解读年度数据库PostgreSQL:如何处理并发控制
Posted 数据和云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解读年度数据库PostgreSQL:如何处理并发控制相关的知识,希望对你有一定的参考价值。
此外,我们也成立PostgreSQL学习社群,技术探讨、资料分享、大牛解答,欢迎加入一起进步,入群方式见文末。
之前,我们分享了,
当多个事务同时在数据库中运行时,并发控制是一种用于维持一致性与隔离性的技术,一致性与隔离性是ACID的两个属性。
译者注: ACID指数据库事务正确执行的四个基本要素的缩写,包含原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
从宽泛的意义上来讲,有三种并发控制技术,分别是多版本并发控制(Multi-Version Concurrency Control,MVCC)、严格两阶段锁定(Strict Two-Phase Locking,S2PL)和乐观并发控制(Optimistic Concurrency Control,OCC),每种技术都有多种变体。在MVCC中,每个写操作都会创建一个新版本的数据项,并保留其旧版本。当事务读取数据对象时,系统会选择其中的一个版本,通过这种方式来确保各个事务间相互隔离。MVCC的主要优势在于“读不会阻塞写,写也不会阻塞读”,相反的例子是,基于S2PL的系统在写操作发生时会阻塞相应对象上的读操作,因为写入者获取了对象上的排他锁。PostgreSQL和一些关系型数据库使用一种MVCC的变体,叫作快照隔离(Snapshot Isolation,SI)。
一些关系型数据库(例如Oracle)使用回滚段来实现快照隔离SI。当写入新数据对象时,旧版本对象先被写入回滚段,随后用新对象覆写至数据区域。PostgreSQL使用更简单的方法,即新数据对象被直接插入相关表页中。读取对象时,PostgreSQL根据可见性检查规则,为每个事务选择合适的对象版本作为响应。
SI中不会出现在ANSI SQL-92标准中定义的三种异常,分别是脏读、不可重复读和幻读。但SI无法实现真正的可串行化,因为在SI中可能会出现串行化异常,例如写偏差和只读事务偏差。需要注意的是,ANSI SQL-92标准中可串行化的定义与现代理论中的定义并不相同。为了解决这个问题,PostgreSQL从9.1版本之后添加了可串行化快照隔离(Serializable Snapshot Isolation,SSI),SSI可以检测串行化异常,并解决这种异常导致的冲突。因此,9.1版本之后的PostgreSQL提供了真正的SERIALIZABLE隔离等级(SQL Server也使用SSI,而Oracle仍然使用SI)。
并发控制包含着很多主题,本章重点介绍PostgreSQL独有的内容。故此处省略了锁模式与死锁处理的内容(相关信息请参阅官方文档)。
PostgreSQL中的事务隔离等级
PostgreSQL实现的事务隔离等级如下表所示:
隔离等级 |
脏 读 |
不可重复读 |
幻 读 |
串行化异常 |
读已提交 |
不可能 |
可能 |
可能 |
可能 |
可重复读[1] |
不可能 |
不可能 |
PG中不可能,见第5.7.2小节,但ANSI SQL中可能 |
可能 |
可串行化 |
不可能 |
不可能 |
不可能 |
不可能 |
[1]:在9.0及更低版本中,该级别被当作SERIALIZABLE,因为它不会出现ANSI SQL-92标准中定义的三种异常。但9.1版中SSI的实现引入了真正的SERIALIZABLE级别,该级别已被改称为REPEATABLE READ。
PostgreSQL对DML(SELECT、UPDATE、INSERT、DELETE等命令)使用SSI,对DDL(CREATE TABLE等命令)使用2PL。
5.1 事务标识
每当事务开始时,事务管理器就会为其分配一个称为事务标识(transaction id,txid)的唯一标识符。PostgreSQL的txid是一个32位无符号整数,取值空间大小约为42亿。在事务启动后执行内置的txid_current()函数,即可获取当前事务的txid,如下所示。
testdb=# BEGIN;BEGINtestdb=# SELECT txid_current();txid_current--------------100(1 row)
PostgreSQL保留以下三个特殊txid:
0表示无效的txid。
1表示初始启动的txid,仅用于数据库集群的初始化过程。
2表示冻结的txid,详情参考第5.10节。
txid可以相互比较大小。例如对于txid=100的事务,大于100的txid属于“未来”,且对于txid=100的事务而言都是不可见的,小于100的txid属于“过去”,且对该事务可见,如图5.1(1)所示。
因为txid在逻辑上是无限的,而实际系统中的txid空间不足(4B整型的取值空间大小约42亿),因此PostgreSQL将txid空间视为一个环。对于某个特定的txid,其前约21亿个txid属于过去,其后约21亿个txid属于未来,如图5.1(2)所示。
txid回卷问题将在第5.10节中介绍。
注意,txid并非是在BEGIN命令执行时分配的。在PostgreSQL中,当执行BEGIN命令后的第一条命令时,事务管理器才会分配txid,并真正启动其事务。
图5.1 PostgreSQL中的事务标识
5.2 元组结构
我们可以将表页中的堆元组分为普通数据元组与TOAST元组两类。本节只介绍普通元组。
堆元组由三个部分组成,即HeapTupleHeaderData结构、空值位图及用户数据,如图5.2所示。
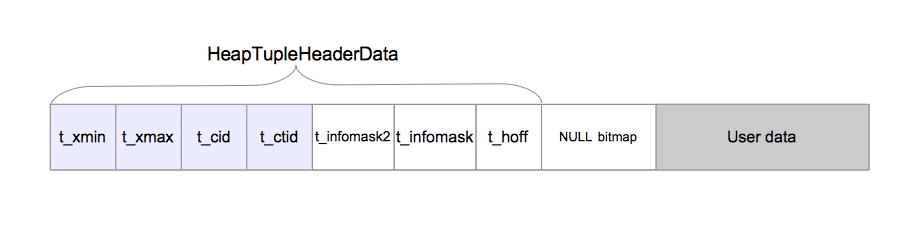
图5.2 元组结构
HeapTupleHeaderData结构在src/include/access/htup_details.h中定义。
typedef struct HeapTupleFields{TransactionId t_xmin; /* 插入事务的ID */TransactionId t_xmax; /* 删除或锁定事务的ID */union{CommandId t_cid; /* 插入或删除的命令ID */TransactionId t_xvac; /* 老式VACUUM FULL的事务ID */} t_field3;} HeapTupleFields;typedef struct DatumTupleFields{int32 datum_len_; /* 可变首部的长度*/int32 datum_typmod; /* -1或者是记录类型的标识 */Oid datum_typeid; /* 复杂类型的oid或记录ID */} DatumTupleFields;typedef struct HeapTupleHeaderData{union{HeapTupleFields t_heap;DatumTupleFields t_datum;} t_choice;ItemPointerData t_ctid; /* 当前元组或更新元组的TID *//* 下面的字段必须与结构MinimalTupleData相匹配 */uint16 t_infomask2; /* 属性与标记位 */uint16 t_infomask; /* 很多标记位 */uint8 t_hoff; /* 首部+位图+填充的长度 *//* ^ - 23 bytes - ^ */bits8 t_bits[1]; /* NULL值的位图——变长的 *//* 本结构后面还有更多数据 */} HeapTupleHeaderData;typedef HeapTupleHeaderData *HeapTupleHeader;
虽然HeapTupleHeaderData结构包含7个字段,但是后续部分中只需要了解4个字段即可。
t_xmin保存插入此元组的事务的txid。
t_xmax保存删除或更新此元组的事务的txid。如果尚未删除或更新此元组,则t_xmax设置为0,即无效。
t_cid保存命令标识(command id,cid),cid的意思是在当前事务中,执行当前命令之前执行了多少SQL命令,从零开始计数。例如,假设我们在单个事务中执行了3条INSERT命令BEGIN;INSERT;INSERT;INSERT;COMMIT;。如果第一条命令插入此元组,则该元组的t_cid会被设置为0。如果第二条命令插入此元组,则其t_cid会被设置为1,以此类推。
t_ctid保存着指向自身或新元组的元组标识符(tid)。如第1.3节中所述,tid用于标识表中的元组。在更新该元组时,t_ctid会指向新版本的元组,否则t_ctid会指向自己。
往期精彩
原创:铃木启修


| | | | |

| | | | |

| | | |
| | | | | | | |
云和恩墨大讲堂 | 一个分享交流的地方
请备注:云和恩墨大讲堂
以上是关于解读年度数据库PostgreSQL:如何处理并发控制的主要内容,如果未能解决你的问题,请参考以下文章