干货 | 华云数据分布式深度学习框架构建经验分享
Posted 华云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 | 华云数据分布式深度学习框架构建经验分享相关的知识,希望对你有一定的参考价值。

云
人工智能是一个历久弥新的话题,在数十年的发展中几经沉浮,但是随着近年来AlphaGo,ImageNet等捷报的频频传来,人工智能再一次被推倒了风口浪尖,人人趋之若鹜。驱动这波人工智能浪潮的核心引擎正是深度学习, 最近几年各种深度学习框架快速的流行起来,比如TensorFlow、Keras、Torch、PyTorch、MXNet、Caffe等。在这些框架中,除了对GPU加速的支持之外,对分布式环的支持也是它们广受欢迎的关键因素之一。
接下来,本文将选取一款流行的深度学习框架并结合华云数据挖掘团队产品开发实践,与大家分享分布式深度学习中的点滴经验。
流行的深度学习框架
深度学习框架层出不穷,其中包括TensorFlow、Caffe、Keras、CNTK、Torch、PyTorch、MXNet、DeepLearning4j,等等。图 1和图 2分别展示了各个框架在研究人员中的使用情况统计和在github上的各项指标统计。TensorFlow在科研使用量上及项目活跃程度上,都完胜其它框架。除Google号召力和研发水平外,TensorFlow本身确有诸多优异表现,比如编程灵活,执行效率高,部署便利等等。到目前为止,TensorFlow在github上仍然保持着快速的迭代更新,而且形成了活跃社区。
在综合考虑了各种深度学习框架的功能与特点以及项目的具体需求之后,在实际工作中,华云数据Insight-GPUs选择TensorFlow作为深度学习的开发框架,并且拓展了训练过程及结果在分布式环境上的可视化的功能。
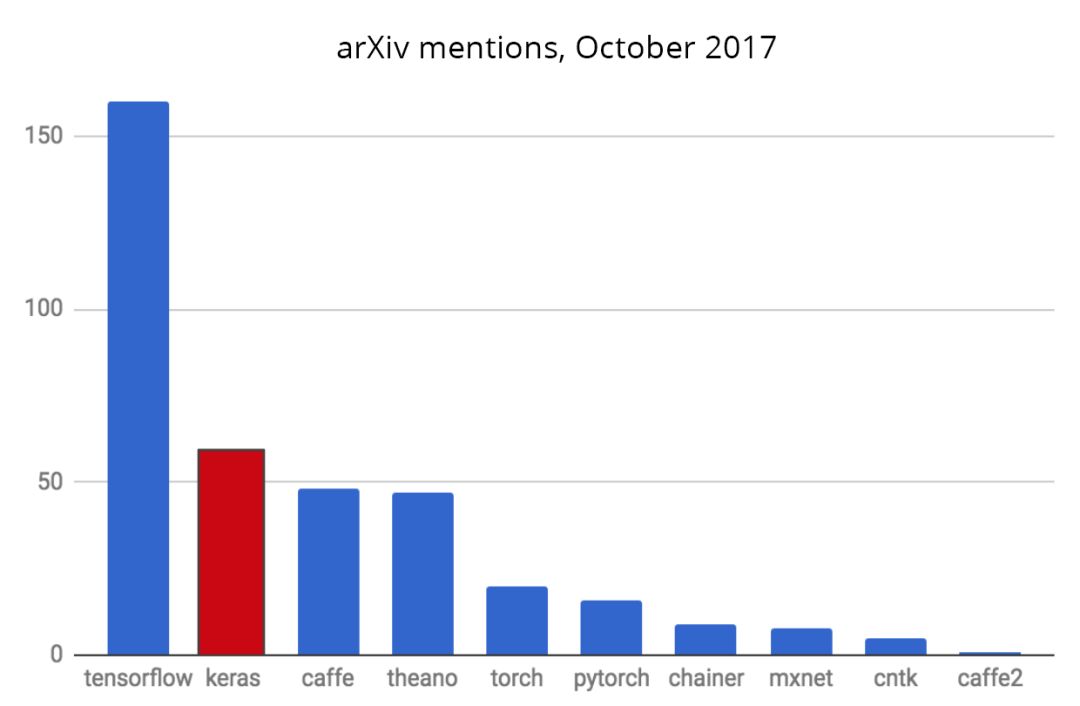
图 1 各框架在研究人员中的使用情况(图片引自keras官网)
图表2显示了TensorFlow及各种深度学习框架对各种语言的支持情况。能看出Python是当下在深度学习上使用最多的。
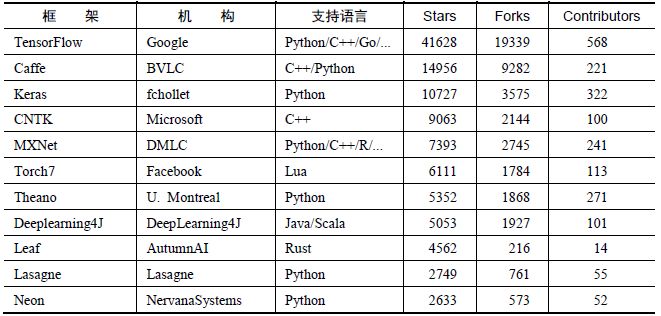
图 2 各个开源框架在github上的数据统计(图片引自csdn博客网贴)
Python也被Spark厚爱,比如,可使用spark-submit直接提交python版本的分布式map-reduce程序;人们自然也会想到用基于内存map-reduce管理机制来处理分布式TensorFlow程序,来对付单机搞不定的计算任务。
然而,基于gRPC(google Remote Process Calling)的TensorFlow也能很灵活地支持分布式环境。
TensorFlow及原生分布式方案
01
TensorFlow简介
TensorFlow是一个采用静态数据流图,支持常见的神经网络结构,比如卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)之外,TensorFlow还支持深度强化学习乃至其它计算密集的科学计算,如偏微分方程求解、物理仿真等。
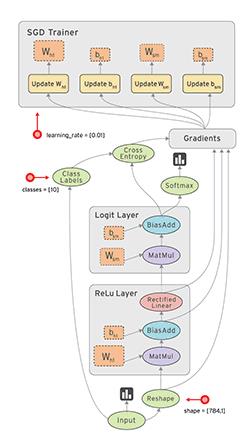
图 3 数据流图 (图片引自TensorFlow官网)
图3示意了一张采用随机梯度下降法来训练模型的图(Graph)。TensorFlow是一款采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。TensorFlow可以放到分布式式环境下训练,实现集群、GPU集群或TPU集群并行计算。
02
原生分布式方案
TensorFlow支持以“数据并行化”的方式对模型进行分布式训练,实际上指的是同一个“/job:worker”分组下,不同任务(task)可以分别使用不同的小批量(mini-batch)数据对同一个模型进行训练,更新同一份参数。分布式TensorFlow支持实现方式有以下几种:
(1)图内复制(In-graph replication)
1. 通常所有的操作都定义在一个Graph中;
2. 参数定义、更新相关的操作都集中分配给参数服务器(“/job:ps”);
3. 计算密集的操作会被复制多份,每一份都会被指定给不同worker节点(“/job:worker”)。
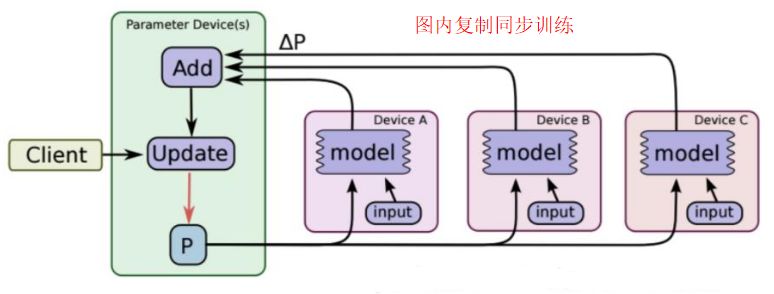
图 4 图内复制同步训练示意图 (图片引自TensorFlow官网)
(2)图间复制(Between-graph replication)
1. 需要有多个客户端,每个客户端都有一份graph的定义;
2. 通常每个客户端跟每一个执行worker类型task的server在同一个进程中;
3. 同图内复制一样,参数的定义与更新也都集中分配给参数服务器(“/job:ps”)。
(3)异步训练(Asynchronous training)
1. Graph的每一份副本各自独立地执行一个训练循环,之间不会协同;
2. ps服务器只要收到一台worker服务器的梯度值,就直接进行参数更新;
3. 不稳定,训练曲线震荡比较剧烈;
4. 适用于in-graph和between-graph。
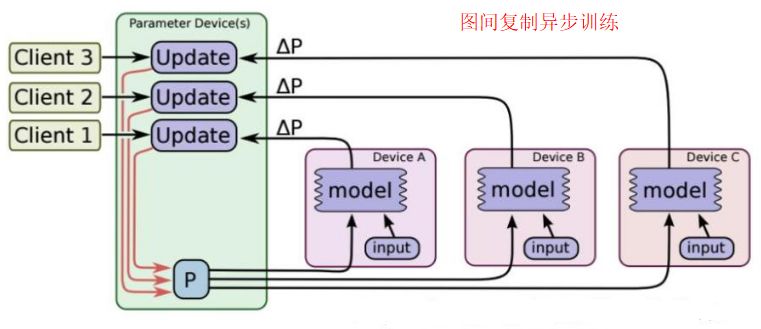
图 5 图间复制异步训练示意图 (图片引自TensorFlow官网)
(4)同步训练(Synchronous training)
1. 各个worker服务器都从ps服务器读取同一份参数,计算参数的梯度,然后把梯度传给ps服务器,本身并不进行参数更新;
2. ps服务器收到所有worker服务器的梯度之后,对参数进行更新;
3. ps服务器每一次更新参数的时候都需要等待所有的worker服务器计算并传递参数梯度,因此执行速度取决于执行最慢的worker服务器。
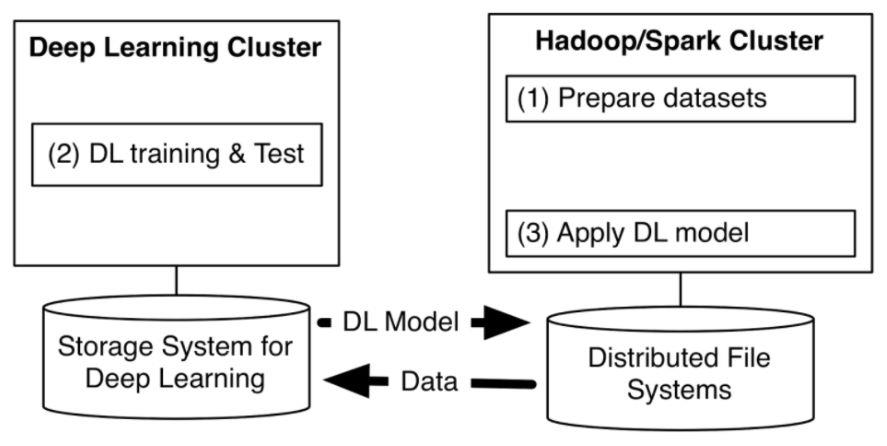
图 6 独立于Hadoop/Spark集群的TensorFlow集群 (图片引自Yahoo Hadoop网站)
在2016年,TensorFlow支持了HDFS,但仍需用户部署专门TensorFlow应用集群,如图 6所示。
基于gRPC及RDMA(Remote Direct Memory Access)分布式TensorFlow优势特点是灵活,特别方便于有大量分布式编程基础的开发人员,但这一特点也带来不少麻烦:
(1) 需要开发人员手工指定worker上的计算资源gpu:0或者cpu:0;
(2) 需要相对谨慎计算资源,分布到各个计算节点;
(3) 分布式TensorFlow计算资源共享调度麻烦。
华云数据Insight-GPUs设计初心
一个昂贵的分布式GPU计算资源,在团队间的协作分享,还是很麻烦,甚至很棘手,因为开发者事先知道有多少计算资源可以使用调度;需事先知道存在计算资源,在竞争的场合,使用人员间,团队间,调度管理上尤为尴尬。可能是由于这些看得见的缺点和使用上的痛点,催生了其他的带有任务管理和调度功能的分布式深度学习平台。在这样的情景下,人们会自然想到用成熟spark任务调度模块(比如,Yarn或者Mesos)和Spark管理RDD机制来管理分布式TensorFlow训练任务。
01
基于Spark分布式TensorFlow
Yahoo团队基于Caffe和TensorFlow开发的两套方案,如图 所示。华云大数据团队根据内部已有的集群环境,并经过深入的客户需求分析与调研,最终决定采用TensorFlowOnSpark作为内部分布式深度学习的部署方案。
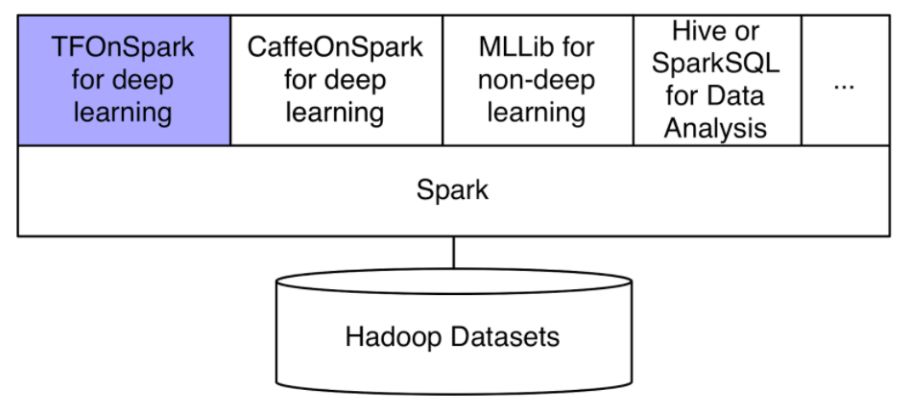
图 7 基于Spark的深度学习扩展模块(图片引自Yahoo Hadoop网站)
02
RDD动态TensorFlow分布式训练
在TensorFlow原生的分布式方案中,需要用户在提交应用之外手动的配置、维护、管理整个集群的运行,例如,在提交应用前需要对节点进行仔细的配置;需要手动地启动、关闭所对应的集群节点;在Between-graph模式下需要在不同的节点上多次提交应用等等。总之,TensorFlow原生的分布式方案无论在运维成本,易用性等方面都有很多提升的空间。
可伸缩分布式数据集(Resilient Distributed Datasets, RDDs)是Spark的核心数据对象,提供了对大数据集群的高度抽象。RDD的抽象包含两个方面:
一是数据并行化,指的是数据会被划分成不同的部分保存到RDD不同的分片中;TensorFlowOnSpark提供了两种模式的支持,Tensor Mode和Spark Mode,其中Spark Mode充分利用了RDD的数据并行化机制,由Spark动态的完成数据集的切分。
二是集群节点映射,指的是RDD中的每一个分片其实都对应一个活动的进程。TensorFlowOnSpark所提供的分布式方案充分利用了RDD这两方面的特性。图 8是TensorFlowOnSpark的运行状态示意图。在整个架构中,TensorFlowOnSpark使用nodeRDD管理TensorFlow集群运行的整个生命周期,TensorFlow集群随着应用的提交与结束进行动态的创建与回收。
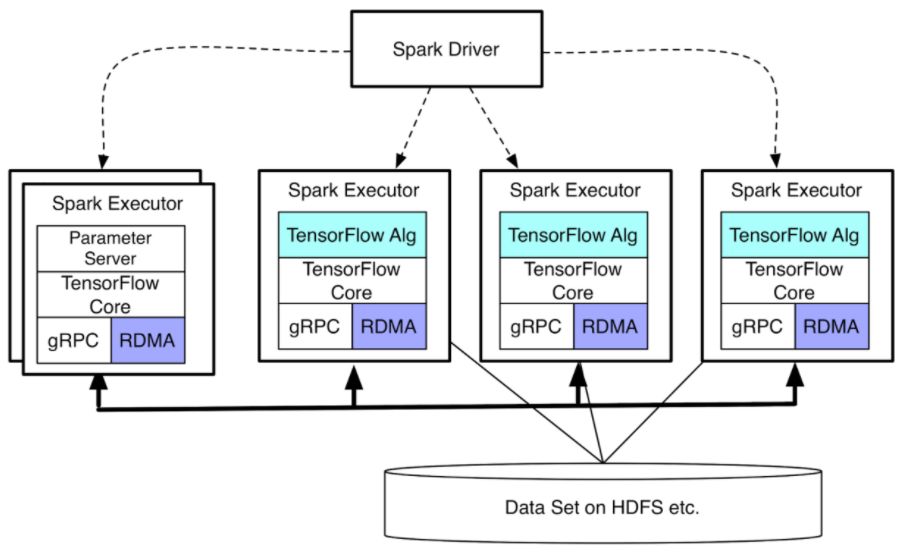
图 8 TensorFlowOnSpark运行状态图 (图片引自Yahoo hadoop网站)
03
分布式TensorFlow训练过程可视化
采用分布式TensorFlow训练一个模型,会不会降低训练的精度?采用RDD切分训练数据,再次放到分布式环境下,训练过程,loss下降过程会不会加长?这一系列的问题,需要通过训练可视化工具tensorboard来完成和解答。
数据分析人员也会通过tensorboard,看到自己精心调制的loss设计,试图监督训练中的收敛过程。但细心的开发人员会发现,即使是当下最新1.6.0版本,也不支持直接查看放在分布式环境下的TensorFlow训练过程事件,因为采用events机制写出的V2版本训练过程文件,并不能实时地被tensorboard所加载。究其原因,可能与新开发的NewCheckpointReader有关,该类封装C++程序,只关注了本地化(单机本地化目录)解析,而忽视了兼容HDFS文件夹所致。
通过本地文件夹与分布式环境下events文件夹logdir同步手段,可回避解决tensorboard不能加载位于HDFS上events文件夹这个问题,仍可以变相地达到查看分布式TensorFlow训练过程的目的。
华云数据Insight-GPUs直接读取HDFS上events文件夹,实时解析放置于分布式环境中的TensorFlow训练过程文件events、model.ckpt.data*等文件,毋须同步logdir文件夹。同时,为了脱离语言限制,华云数据Insight-GPUs根据bazel特点,将tensorboard可视化功能也拆分出来,方便不同语言开发者调用和嵌入。
用户可以按照图9方式嵌入分布式TensorFlow训练过程中的隐层权重分布图:
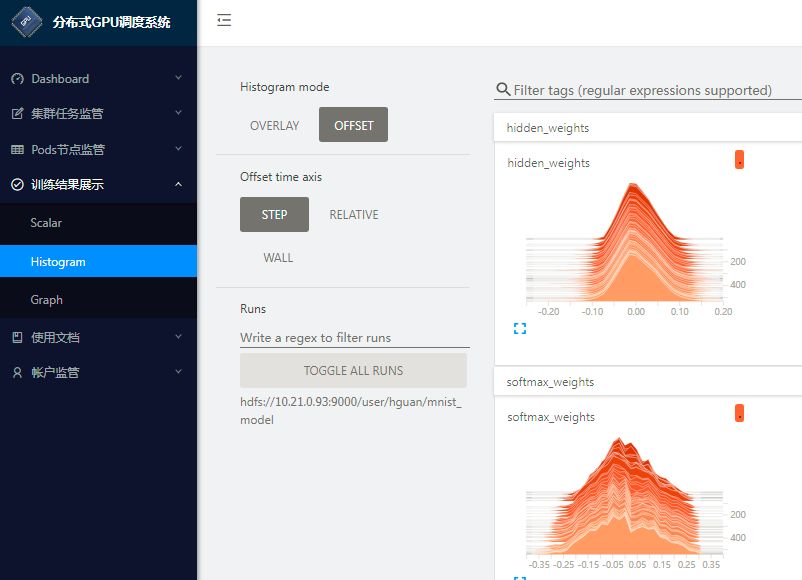
图 9 华云Insight-GPUs
展示分布式TensorFlow训练过程中的隐层权重
最直接地,如图10所示,也可以直嵌入训练结果页面:
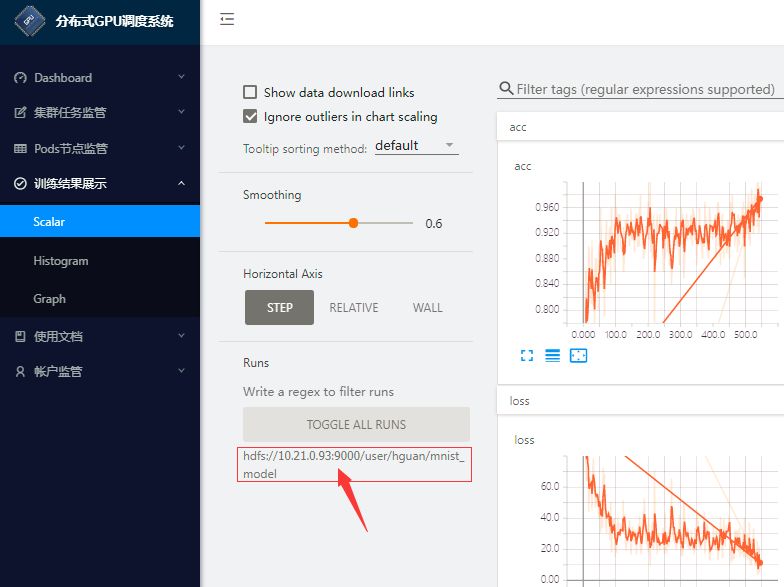
图 10 华云数据Insight-GPUs展示分布式TensorFlow训练结果
04
华云数据分布式Insight-GPUs运行部署环境
采用最新ant-design页面设计的Insight-GPUs可以很好地融入各类云产品,如,华云开发的公有云、私有云CloudUltra™及超融合产品。Insight-GPUs嵌入k8s客户端,可以为用户设计出更走心的管理功能(比如,华云数据Insight-GPUs可以从一个pod反追踪到顶层执行的分布式GPU任务),帮用户更好地在各类云上编排管理容器的同时,也管理好异构GPU集群。

1. TensorFlow官方网站. https://www.tensorflow.org/
2. Keras官方网站. https://keras.io/
3. 主流深度学习框架对比. http://blog.csdn.net/zuochao_2013/article/details/56024172
4. TensorFlowOnSpark github. https://github.com/yahoo/TensorFlowOnSpark
5. Open Sourcing TensorFlowOnSpark: Distributed Deep Learning on Big-Data Clusters. http://yahoohadoop.tumblr.com/post/157196317141/open-sourcing-tensorflowonspark-distributed-deep
6. Spark官网. http://spark.apache.org/
相关阅读
如果您有意了解华云,请点击阅读原文。
以上是关于干货 | 华云数据分布式深度学习框架构建经验分享的主要内容,如果未能解决你的问题,请参考以下文章
干货!分享 10 个用于并行和分布式机器学习任务的Python框架