数据库(纯手写,极度适合巩固基础面试突击)
Posted 大数据健身侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库(纯手写,极度适合巩固基础面试突击)相关的知识,希望对你有一定的参考价值。
本文的初衷是为了一边自己复习,一边为了各位读者写一点东西;
本文极度适合巩固基础,面试突击,之后我还会一边复习一边整理出多线程、分布式、高并发、Hadoop、微服务等一类的文章;
不管是大数据方向还是JAVA后端,JAVA、JVM、线程并发这些知识是少不了的。
如果在文章中发现错误,欢迎及时批评指正,若还有尚缺的知识点也可及时提出,本人及时更新。
目录 十三、 数据库 13.1 分布式锁 13.2 索引 13.3 数据库三范式 13.4 数据库事务 13.5 存储过程 13.6 触发器 13.7 数据库并发策略 13.8 数据库锁 13.9 基于Redis分布式锁 13.10 分区分表 13.11 两阶段提交协议 13.12 三阶段提交协议 13.13 柔性事务 13.14 CAP |
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、 更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同 的存储引擎,还可以 获得特定的功能。现在许多不同的数据库管理系统都支持多种不同的数据引 擎。存储引擎主要有:1. MyIsam , 2. InnoDB, 3. Memory, 4. Archive, 5. Federated 。
InnoDB 底层存储结构为B+树, B树的每个节点对应innodb的一个page,page大小是固定的, 一般设为16k。其中非叶子节点只有键值,叶子节点包含完成数据。
-
经常更新的表,适合处理多重并发的更新请求。 -
支持事务。 -
可以从灾难中恢复(通过bin-log日志等)。 -
外键约束。 只有他支持外键。 -
支持自动增加列属性auto_increment。
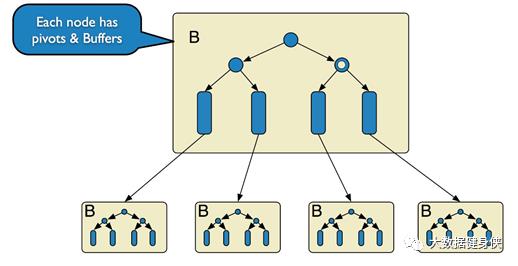
TokuDB 底层存储结构为Fractal Tree,Fractal Tree的结构与B+树有些类似, 在Fractal Tree 中,每一个child指针除了需要指向一个child节点外,还会带有一个Message Buffer ,这个 Message Buffer 是一个FIFO的队列,用来缓存更新操作。
例如,一次插入操作只需要落在某节点的Message Buffer就可以马上返回了,并不需要搜索到叶 子节点。这些缓存的更新会在查询时或后台异步合并应用到对应的节点中。
MyIASM是mysql默认的引擎,但是它没有提供对数据库事务的支持,也不支持行级锁和外键, 因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。
ISAM 执行读取操作的速度很快,而且不占用大量的内存和存储资源。在设计之初就预想数据组织 成有固定长度的记录,按顺序存储的。---ISAM是一种静态索引结构。
缺点是它不支持事务处理。
Memory(也叫HEAP)堆内存:使用存在内存中的内容来创建表。每个MEMORY表只实际对应 一个磁盘文件。MEMORY 类型的表访问非常得快,因为它的数据是放在内存中的,并且默认使用 HASH索引。但是一旦服务关闭,表中的数据就会丢失掉。 Memory同时支持散列索引和B树索 引,B树索引可以使用部分查询和通配查询,也可以使用<,>和>=等操作符方便数据挖掘,散列索 引相等的比较快但是对于范围的比较慢很多。
索引(Index)是帮助 MySQL 高效获取数据的数据结构。常见的查询算法,顺序查找,二分查找,二 叉排序树查找,哈希散列法,分块查找,平衡多路搜索树B树(B-tree)
-
选择唯一性原则
-
为经常需要排序、分组和联合操作的字段建立索引 -
为经常作为查询条件的字段建立索引 -
限制索引的数目
-
尽量使用数据量少的索引
-
尽量使用前缀来索引 -
删除不再使用或者很少使用的索引 -
最左前缀匹配原则(非常重要的原则) -
尽量选择分区度高的列作为索引 -
索引列不能参与计算,保持列 “干净” : 带行数的查询不参与索引 -
尽量的扩展索引,不要新建索引
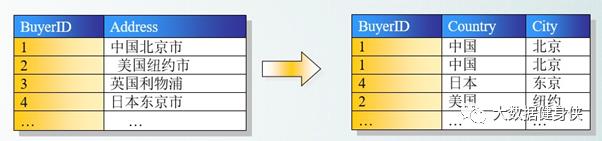
第一范式的目标是确保每列的原子性:如果每列都是不可再分的小数据单元(也称为小的原子 单元),则满足第一范式(1NF)
首先满足第一范式,并且表中非主键列不存在对主键的部分依赖。第二范式要求每个表只描述一 件事情。

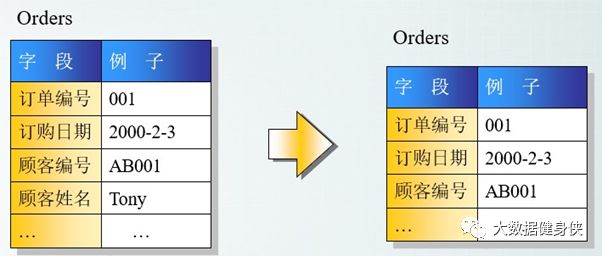
第三范式定义是,满足第二范式,并且表中的列不存在对非主键列的传递依赖。除了主键订单编 号外,顾客姓名依赖于非主键顾客编号。
事务(TRANSACTION)是作为单个逻辑工作单元执行的一系列操作,这些操作作为一个整体一起向 系统提交,要么都执行、要么都不执行 。事务是一个不可分割的工作逻辑单元
事务必须具备以下四个属性,简称ACID 属性:
-
原子性(Atomicity)
事务是一个完整的操作。事务的各步操作是不可分的(原子的);要么都执行,要么都不执行。
-
一致性(Consistency)
当事务完成时,必须处于一致状态。
-
隔离性(Isolation)
对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,它不应以任何方 式依赖于或影响其他事务。
-
永久性
事务完成后,它对数据库的修改被永久保持,事务日志能够保持事务的永久性。
-
尽量利用一些sql语句来替代一些小循环,例如聚合函数,求平均函数等。 -
中间结果存放于临时表,加索引。 -
少使用游标。sql 是个集合语言,对于集合运算具有较高性能。而 cursors 是过程运算。比如 对一个 100 万行的数据进行查询。游标需要读表 100 万次,而不使用游标则只需要少量几次 读取。 -
事务越短越好。sqlserver 支持并发操作。如果事务过多过长,或者隔离级别过高,都会造成 并发操作的阻塞,死锁。导致查询极慢,cpu占用率极低。 -
使用try-catch处理错误异常。 -
查找语句尽量不要放在循环内。
触发器是一段能自动执行的程序,是一种特殊的存储过程,触发器和普通的存储过程的区别是:触发器是当对某一个表进行操作时触发。诸如:update、insert、delete 这些操作的时候,系统 会自动调用执行该表上对应的触发器。SQL Server 2005 中触发器可以分为两类:DML 触发器和 DDL 触发器,其中 DDL 触发器它们会影响多种数据定义语言语句而激发,这些语句有 create、 alter、drop语句。
并发控制一般采用三种方法,分别是乐观锁和悲观锁以及时间戳。
乐观锁认为一个用户读数据的时候,别人不会去写自己所读的数据;悲观锁就刚好相反,觉得自 己读数据库的时候,别人可能刚好在写自己刚读的数据,其实就是持一种比较保守的态度;时间 戳就是不加锁,通过时间戳来控制并发出现的问题。
悲观锁就是在读取数据的时候,为了不让别人修改自己读取的数据,就会先对自己读取的数据加 锁,只有自己把数据读完了,才允许别人修改那部分数据,或者反过来说,就是自己修改某条数 据的时候,不允许别人读取该数据,只有等自己的整个事务提交了,才释放自己加上的锁,才允 许其他用户访问那部分数据。
时间戳就是在数据库表中单独加一列时间戳,比如“TimeStamp”,每次读出来的时候,把该字 段也读出来,当写回去的时候,把该字段加1,提交之前 ,跟数据库的该字段比较一次,如果比数 据库的值大的话,就允许保存,否则不允许保存,这种处理方法虽然不使用数据库系统提供的锁 机制,但是这种方法可以大大提高数据库处理的并发量,
以上悲观锁所说的加“锁”,其实分为几种锁,分别是:排它锁(写锁)和共享锁(读锁)。
行级锁是一种排他锁,防止其他事务修改此行;在使用以下语句时,Oracle会自动应用行级锁:
-
INSERT、UPDATE、DELETE、SELECT … FOR UPDATE [OF columns] [WAIT n | NOWAIT]; -
SELECT … FOR UPDATE语句允许用户一次锁定多条记录进行更新 -
使用COMMIT或ROLLBACK语句释放锁。
表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分 MySQL 引擎支持。常使 用的 MYISAM 与 INNODB 都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁 (排他锁)。
页级锁是 MySQL 中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折中的页级,一次锁定相邻的一组记录。BDB支持页级锁
-
获取锁的时候,使用setnx(SETNX key val:当且仅当key不存在时,set一个key 为 val 的字符串,返回 1;若 key 存在,则什么都不做,返回 0)加锁,锁的 value 值为一个随机生成的 UUID,在释放锁的时候进行判断。并使用 expire 命令为锁添 加一个超时时间,超过该时间则自动释放锁。 -
获取锁的时候调用 setnx,如果返回 0,则该锁正在被别人使用,返回 1 则成功获取 锁。 还设置一个获取的超时时间,若超过这个时间则放弃获取锁。 -
释放锁的时候,通过 UUID 判断是不是该锁,若是该锁,则执行 delete 进行锁释放。
分库分表有垂直切分和水平切分两种:
-
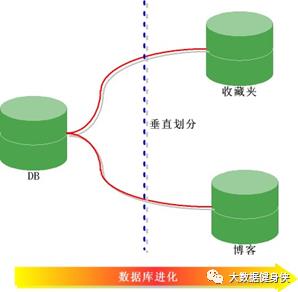
垂直切分(按照功能模块)
将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数 据库 workDB、商品数据库 payDB、用户数据库 userDB、日志数据库 logDB 等,分别用于 存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
-
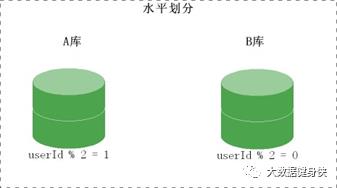
水平切分(按照规则划分存储)
当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如 userID 散列,进行 划分,然后存储到多个结构相同的表,和不同的库上。
分布式事务是指会涉及到操作多个数据库的事务,在分布式系统中,各个节点之间在物理上相互独 立,通过网络进行沟通和协调。
XA 就是 X/Open DTP 定义的交易中间件与数据库之间的接口规范(即接口函数),交易中间件 用它来通知数据库事务的开始、结束以及提交、回滚等。XA 接口函数由数据库厂商提供。
二阶段提交(Two-phaseCommit)是指,在计算机网络以及数据库领域内,为了使基于分布式系统 架构下的所有节点在进行事务提交时保持一致性而设计的一种算法(Algorithm)。通常,二阶段提 交也被称为是一种协议(Protocol))。在分布式系统中,每个节点虽然可以知晓自己的操作时成功 或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事 务的 ACID 特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。因此, 二阶段提交的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者 的反馈情报决定各参与者是否要提交操作还是中止操作。
事务协调者(事务管理器)给每个参与者(资源管理器)发送 Prepare 消息,每个参与者要么直接返回 失败(如权限验证失败),要么在本地执行事务,写本地的 redo 和 undo 日志,但不提交,到达一 种“万事俱备,只欠东风”的状态。
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则, 发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过 程中使用的锁资源。(注意:必须在后阶段释放锁资源)
-
同步阻塞问题
执行过程中,所有参与节点都是事务阻塞型的。
-
单点故障
由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。
-
数据不一致(集群脑裂问题)
在二阶段提交的阶段二中,当协调者向参与者发送 commit 请求之后,发生了局部网络异 常或者在发送 commit 请求过程中协调者发生了故障,导致只有一部分参与者接受到了 commit请求。于是整个分布式系统便出现了数据部一致性的现象(脑裂现象)。
-
两阶段无法解决的问题(数据状态不确定)
协调者再发出 commit 消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那 么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道 事务是否被已经提交。
三阶段提交(Three-phase commit),也叫三阶段提交协议(Three-phase commit protocol),是二阶段提交(2PC)的改进版本。
与两阶段提交不同的是,三阶段提交有两个改动点。
-
引入超时机制。同时在协调者和参与者中都引入超时机制。 -
在第一阶段和第二阶段中插入一个准备阶段。保证了在后提交阶段之前各参与节点的状态是 一致的。也就是说,除了引入超时机制之外,3PC 把 2PC 的准备阶段再次一分为二,这样三阶段 提交就有CanCommit、PreCommit、DoCommit三个阶段。
协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
协调者根据参与者的反应情况来决定是否可以继续进行,有以下两种可能。假如协调者从所有的 参与者获得的反馈都是Yes响应,那么就会执行事务的预执行假如有任何一个参与者向协调者发送 了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
该阶段进行真正的事务提交,主要包含 1.协调者发送提交请求 2.参与者提交事务 3.参与者响应反 馈( 事务提交完之后,向协调者发送Ack响应。)4.协调者确定完成事务。
在电商领域等互联网场景下,传统的事务在数据库性能和处理能力上都暴露出了瓶颈。在分布式 领域基于CAP理论以及BASE理论,有人就提出了 柔性事务 的概念。CAP(一致性、可用性、分 区容忍性)理论大家都理解很多次了,这里不再叙述。说一下 BASE 理论,它是在 CAP 理论的基 础之上的延伸。包括 基本可用(Basically Available)、柔性状态(Soft State)、终一致性 (Eventual Consistency)。
通常所说的柔性事务分为:两阶段型、补偿型、异步确保型、大努力通知型几种。
-
两阶段型
就是分布式事务两阶段提交,对应技术上的XA、JTA/JTS。这是分布式环境下事务处理的 典型模式。
-
补偿型
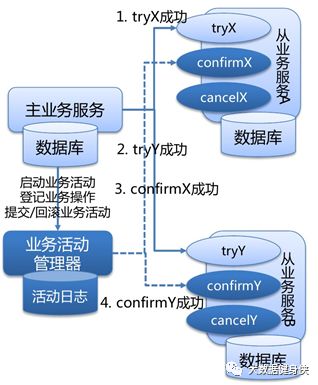
TCC型事务(Try/Confirm/Cancel)可以归为补偿型。
WS-BusinessActivity提供了一种基于补偿的long-running的事务处理模型。服务器A发起事务, 服务器 B 参与事务,服务器 A 的事务如果执行顺利,那么事务 A 就先行提交,如果事务 B 也执行 顺利,则事务 B 也提交,整个事务就算完成。但是如果事务 B 执行失败,事务 B 本身回滚,这时 事务 A 已经被提交,所以需要执行一个补偿操作,将已经提交的事务 A 执行的操作作反操作,恢 复到未执行前事务 A 的状态。这样的 SAGA 事务模型,是牺牲了一定的隔离性和一致性的,但是 提高了long-running事务的可用性。
-
异步确保型
通过将一系列同步的事务操作变为基于消息执行的异步操作, 避免了分布式事务中的同步 阻塞操作的影响。
-
最大努力通知型(多次尝试)
这是分布式事务中要求低的一种, 也可以通过消息中间件实现, 与前面异步确保型操作不 同的一点是, 在消息由 MQ Server 投递到消费者之后, 允许在达到最大重试次数之后正常 结束事务。
CAP 原则又称 CAP 定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability (可用性)、Partition tolerance(分区容错性),三者不可得兼。
-
一致性(C)
在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份 新的数据副本)
-
可用性(A)
在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备 高可用性)
-
分区容忍性(P)
以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性, 就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
本文可能会有所更新,之后还会推出一系列的相关文章,请持续关注大数据健身侠!
以上是关于数据库(纯手写,极度适合巩固基础面试突击)的主要内容,如果未能解决你的问题,请参考以下文章