技术分享 | 关于数据库设计的总结 Posted 2021-04-29 爱可生开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术分享 | 关于数据库设计的总结相关的知识,希望对你有一定的参考价值。
良好的数据库设计不仅仅能够满足数据库用户的需求,而且对应用程序有着非常重大的影响。 然而数据库设计是一个复杂的过程,良好的数据库设计并不是一件简单的事。 对于小型的应用,理解需求的数据库设计者可能直接就能给出要构建的关系、关系的属性以及其上的约束。 但是现实的应用往往是复杂的,通常没有一个人能够理解应用所有的数据需求并直接给出最终的数据库设计。 因此遵循一个数据库设计的方法是很有必要的。 数据库设计通常包括以下阶段:
2. 选择数据模型,并采用所选数据模型的概念将需求转化为数据库的概念模式
本文将主要介绍如何构建一个数据模型,并将数据模型转化为关系模式,以及如何评价关系模式的合理性。
对于刻画用户的数据需求和物理设计并不会过多的介绍。
因为数据需求来自于需求分析,这在软件工程中是一个很大的过程;
而物理设计和所选择的 DBMS 有着很大的关系。
实体-关系(E-R)数据模型是在数据库最经常使用的概念模型。
因为它能够将现实世界的含义和交互映射到概念模式上,使得技术人员和非技术人员都能够用统一的语言去描述用户的数据需求。
这一节首先将会介绍 E-R 模型,然后将说明如何将 E-R 模型转化为关系模式。
E-R模型有三个基本概念:
实体集、联系集和属性。
这一小节首先会介绍这三个基本概念,然后将说明 E-R 模型上定义的一些约束。
实体集
实体
是现实世界中可区别于所有其他对象的一个“事物”或者“对象”。
比如公司里每个人都是一个实体。
每个实体都有一些描述性性质(被称为属性),其中一些性质的可以唯一标识一个实体(被称为码)。
比如工号将唯一标识一位员工。
除了现实世界中实实在在的事物可以看作实体,一些抽象的事物也可以作为实体。
比如购物订单。
实体集在 E-R 图中使用分为两部分的矩形表示,第一部分包含实体集的名字,第二部分包含实体集中的所有属性,并且可以在唯一标识实体的属性下面加上下划线。
实体集
是相同性质的实体的集合。
比如一个公司的所有员工的集合可以定义为实体集 employee。
有一些实体集本身找不出唯一标识实体集中单个实体的属性,它必须依附于另一个实体才能存在,这种实体集叫做弱实体集。
比如将 stackoverflow 上的答案作为一个实体,那么所有的答案就是一个弱实体集,因为每个答案都必须依附问题这个实体才能存在,它的唯一标识属性是问题 ID 和答案 ID。
与弱实体集相对应的就是那些本身的属性就能唯一标识单个实体的强实体集。
弱实体集在 E-R 图中与强实体的表示类似,不同的是它的唯一标识属性下面是虚下划线。
联系集
联系
是指多个实体间的相互关联。
比如一个项目和开发人员的联系 develop,这一联系指明这个项目是由哪些开发人员开发的。
联系也可以有描述性属性。
比如 develop 联系可以增加 startsAt 属性表明开发人员是哪天开始加入到这个项目的。
联系集
是相同类型联系的集合。
联系集在 E-R 图中使用菱形表示,而与弱实体集关联的联系集则使用双菱形表示。
联系集的每个属性都放在一个矩形中,通过虚线与联系集相连接。
属性
前面介绍实体集的时候介绍过属性,这里将介绍属性的分类:
简单和复合属性:
不能划分为更小的部分的属性称为简单属性,可以再分为更小的部分称为复合属性。
比如一个 DBMS 的类型就是简单属性,而地址是一个复合属性,它可以分为街道名、门牌号等。
单值和多值属性:
对于一个特定的实体,如果一个属性只有一个值,就称为单值属性,否则为多值属性。
比如一个人的身份证号是单值的,但是他的手机号是多值的。
派生属性:
这类属性的值可以从别的相关的属性或者实体派生出来。
比如一个人的信息有出生日期和年龄,那么年龄就是一个派生属性。
约束
仅仅有实体和联系并不能完全刻画现实事物之间的关系,比如一个实体通过联系集关联到另一实体的个数、一个实体参与到联系的个数。 映射基数 用来表示一个实体通过联系集关联到另一个实体的个数,它必然是以下四种情况之一:
一对一: 实体集 A 中的一个实体至多和实体集 B 中的一个实体相关联,反之亦然。
一对多: 实体集 A 中的一个实体可以与实体集 B 中的任意数目相关联,而 B 中的一个实体至多与 A 中的一个实体相关联。
多对一: 实体集 A 中的一个实体至多和实体集 B 中的一个实体相关联,而 B 中的一个实体可以与 A 中的任意数目相关联。
多对多: 实体集 A 中的一个实体可以与实体集 B 中的任意数目相关联,B 中的一个实体也可以与 A 中的任意数目相关联。
一个实体集参与到联系的个数通过参与约束来描述。
如果一个实体集 E 中的每个实体都参与到一个联系集 R 的至少一个联系中,则称实体集 E 在联系集 R 中是全部参与;
如果 E 中只有部分实体参与到 R 的联系中,则称实体集 E 在联系集 R 中是部分参与。
转化为关系模式
E-R 模型是现实世界的含义和交互在概念模型上的体现,而关系模式是数据库中全体数据的逻辑结构和特征的描述。
因此将 E-R 模型转化为关系模式是一个里程碑式的阶段,在这之后到最后的库表结构就非常接近了。
下面将介绍具体的转化方式。
具有简单属性的强实体集的表示
具有简单属性的强实体集与其对应的关系模式的属性是一一对应的,并且强实体集的主码就是关系模式的主码。 比如一个公民的实体集有两个属性: 身份证 ID、名字,那么对应的模式为:
chinese_public(ID, name)
具有复杂属性的强实体集的表示
对于具有复杂属性的强实体集的转化稍微复杂一点:
对于复合属性自身并不直接创建一个属性,而是将它所有的简单属性添加到关系模式中。
对于多值属性,我们将创建一个新的关系模式。 新的关系模式中的一个元组对应一个值,并且使用多值属性所在的实体集的主码进行关联。
对应派生属性,我们并不在关系模式中显示的表达出来。
弱实体集的表示
弱实体集转化为关系模式和强实体集类似,不同的是它的主码包括它依赖的实体集的主码和它自身的分辨符。
联系集的表示
联系集转化而来的关系模式的属性是它自身的属性和参与到联系的所有实体集的主码的并集。 关系模式的主码选择可以分为以下情况:
对于多对多的二元联系,参与的实体集的主码的并集成为主码。
对于一对一的二元联系集,任何一个实体集的主码都可以选为主码。
对于一对多或者多对多的二元联系集,联系集中“多”的那方实体集的主码成为主码。
对于 n 元联系集,联系集中非“一”的所有实体集的主码的并集成为主码。
在将联系集转化为关系模式时会出现关系模式的数量少于联系集的数量的情况。
这是因为模式的冗余和模式的合并的存在。
模式的冗余
考虑一个弱实体集,它本身就包括它所依赖的强实体集的主码。
如果这个弱实体集和它所依赖的强实体集的联系集没有其他属性,那么所有出现在联系集中属性都将出现在弱实体集中。
因此弱实体集转化而来的关系模式是包括了联系集转化而来的关系模式的所有属性。
这种情况下,不需要为联系集给出对应的关系模式。
考虑实体集 A 到实体集 B 的一个多对一的联系集 AB。
按照前面的方法,我们将得到三个关系模式:
A、B 和 AB。
那么我们可以将 A 和 AB 模式合并成包含两个模式的所有属性的并集的模式,并且合并后模式的主码就是 A 的主码。
如果 A 是全部参与的,那么合并后模式中来自 B 的属性都是有值的;
否则 A 中未参与联系集的元组在合并后模式对应的元组中,来自 B 的属性是 NULL。
对于一对一的联系集,它的关系模式可以合并到任意一个实体集中。
前面介绍了 E-R 模型以及如何将 E-R 模型转化为关系模式,但是得到的关系模式就是一个好的设计吗?
答案显然是不一定的,如果 E-R 模型本身质量就不高,那么得到关系模式大概率质量也是不高的。
要回答这个问题,首先需要明确什么样的设计是好的或者是不好的,然后才能做出评价。
对于不好的设计,我们需要给出一种方法将它变成一个好的设计。
一个不好的设计
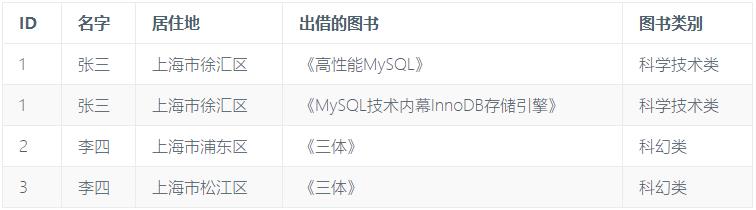
这是一个图书馆图书当前出借的表,所有的信息都保存在这张表中。
这张表存在什么样的问题呢?
首先是数据冗余的问题。
如果一个人多次借了多本书,那么这个人的信息会多次重复;
如果一本书被多个人借过,那么这本书的信息也会多次重复。
而数据冗余会带来数据一致性的问题。
修改一个人的信息需要更新他的所有借书记录;
修改一本书的信息同样需要更新所有包括这本书的记录。
其次是数据完整性的问题。
一个图书馆的会员如果没有借过书,那么将无法保存他的信息;
一本新书如果没有被借过,那么这本书的信息也将无法保存;
如果一个人注销自己的账号,而有一本书只有他借过,那么这本书的信息也将随之消失。
应用范式进行规范化
前面通过一个例子说明了不好的设计会有数据冗余和完整性的问题。
下面将通过范式将其规范化,以消除这些问题。
第一范式
第一范式
要求每个列的值域都是由原子值组成,每个字段的值都只能是单一值,并且每一行需要有主键。
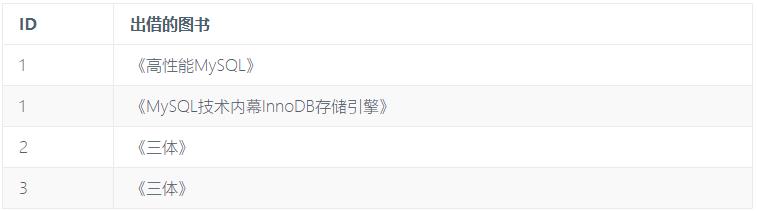
以前面的例子为例,为了满足第一范式,我们需要将出借的图书和图书类别的多个值放到不同的行中,并且将 ID 和出借的图书作为主键(假设图书名不会重复)。
下面是修改后的结果:
显然,第一范式只能让表看起来更好看一些,对于前面的问题并没有实质性的解决。
所以,接下来需要增加约束。
第二范式
这里需要解释几个名词:
也许有人会觉得完全函数依赖的解释看起来和没解释是一样的,所以这里使用上面的例子进行说明。
上面提到过,我们使用 ID 和出借的图书作为主键,那么 ID 和出借的图书一旦确定,名字、居住地也随之确定,即函数(ID, 出借的图书) -> (名字, 居住地)成立。
但是,如果 ID 确定了,名字、居住地也能被确定下来,所以对于(ID, 出借的图书)的真子集(ID),函数(ID) -> (名字, 居住地)依然成立。
所以上面的表不满足第二范式。
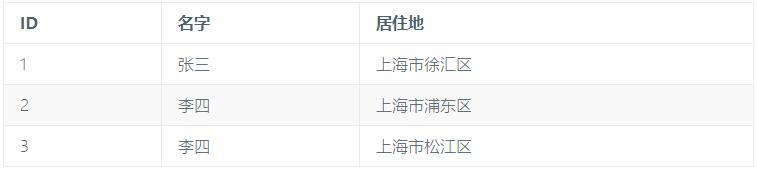
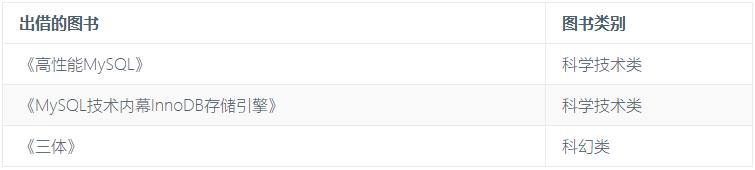
我们需要对这张表进行拆分为会员表和图书表以及图书当前出借表:
第三范式
从上面的例子来看,通过第二范式的改造,之前提到的问题已经得到了解决。
那么为什么又要有第三范式呢?
首先我们来看一个满足第二范式但是仍然存在前面问题的例子。
这个关系模式的主键是图书名,显然它满足第一范式。
因为主键只有一个字段,非主属性对于所有主属性一定是完全函数依赖,所以它也满足第二范式。
但是如果在给这张表增加一本人民邮电出版社出版的《深入理解 mysql
为了消除这种冗余,第三范式就被提出来了。
第三范式 需要满足以下两点:
什么是传递函数依赖呢?
这里不给形式化的定义,而以前面的例子来解释。
前面的例子中因为图书名是主键,所以函数(图书名) -> (出版商)是成立的。
同时我们知道出版商的地址是确定的,所以函数(出版商) -> (出版商地址)也是成立的。
所以就有(图书名) -> (出版商) -> (出版商地址)成立。
这个时候我们也称出版商地址函数依赖于图书名。
为了消除非主属性对于主码的传递函数依赖,我们将上面的表拆分为两个表:
BCNF
前面提到的第二范式和第三范式分别消除了非主属性对于主属性的部分函数依赖和传递依赖,那么如果主属性对于主键存在部分函数依赖和传递函数依赖会怎么样呢? 举个例子,假设:
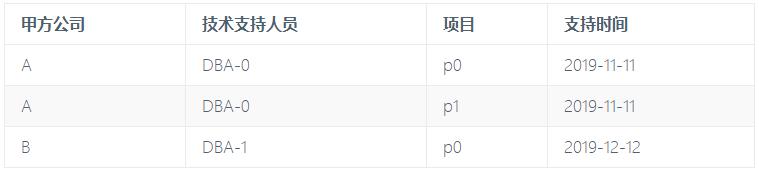
那么考虑关系模式 现场支持(甲方公司,技术支持人员,项目名,支持时间),它的主键是甲方公司、技术支持人员、项目名。
它是满足第三范式的,因为不存在非主属性对于主键的部分函数依赖和传递依赖。
但是它仍然是有问题的:
如果技术支持人员被调到另一家甲方公司,那么该技术人员关联的所有记录都要修改;
同时,如果一个甲方公司和数据库公司有多个项目,那么甲方公司和技术支持人员都需要重复。
所以,满足第三范式的关系模式并不一定能够完全解决前面的问题。
针对这个问题,BCNF 就被提出来了,这里给出它的要求:
上面的例子主属性(甲方公司)部分依赖于主键(技术支持人员,项目名)。
修改之后的关系模式为:
小结
回顾 E-R 关系模型和范式,其实我们可以发现:
不满足第一范式的关系模式可能是根本没有建立 E-R 模型,直接将所有信息放到一张表; 或者是 E-R 模型没有主键; 或者是 E-R 模型转化为关系模式时多值属性、复合属性没有处理好
不满足其他范式最大的原因应该是没有正确的识别实体集和关系集。 比如第二范式中的例子,会员实体集和图书实体集的信息完全混到了一起; 第三范式中图书实体集和出版商实体集混到了一起; BCNF 例子则更可能来自实体集甲方公司、技术支持人员、项目的一个三元关系集。
进一步地,如果 E-R 模型的质量高,那么得到的关系模式满足的更高等级的范式的可能性也会大很多。
本人工作经验有限,并没有实际经历完整的建模、规范化,只是从有经验的人了解到大多数业务公司会做的是建模,而规范化比较少。
这大概是他们的模型都建立的很好吧(:。
当然,实际设计数据库时也不一定要满足范式,比如有时为了业务的方便,也会选择部分数据的冗余。
本文只介绍了数据库设计一小部分,这一小部分对于一个高质量的数据库设计是很重要的,但是也是远远不够的。
为了得到一个高质量的数据库设计,还需要从两方面去努力。
一方面,在 E-R 模型的上游需要做好领域模型的构建,以便于对需要构建的系统有更深入的理解,从而得到更高质量的 E-R 模型。
另一个方面,需要非常了解使用的 DBMS 的特性。
比如使用 MySQL,需要知道使用哪种类型的存储引擎存储是合适的,使用什么类型的字段是合适的等;
有的人还建议不使用关系模式的主键,而是使用自增主键。
这两方面也不是完全孤立的,比如要为哪些字段创建索引要基于查询来考虑,而最经常会有的查询其实在业务建模的时候就能明确的。
总的来说,数据库设计是一个系统的工程,需要对整个系统都有详细的了解才能做好。
诊断范围支持:
Mycat 的故障诊断、源码分析、性能优化
服务支持渠道:
技术交流群,进群后可提问
osc@actionsky.com
现场拜访,线下实地,1天免费拜访
征稿内容:
格式:.md/.doc/.txt
主题:MySQL、分布式中间件DBLE、数据传输组件DTLE相关技术内容
要求:原创且未发布过
奖励:作者署名;200元京东E卡+社区周边
投稿方式:
邮箱:osc@actionsky.com
格式:[投稿]姓名+文章标题
喜欢点 “分享” ,不行就 “在看”
以上是关于技术分享 | 关于数据库设计的总结的主要内容,如果未能解决你的问题,请参考以下文章
关于Dashboard设计的总结
技术分享| 浅谈调度平台设计
技术分享| 浅谈调度平台设计
高手UI设计师干货总结分享品牌LOGO设计的过程要求及方法
GaussDB NoSQL架构设计分享
PF2.1版本总结,在设计过程中遇到的问题以及技术分享