58沈剑解读:数据库典型架构实践
Posted GitChat精品课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了58沈剑解读:数据库典型架构实践相关的知识,希望对你有一定的参考价值。
01
-
uid为用户ID,主键。 -
uname, passwd, sex, age, nickname, …等为用户的属性。
为了方便大家理解,后文图片说明如下:
-
“灰色”方框,表示service,服务。 -
“紫色”圆框,标识master,主库。 -
“粉色”圆框,表示slave,从库。
02
单库架构
-
user-service: 用户中心服务,对调用者提供友好的RPC接口。 -
user-db: 一个库进行数据存储。
03
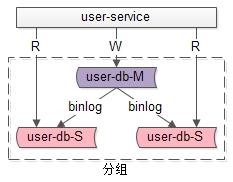
1. 分组架构究竟解决什么问题?
答:大部分互联网业务读多写少,数据库的读往往最先成为性能瓶颈,如果希望:
-
线性提升数据库读性能。 -
通过消除读写锁冲突提升数据库写性能。 -
通过冗余从库实现数据的“读高可用”。
04
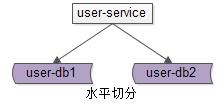
1. 分片架构究竟解决什么问题?
-
线性提升数据库写性能,需要注意的是,分组架构是不能线性提升数据库写性能的。 -
降低单库数据容量。
一句话总结,分片解决的是“数据库数据量大”问题,所实施的架构设计。
05
分组+分片架构
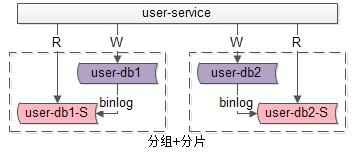
-
通过分片来降低单库的数据量,线性提升数据库的写性能。 -
通过分组来线性提升数据库的读性能,保证读库的高可用。
06
User(uid, uname, passwd, sex, age, …)
User_EX(uid, intro, sign, …)
-
垂直切分开的表,主键都是uid。 -
登录名,密码,性别,年龄等属性放在一个垂直表(库)里。 -
自我介绍,个人签名等属性放在另一个垂直表(库)里。
-
长度较短,访问频度较高的放在一起。 -
长度较长,访问频度较低的放在一起。
这是因为,数据库会以行(row)为单位,将数load到内存(buffer)里,在内存容量有限的情况下,长度短且访问频度高的属性,内存能够load更多的数据,命中率会更高,磁盘IO会减少,数据库的性能会提升。
06
-
业务初期用单库。 -
读压力大,读高可用,用分组。 -
数据量大,写线性扩容,用分片。 属性短,访问频度高的属性,垂直拆分到一起。
从《从“单KEY”类业务》中了解到:
水平切分方式
水平切分后碰到的问题
用户侧与运营侧架构设计思路
用户前台侧,“建立非uid属性到uid的映射关系”最佳实践
运营后台侧,“前台与后台分离”最佳实践
从《“1对多”类业务》这篇文章,能够了解到:
“1对多”类业务,在架构上,采用元数据与索引数据分离的架构设计方法;
对于元数据的存储,在数据量较大的情况下,有三种常见的切分方法。
从《“多对多”类业务》这篇文章,能够了解到:
好友业务是一个典型的多对多关系,又分为强好友与弱好友;
数据冗余是一个常见的多对多业务数据水平切分实践;
冗余数据的常见三种方案;
实现一致性要实践的常见三种方案。
-
前台、后台系统web/service/db分离解耦,避免后台低效查询引发前台查询抖动。 -
采用前台与后台数据冗余的设计方式,分别满足两侧的需求。 -
采用“外置索引”(例如ES搜索系统)或者“大数据处理”(例如HIVE)来满足后台变态的查询需求。
扫码了解《搞定数据库水平切分》专栏详情
-
可用性: 不管是主库实例,还是从库实例,如果数据库实例挂了,如何不影响数据的读和写。 -
读性能: 互联网业务大多是读多写少的业务,如果提升数据库的读性能是架构设计中必须考虑的问题。 -
一致性: 数据一旦冗余,就可能出现一致性问题,如何解决主库与从库之间的不一致,如何解决数据库与缓存之间的不一致,也是需要重点设计的。 -
扩展性: 如何在不停服务的情况下扩充数据表的属性,实施数据迁移,实施存储引擎的切换,架构设计上都是十分有讲究的。 -
分布式SQL语句: 单库情况下,所有SQL语句的执行都没问题问题,一旦实施了水平切分,如何实现SQL的集函数,分页,非patition key上的查询都成了大问题。
点击阅读原文,订阅沈剑大佬的专栏。
以上是关于58沈剑解读:数据库典型架构实践的主要内容,如果未能解决你的问题,请参考以下文章