告别选择困难症,我来带你剖析这些深度学习框架基本原理
Posted AI开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了告别选择困难症,我来带你剖析这些深度学习框架基本原理相关的知识,希望对你有一定的参考价值。
本文为 AI 研习社编译的技术博客,原标题 The Anatomy of Deep Learning Frameworks,作者为 Gokula Krishnan Santhanam。
翻译 | Lamaric 莫青悠 整理 | 凡江
无论你喜欢或不喜欢,深度学习就在这里等着你来学习,伴随着技术淘金热而来的过多的可选项,让新手望而生畏。
如果你已经决定开始踏进深度学习的领域,首先要解决的问题之一就是:学习哪一种深度学习框架呢?如果你想要去理解所有这些框架的构建架构,我接下来介绍的内容可以替代简单的试错法,来帮助你在获得了足够信息的基础上去做出决定,常见的深度学习框架包括:Theano、TensorFlow、Torch 和 Keras。所有的这些框架都各有利弊,也都有各自的方法去实现机器学习。在研究过白皮书和开发文档之后,我理解了它们的在一些设计上的选择,并总结出了对这些框架共通的基本原理概念。
在这个帖子中,我尝试概括出这些共通的原则,这将帮助你更好的理解这些框架,并为你的勇敢的心,提供一个关于如何实现你自己的深度学习框架的一个指引。一个有趣的事实是,这些原则并不是单单特定服务于深度学习的,它们适用于任何你想要进行一系列数据计算的场景下。因此,大多数的深度学习框架也可以被用于非深度学习任务中(参见:https://www.tensorflow.org/tutorials/mandelbrot/)。
以下是深度学习框架的部分核心组件:
1.张量
2.基于张量的操作
3.计算图和优化
4.自动微分工具
5. BLAS/cuBLAS和cuDNN的扩展
这些组件可以完善你的框架,但是你需要进行个性化的打磨去使你的框架使用起来更加的方便。在这篇文章中,我将使用Python的NumPy包作为参考使它更容易去理解。如果你之前从未使用过NumPy,无需焦躁,即使你跳过Numpy这一部分,这篇文章也是很好理解的。我坚信要从多层次的抽象概念去理解一个系统,所以你将会看到很多关于低阶最优化的讨论穿插着高阶微积分和线性代数。如果需要更多的说明,请跳过下面的声明。
请注意:我是Theano的投稿者,因此可能在引用文献中倾向于它。话虽如此,theano是我访问过的网站中,关于所有框架信息最丰富的网站之一。
张量
张量是一个框架的核心所在。张量是N维矩阵的概括(参考numpy中的ndarrays)。换一个方式来说,矩阵是是2维矩阵(行,列)。简单的理解张量,可以认为它是N维数组。
拿一张彩色图片举例。图片是一张258*320(高*宽)大小的RGB位图图像。这是一个3维张量(高,宽,通道数)。看下图能更好的理解(摘自https://github.com/parambharat/CarND-helpers/blob/master/image_processing/Image_processing_tutorial.ipynb)。
普通的RGB图片

同一张图片的红,绿,蓝通道图片
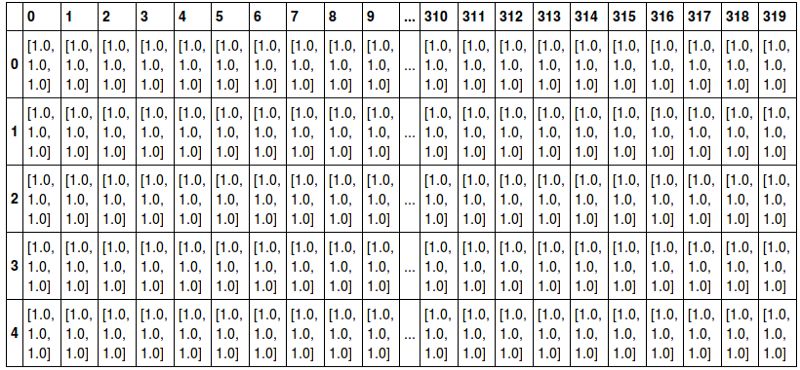
相同的图像以 3D 张量的形式表示
作为扩展,一组100个图像可以表示为4D张量(图像的ID,高度,宽度,通道)。
同样,我们将所有输入数据表示为张量,然后将它们输入神经网络。 在我们将数据提供给网络之前,这是一个必要的操作,否则我们必须定义适用于每种类型的操作,这会浪费大量时间。 我们还需要能够以我们想要的形式获取数据。
因此,我们需要一个张量对象,它支持以张量形式存储数据。 不仅如此,我们希望该对象能够将其他数据类型(图像,文本,视频)转换为张量形式返回。 想想像 numpy.imread 和 numpy.imsave 这样的东西,他们将图像作为 ndarrays 读取并分别将 ndarrays 存储为图像。
基本张量对象需要支持以张量形式表示数据。 这意味着支持索引,重载运算符,具有空间有效的方式来存储数据等等。 根据进一步的设计选择,您可能还需要添加更多功能。
张量对象的操作
神经网络可以被认为是在输入张量上执行的一系列操作以给出输出。 学习是通过纠正网络产生的输出和预期输出之间的误差来完成的。 这些操作可能很简单,如矩阵乘法(在sigmoids中)或更复杂,如卷积,池化或 LSTM。
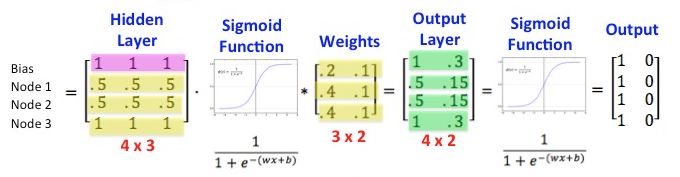
Sigmoid 层表示为 Matrix Operations,来自http://www.datasciencecentral.com/profiles/blogs/matrix-multiplication-in-neural-networks
查看以下链接,可以了解更多:
NumPy: http://www.scipy-lectures.org/intro/numpy/operations.html
Theano: http://deeplearning.net/software/theano/library/tensor/basic.html
TensorFlow: https://www.tensorflow.org/api_docs/python/math_ops/
您可以跳过此部分并自己实现这些操作,但这样做太麻烦而且效率低下。 此外,大多数操作都足够普遍,以至于可以证明它们是框架的一部分。 NumPy 做得很好,已经实现了很多操作(它也非常快),并且有一个关于怎样合并更多操作的运行 theano 的问题,这表明框架支持更多操作是多么重要。
它们通常作为类实现,而不是将操作实现为函数。 这允许我们存储有关操作的更多信息,如计算的输出形状(对于完整性检查有用),如何计算梯度或梯度本身(用于自动微分),有办法决定是否进行 GPU或CPU等上的运算。 同样,这个想法类似于 scikit-learn 实现的各种算法所使用的类。 您可以定义一个名为 compute 的方法来执行实际计算,并在计算完成后返回张量。
这些类通常派生自一个抽象类(在theano中,它是 Opclass)。 这将在Ops 中强制实施统一界面,并提供稍后添加新操作的方法。 这使得框架非常灵活,并确保即使在新的网络架构和非线性出现时人们也可以使用它。
计算图和优化
到目前为止,我们有代表对他们的张量和操作的类。 神经网络的力量在于能够将多个这样的操作链接起来形成强大的逼近器。
因此,标准用例是您可以初始化张量,对它们执行操作后执行操作,最后将生成的张量解释为标签或实际值。 听起来很简单,够吗?
将不同的操作链接在一起,取自 https://colah.github.io/posts/2015-08-Backprop/
不幸的是,当您将越来越多的操作链接在一起时,会出现一些问题,这些问题可能会大大减慢代码速度并产生错误。
1、只有在完成上一个操作后才开始下一步操作或者并行操作?
2、如何分配到不同的设备并在它们之间进行协调?
3、你如何避免冗余操作(乘以1,添加零),缓存有用的中间值,并将多个操作减少为一个(用mul替换mul(mul(mul(Tensor,2),2),2)(Tensor, 8))
还有更多这样的问题,有必要能够更好地了解这些问题是否存在。 我们需要一种方法来优化空间和时间的结果操作链。
为了获得更大的图景,我们引入了一个计算图,它基本上是一个对象,包含各种 Ops 实例的链接以及哪个操作获取哪个操作的输出以及附加信息之间的关系。 根据所讨论的框架,这可以以不同的方式实现。
例如:
Theano http://deeplearning.net/software/theano/extending/graphstructures.html
TensorFlow http://download.tensorflow.org/paper/whitepaper2015.pdf
Caffe http://caffe.berkeleyvision.org/tutorial/net_layer_blob.html
像深度学习中的许多概念想法一样,计算图的概念已经存在了很长一段时间。 查看任何编译教科书,您可以在用于优化的抽象语法树和中间表示中找到类似的概念。 这些概念已经扩展并适应深度学习场景,为我们提供了计算图。 在代码生成之前优化图形的想法(将在后面介绍)很简单。 优化本身可以再次实现为类或函数,并且可以根据您是否希望代码快速编译或快速运行而有选择地应用。
此外,由于您可以鸟瞰网络中将会发生的事情,因此图表类可以决定如何在分布式环境中部署时分配 GPU 内存(如编译器中的寄存器分配)以及在各种机器之间进行协调。 这有助于我们有效地解决上述三个问题。
自动差异化工具
使用计算图的另一个好处是计算学习阶段中使用的梯度变得模块化并且可以直接计算。 这要归功于链规则,它允许您以系统的方式计算函数组合的导数。 正如我们之前看到的,神经网络可以被认为是简单非线性的组合,从而产生更复杂的函数。 区分这些功能只是将图形从输出回到输入。 符号微分或自动微分是一种编程方式,通过它可以在计算图中计算梯度。
符号微分是指通过分析计算衍生物,即得到梯度的表达式。 要使用它,只需将值插入到派生中并使用它即可。 不幸的是,像 ReLU(整流线性单位)这样的一些非线性在某些点上是不可微分的。 因此,我们改为以迭代方式计算梯度。 由于第二种方法可以普遍使用,大多数计算图形软件包如 Computation Graph Toolkit(http://rll.berkeley.edu/cgt/)实现了自动区分,但如果要创建自己的区分,则可以使用符号区分。
推出自己的梯度计算模块通常不是一个好主意,因为工具包更容易,更快速地将其作为包的一部分提供。 因此,要么拥有自己的 Computation Graph 工具包和自动差异化模块,要么使用外部包。
由于每个节点的导数必须仅相对于其相邻节点计算,因此计算梯度的方法可以加到类中,并且可以由微分模块调用。
BLAS / cuBLAS 和 cuDNN 扩展
使用上述所有组件,您可以立即停止并拥有功能齐全的深度学习框架。 它可以将数据作为输入并转换为张量,以有效的方式对它们执行操作,计算渐变以学习并返回测试数据集的结果。 然而,问题在于,由于您最有可能以高级语言(Java / Python / Lua)实现它,因此您可以获得加速的固有上限。 这是因为即使是高级语言中最简单的操作也比使用低级语言完成时间更长(CPU周期)。
在这些情况下,我们可以采取两种不同的方法。
第一个是编译器的另一个类推。 编译过程的最后一步是在 Assembly 中生成硬件特定代码。 类似地,不是运行用高级语言编写的图形,而是在 C 中生成网络的相应代码,并且编译和执行该代码。 其代码存储在每个Ops 中,可以在编译阶段中组合在一起。 通过 pyCUDA 和 Cython 之类的包装器将数据由低级代码传输到高级代码。
第二种方法是使用 C++ 等低级语言实现后端,这意味着低级语言 - 高级语言交互是框架内部的,与之前的方法不同,可能更快,因为我们不需要每次都编译整个图。 相反,我们可以用适当的参数来调用编译的方法。
非最佳行为的另一个来源是低级语言的慢速实现。 很难编写有效的代码,我们最好使用具有这些方法优化实现的库。 BLAS 或基本线性代数子程序是优化矩阵运算的集合,最初用 Fortran 编写。 这些可用于执行非常快速的矩阵(张量)操作,并可提供显着的加速。 还有许多其他软件包,如英特尔 MKL,ATLAS,它们也执行类似的功能。 选择哪一个是个人偏好。
假设指令将在 CPU 上运行,BLAS 包通常会进行优化。 在深度学习的情况下,情况并非如此,BLAS 可能无法充分利用GPGPU提供的并行性。 为了解决这个问题,NVIDIA 发布了针对 GPU 优化的 cuBLAS。 现在它已包含在 CUDA 工具包中,这可能是很多人没有听说过的原因。 最后,cuDNN 是一个基于 cuBLAS 功能集的库,提供优化的神经网络特定操作,如 Winograd 卷积和 RNN。
因此,通过使用这些软件包,您可以在框架中获得显著的加速。 加速在机器学习中很重要,因为它是在四小时而不是四天内训练神经网络之间的差异。 在人工智能初创公司快速发展的世界中,这就是成为先锋和追赶游戏之间的区别。 因此,尽可能利用并行性和优化库!
结论
我们终于走到了一个很长的帖子的结尾,非常感谢各位阅读它。 我希望我已经揭开了许多人对深度学习框架怎样剖析的神秘面纱。 我写这篇文章的主要目的是让我更好地理解不同的框架如何做同样的事情。 对于那些高于初级水平但低于专业水平的人(如果你愿意的话,半专业人士),这将是一个非常有用的练习。 一旦你能够理解背后的工作方式,他们就会更容易接近和掌握。 框架在抽象出大多数想法方面做得很好,以便为程序员提供简单的界面。 难怪在学习框架时,大多数概念都不是很明显。
作为一个不仅对深度学习的应用感兴趣而且对该领域的基本挑战感兴趣的人,我相信知道如何在幕后工作是迈向掌握主旨的重要一步,因为它清除了许多误解并提供了一种更简单的方法来思考为什么事情就是这样。 我真诚地相信,优秀的员工不仅知道使用哪种工具,而且还知道为什么该工具是最佳选择。 这篇博客是朝这个方向迈出的一步。
希望你喜欢阅读这篇文章,就像我写这篇文章一样。 请在下面的评论中告诉我您的想法!如果您发现这很有趣,并想了解更多关于我的信息,我很乐意听到您的声音! 你可以在这里找到我的领英个人资料。
参考文献
[1] It’s not straightforward how you would represent text as tensors. The first way is to use a one-hot encoding, which is a very sparse matrix and wastes a lot of space. A more dense representation is word vectors. These are pretty cool and I probably might write another post on them if enough people are interested!
[2] Also, as you will see in the Auto-differentiation part, it’s not clear how you would calculate the derivatives of words. They’re not even continuous!
[3] This is the (in)famous backpropagation algorithm and is central to learning in Multilayered neural networks.
[4] This also means moving the data to GPU or back. I have noticed that in Theano (possibly other frameworks as well), this is the most time-consuming part during execution.
[5] http://www.deeplearning.net/software/theano/optimizations.html
请点击阅读原文查看更多外部链接和参考文献。
原文链接:https://medium.com/@gokul_uf/the-anatomy-of-deep-learning-frameworks-46e2a7af5e47
点击文末【阅读原文】即可观看更多精彩内容:
介绍一个灵活可重复的强化学习研究的新框架
现代博弈论和多代理式强化学习系统
从 MAX 网站中获取模型,一秒开始你的深度学习应用
实例+代码,你还怕不会构建深度学习的代码搜索库吗
斯坦福CS231n李飞飞计算机视觉经典课程(中英双语字幕+作业讲解+实战分享)
等你来译:
安卓 Smart Links 技术背后的机器学习模型
2018年25家值得关注的机器学习初创企业
以上是关于告别选择困难症,我来带你剖析这些深度学习框架基本原理的主要内容,如果未能解决你的问题,请参考以下文章