,在测试集上面预测一番。
predictions = model.predict(test_data)
预测结果如何?我们用evaluate()函数来做个检验。
metrics = model.evaluate(test_data)
print(metrics['accuracy'])
结果如下:
0.935483870968
我们看看预测的结果:
predictions
dtype: str
Rows: 31
['doraemon', 'walle', 'walle', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle']
再看看实际的标记:
test_data['label']
dtype: str
Rows: 31
['walle', 'walle', 'walle', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle']
两相比对,我们希望找出那些错误预测的图片存储位置:
test_data[test_data['label'] != predictions]['path']

下面我们需要直观浏览一下预测错误的图像。
读入Jupyter的Image模块,用于展示图像。
from IPython.display import Image
我们先来展示第一幅图像:
Image(test_data[test_data['label'] != predictions]['path'][0])
结果如下:

还是老样子,50层的深度神经网络模型,已经无法让人直观理解。所以我们无法确切查明究竟是哪个判定环节上出了问题。
然而直观猜测,我们发现在整个照片里,方方正正的瓦力根本就不占主要位置。反倒是圆头圆脑的机器人成了主角。这样一来,给图片形成了比较严重的噪声。
我们再来看看另一幅图:
Image(test_data[test_data['label'] != predictions]['path'][1])
结果是这样的:

这幅图里面,同样存在大量的干扰信息,而且就连哆啦a梦也做了海盗cosplay。
好了,到这里,我们的代码迁移到Colab工作顺利完成。
如你所见,我们不需要在本地安装任何软件包。只用了一个浏览器和一个从github下载的文件夹,就完成了TuriCreate深度学习的(几乎)全部功能。
比起虚拟机安装Linux,或者自己设定云端Linux主机,是不是轻松多了呢?
小结
通过阅读本文,希望你已经掌握了以下知识点:
某些深度学习框架,例如TuriCreate,会有平台依赖;
除了本地安装开发环境外,云端平台也是一种选择;
选择云端平台时,特别要注意设置的简便性与性价比;
如何将数据和代码通过Google Drive迁移到Colab中;
如何在Colab中安装缺失的软件包;
如何让Colab找到数据文件路径。
另外,请你在为需求选择工具的时候,记住哈佛大学营销学教授莱维特(Theodore Levitt)的那句经典名言:
人们其实不想买一个1/4英寸的钻头。他们只想要一个1/4英寸的洞。
这句话不仅对学习者和开发者有用。
对于产品的提供者,意义只怕更为重大。
讨论
你之前正确安装了TuriCreate了吗?用的什么操作系统?你尝试过在云端运行Python代码吗?有没有比Colab更好的云端代码运行环境?欢迎留言,把你的经验和思考分享给大家,我们一起交流讨论。

如果你希望支持我继续输出更多的优质内容,欢迎微信识别下方的赞赏码,打赏本文。感谢支持!
欢迎微信扫码加入我的“知识星球”圈子。第一时间分享给你我的发现和思考,优先解答你的疑问。
以上是关于如何免费云端运行Python深度学习框架?的主要内容,如果未能解决你的问题,请参考以下文章