2019国产数据库大盘点
Posted 大数据DT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2019国产数据库大盘点相关的知识,希望对你有一定的参考价值。
导读:虽然国产数据库,相比前几年大火的O2O、共享经济等概念,并没有获得资本的大力追捧,但是我们欣喜地看到,还是有很多IT人在坚持此道。接下来就带大家一起来盘点一下国产数据库的发展现状。

去“IOE”这个概念,最早由王坚院士在刚刚加入阿里时提出,其目标是将IBM 的小型机、Oracle数据库、EMC存储设备从阿里的IT体系中去除,代之以自主研发的系统。
而随着我国IT技术栈的不断演进,去“IOE”已经由一个企业的目标,变成了整个行业的目标,也就是我国必须使信息系统数据,运行在自研系统之上,以防止数据丢失造成的一系列严重后果。
作为一名长期在金融机构工作的IT人,提起对外核心技术依赖时,就不由得想起银行业的心脏——支付系统(CNAPS),原本都是世界银行的援建产物,直到2013年底我们才用自研的二代支付系统将其取代。
回想“IOE”这些年,我国的确在一些很多IT领域取得了长足的进步,比如目前我国移动支付水平就实现了对欧美国家的反超,足以独步世界。
近日,金山办公正式登陆科创版,也标志着雷军梦圆国产Office的“英雄之路”。可以看到这种应用级别的自主掌控,对于我国IT业来说已不是难事。
而且随着国产云计算服务水平的不断发展,国外厂商的小型机和存储,已经不多见,不过IOE中的O也就是Oracle、DB2等国外厂商的数据库,还依旧在我国市场大行其道。
这也反映出,近年来我国IT的一个现象,那就是硬件集成与应用等领域强,但是基础设施突破少。
01 支付宝的核心:OceanBase
OceanBase 是蚂蚁金服自研的金融级分布式关系数据库,号称每一行代码都是自主编写的。
在十年前,阿里的IT人,决定自主研发一款分布式金融级数据库,历经磨练后OceanBase已经能在普通硬件上,实现金融级高可用,并在业内首创“三地五中心”城市级故障自动无损容灾新标准,同时具备在线水平扩展能力,并且勇夺TPC的冠军。
02 深植于场景需求混布数据库:Hubble
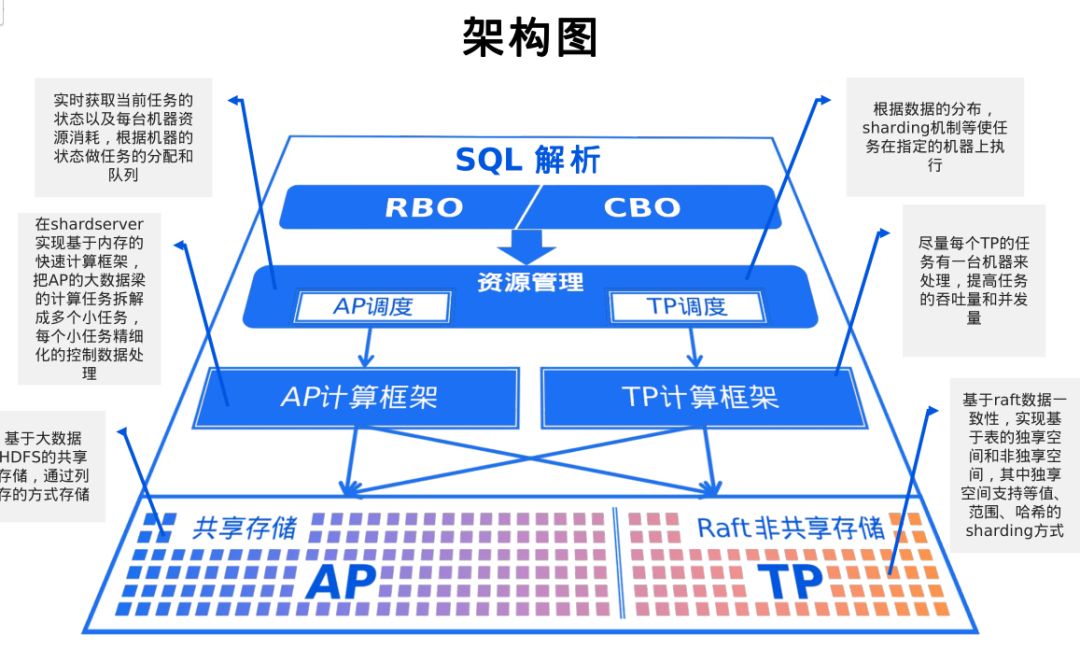
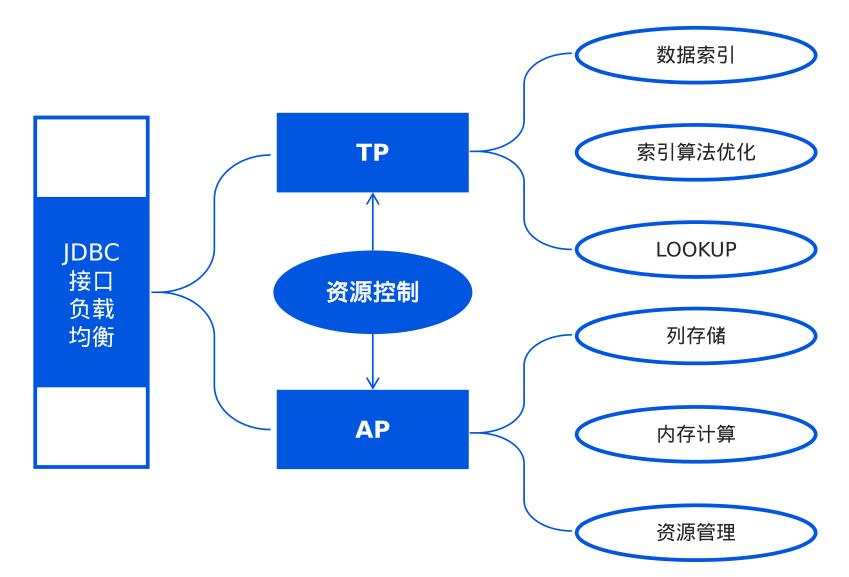
Hubble是天云数据研发的HTAP数据库。所谓HTAP其实就是混合了TP和AP两种模式的数据库。
坦率讲,笔者在刚开始听到一种产品,既能提供TP服务、又能提供AP服务时,感到非常惊讶。
因为,OLAP(On-Line Analytical Processing)是指联机分析技术,打个比方,OLAP就像是私人飞机服务,不计较成本但是要求响应速度,主要用于用户联机交易的处理响应。
而OLTP(on-line transaction processing),则是指联机事务处理,OLTP的最大诉求就是低成本的处理海量数据,有点像海上运输,虽然处理数据量大但是速度慢,适合于客户历史帐单查询、客户画像分析等大数据方面的应用。
以前AP应用的流程比较固定,就像一个仪表盘,只有一两个数仓的管理员在看,但现在那些原本投在大屏的可视化项目,已经全部被推送到了移动端,这也就是TP+AP的个性化数字仓库的需求。
比如一个营业厅应用有六万多人,同时在线需要至少五百个并发/秒,理财经理要在某一时刻,看到大客户的结息、净值等一系列的数据服务,且都是个性化的。
这也就意味着,目前在应用领域,有强烈的需求把AP推到TP的场景里,这两者有机结合,对于大多数人来说,还只是个想法。
不过这两个看似矛盾的目标,竟然真的被天云数据,结合到一起了。其关键技术有以下几个方面:
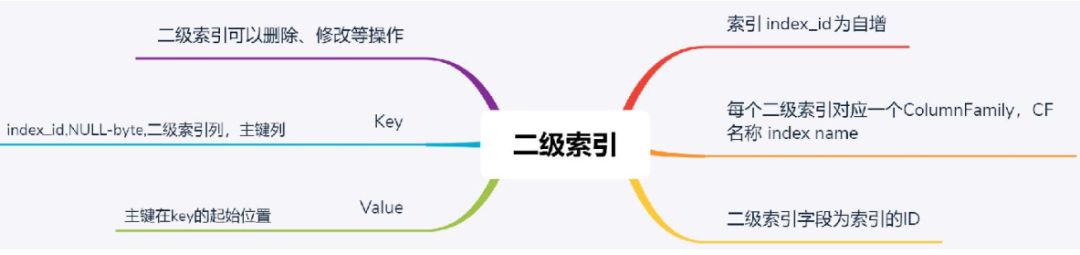
一是在KV数据,再加一层KV索引、以适应高并发的TP需求。
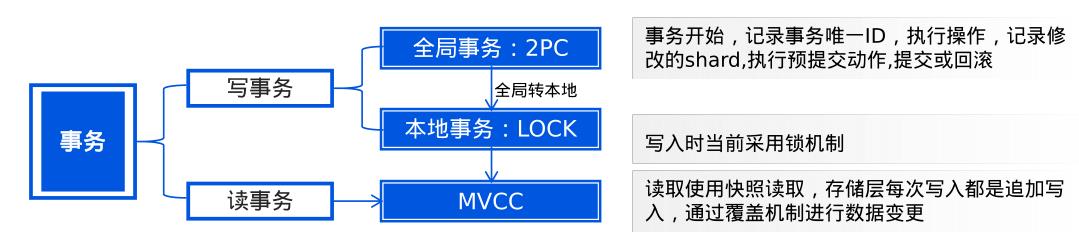
二是通过将全局事务向本地事务锁进行转换,来保证系统的分布式计算一致性。
三是通过资源控制模块,完成TP与AP的结合使用。
03 SQL引擎与NoSQL存储的结合:巨杉数据库
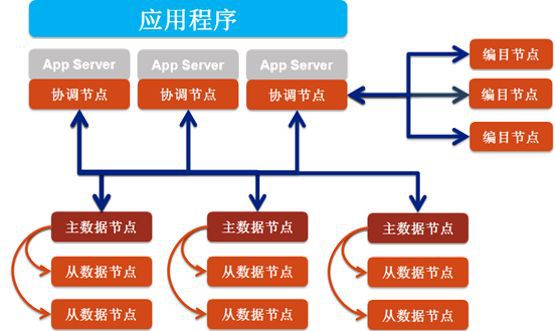
SequoiaDB 巨杉数据库,是一款金融级分布式关系型数据库,也是一款开源产品。笔者认为SequoiaDB最大的贡献在于将标准SQL、事务与NoSQL的分布式存储相结合。
https://github.com/SequoiaDB/SequoiaDB
巨杉数据库使用JSON为标准存储格式,既可以描述关系型结构,能最大限度保留现有的应用资产;也可以描述非关系型结构。
这些使巨杉,可以把非结构化的文件和结构化的描述项一起存储,而不是索引+文件存储,从而实现适当降低范式维度和JOIN操作的复杂度。
而且,在分布式存储的基础上,其还添加了分布式SQL引擎,借此可以提供高并发、低延时和批量计算SQL能力以及ACID和事务支持。
其整体架构如下:
巨杉数据库在金融领域应用案例很多,相信他们SQL引擎与NoSQL存储的理念还会支撑他们越走越远。
04 产品线齐全的数据库:GBase和达梦
武汉达梦和天津南大通用,绝对算得上是国内数据库厂商中产品线最齐全的两家了。据笔者不完全统计,南大通用打造了GBase 8a、8t、8m、8s、8d、UP、InfiniData一体机等多款数据库软硬件产品,而达梦也不遑多让他们产品线包括了达梦7、8、ETL、TDD、HS、MPP等等。下面挑重点向大家介绍。
GBase 8a:就是我们日常所熟知的用于大数据分析的系统库。
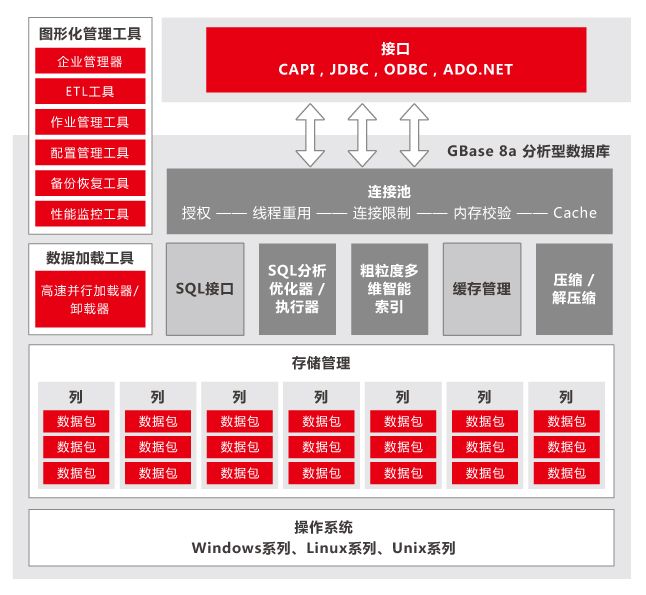
GBase 8a能够实现大数据存储管理和高效分析,据测试,它能在PB级数据规模下,实现数据查询的秒级响应;实现千亿级文本条目全文检索的秒级响应;并且提供全过程可视化的数据查询分析及展现工具。
GBase 8t:一款对标Oracle的数据库。据称,其OLTP事务处理性能,已达到Oracle数据库的水平,能够在90%以上的场景中替代Oracle。
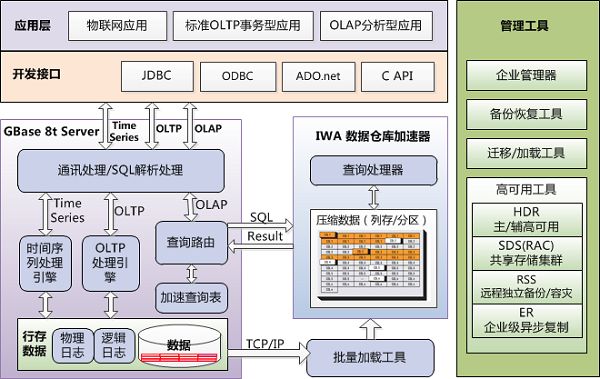
GBase 8t的关键技术有如下几方面:
1. 事务机制
完全支持传统主流事务数据库的事务机制锁技术,有效支撑高度并发的事务密集型应用场景。
2. 存储技术
GBase 8t产品的存储有物理的和逻辑的两种结构。物理结构中包含数据卷(Chunk)、数据段(Extent)和数据页(Page);逻辑结构包含数据空间(DbSpace)和表空间(TableSpace)。
3. 索引技术
GBase 8t产品提供了索引技术来提升数据查询操作的性能。GBase 8t产品支持的索引包括B-Tree索引、R-Tree索引、函数索引和用户自定义索引。
4. 高可用技术
GBase 8t产品提供了高可用集群技术,使用这些技术可以满足数据复制、共享存储、同城备份、远程容灾和两地三中心的整体灾备解决方案的要求。
当前,Gbase和达梦的产品均已经在金融、电信、电力等多个行业得到应用与验证了,使用场景非常广泛可谓我国国产数据库的双子星座了。

05 物联网时代的数据库TDengine、CTSDB
随着互联网的高速发展、大数据的迅速膨胀和物联网的飞速崛起,我们发现生活和工作中的大部分数据渐渐和时间产生了关联。
比如,微信运动的实时步数、股票每天的收盘价格、共享单车的设备状态等等。为了存储这些与时间相关的数据使用传统数据库其实问题很多。
比如,传统关系型数据库,在存储海量的时序数据场景下,存在的问题:
存储成本大:对于时序数据压缩不佳,需占用大量机器资源;
维护成本高:单机系统,需要在上层人工的分库分表,维护成本高;
写入吞吐低:单机写入吞吐低,很难满足时序数据千万级的写入压力;
而Hadoop等NoSQL数据库也有问题:
数据延迟高:离线批处理系统,数据从产生到可分析,耗时数小时、甚至天级;
查询性能差:不能很好的利用索引,依赖MapReduce任务,查询耗时一般在分钟级。
让你以在物联网时代需要与之特点相应的数据库产品来提供服务,目前我国在时序数据库方面主要有TDengine、CTSDB两款产品。
这里主要带大家了解一下腾讯时序数据库CTSDB:CTSDB(Cloud Time Series Database)是一种分布式、高性能、多分片、自均衡的时序数据库,针对时序数据的高并发写入、存在明显的冷热数据、IoT用户场景等做了大量优化,同时也支持各行业的日志解析和存储,其架构如下图所示。
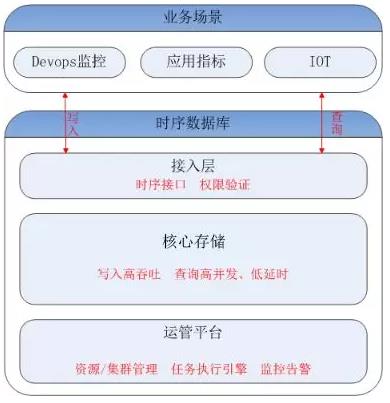
在CTSDB和磁盘之间有一层FileSystem Cache的系统缓存,以使得能够更快地处理搜索请求。
作为腾讯唯一的时序数据库,CTSDB支撑了腾讯内部20多个核心业务(微信彩票、财付通、云监控、云数据库、云负载等)。
其中,云监控系统的记录了腾讯内部各种软硬件系统的实时状态,CTSDB承载了它所有的数据存储,在每秒千万级数据点的写入压力、每天20TB+数据量的写入场景下稳定运行,足以证明CTSDB可以稳定支撑物联网的海量数据场景。
06 互通有无,共同成长
除了上述这些数据库之外,我国还有不少基于mysql、PosgreSQL等开源数据库内核研发的产品。
比如腾讯基于MySQL的TDSQL、华为基于PosgreSQL的GaussDB、中兴同样基于MySQL的GoldenDB,他们也都得到了相当广泛的应用。
尤其是承载着微众银行和威富通等多个重量级金融应用的TDSQL,凭借远超开源版MySQL的性能,真正做到了青出于蓝而胜于蓝。
可以说,我国自研数据库在各个方面,都已取得极大进步,这里也呼吁,国内数据库厂商能尽量将社区版本开源,与业界互通有无,共同成长。

以上是关于2019国产数据库大盘点的主要内容,如果未能解决你的问题,请参考以下文章
2021年Python十佳ML库大盘点,国产选手GitHub半年获5000+star!