DSE精选文章|MPP数据库查询内部智能化容错
Posted CCF数据库专委
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DSE精选文章|MPP数据库查询内部智能化容错相关的知识,希望对你有一定的参考价值。
Data Science and Engineering(DSE)是由中国计算机学会(CCF)主办,数据库专业委员会发起创刊,施普林格·自然(Springer Nature)出版集团的开放获取(OA)期刊。本篇精选文章选自DSE最新一期发文。
原标题:Smart Intra-query Fault Tolerance for Massive Parallel Processing Databases
MPP (massive parallel processing)数据库,指大规模并行处理系统,通常搭建在大规模的集群机上,而随着集群规模的扩展,集群出错的概率也会变高。随着查询时间的增加,也会增加查询内部出错的概率。因而查询内部故障是一个非常常见的现象。虽然大部分的 MPP 数据库都提供系统级的容错能力,但很少有系统支持查询内部容错。当查询执行到一半时,若发生单点故障,大部分系统只能让查询终止并重新运行查询。若系统规模较大(单点故障的概率也较大)并且查询执行周期较长时,查询内部容错能力的缺失会给系统的性能稳定带来风险。更坏的情况发生在查询执行过程中反复发生故障时,会面临查询永远无法终止的风险。
本文提出了一个智能化的且较易实现的查询内部容错机制SIFT(smart intra-query fault tolerance)。SIFT通过选择适当的查询执行算子来物化查询的中间结果(即做检查点)的方法,进而实现查询内部容错。当系统发生故障并恢复后,根据最近完成的检查点恢复被中断的查询的状态,即利用被物化的中间结果,继续执行查询。物化算子选择过程中考虑到容错代价、流水线执行和查询成功率三个方面。
在 MPP 数据库(如Greenplum)中,算子通常以流水线的方式执行。图1展示了一个查询以流水线方式执行的过程,其中 Slice 是指一个查询执行进程/线程,算子 Op.1 和 Op.4 在同一条流水线中,两者的执行时间可以有重叠。而 Op.4 和 Op.8 是在同一个进程/线程上的不同流水线的算子,只有前者完成执行之后,后者才能开始执行。
图1 查询流水线方式执行过程,共有6条流水线
图2示例了一种故障发生后的情形,以及利用查询内部容错和不利用查询内部容错两种情况下的查询执行情况。从该图中可以直观的看到查询内部容错的收益。故障发生前,算子 Op.4 和 Op.5 的中间结果被物化。恢复执行时,从 Op.4 和 Op.5 的中间结果恢复执行,并且算子1~5 被跳过,进一步,Slice2 由于没有执行任务无需启动。
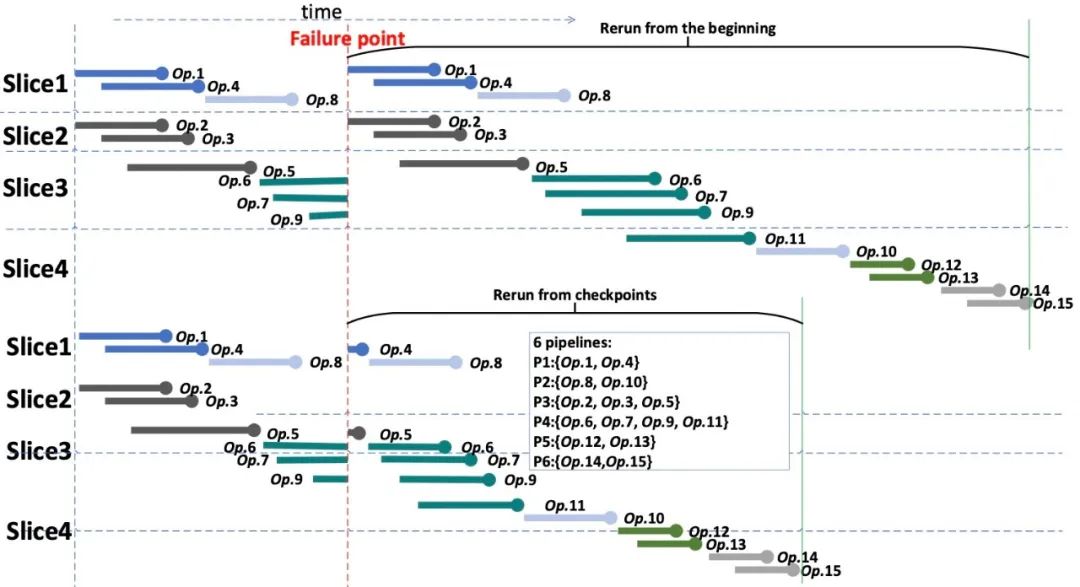
图2 查询执行过程中发生故障后恢复执行
物化算子的选择分为两个阶段:
①选择候选物化算子
物化算子的中间结果可能阻断流水线,为了维持查询执行流水线,在选择候选物化算子时,算子需要满足两个条件:
阻塞性:该算子通常本身就需要中断流水线,因此选择对该算子进行物化时,可以简化实现及减少额外开销;
确定性:即该算子的中间结果仅由数据和查询计划决定,以保证容错的正确性。
②从候选物化算子中选择物化算子
候选物化算子的每个子集构成一个候选物化方案,枚举所有候选物化方案并计算查询成功率,从中选择查询成功率最高的物化方案。
查询成功率是指查询在指定时间内执行成功的概率。查询成功率与指定时间的长度,查询正常执行时所需时间,算子物化带来的开销及物化算子的位置有关。其中,算子物化开销包括算子中间结果在本地物化的代价和在远程备份机中物化的代价。具体来说,指定时间 T 时,查询成功率 可由下式计算得到。
其中 是指查询一次性成功的概率,假设系统故障是相互独立的,则该值可根据指数分布计算可得; 是在查询执行过程中发生一次故障的情况,查询在指定时间内完成的概率,该值可通过蒙特卡洛法计算得到。
作者在开源数据库 Greenplum 中实现了 SIFT,图3 展示了所作的主要修改。实现分两个主要部分,即主节点的更改和从节点的更改。据统计,后者是主要部分。这是由于每种可能成为候选的查询执行算子都需要进行相应的修改。
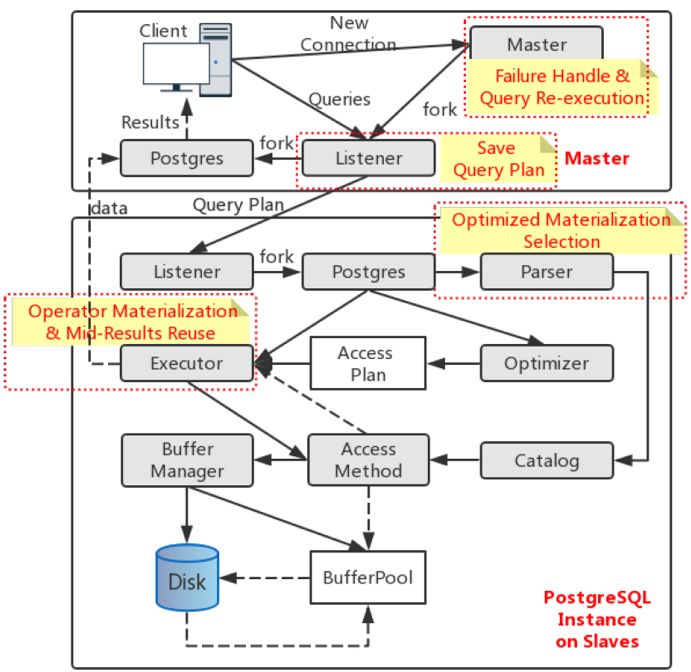
图3 在 Greenplum 上实现 SIFT 的过程中所作的主要修改
作者的实验采用TPC-H 测试基准,在以下两个集群上测试了系统SIFT和三个对比系统。
集群 A,一个主节点,16个从节点,500GB 的数据集;
集群 B,一个主节点,8个从节点,200GB 的数据集;
对比系统 orig,原始 Greenplum(Version 4.3)系统;
对比系统 SIFT,在 Greenplum 之上实现了 SIFT 的系统;
对比系统 materi-all,在Greenplum 中物化所有候选物化算子的系统。
图4和图5展示了相应的实验结果,其中指的是 TPC-H 的第 个查询的第 次测试。两次测试分别在查询执行的不同时间段发生故障。实验结果表明相比原系统和物化所有候选算子的系统,SIFT 可以提高查询成功率并且减少故障发生时的查询执行时间。
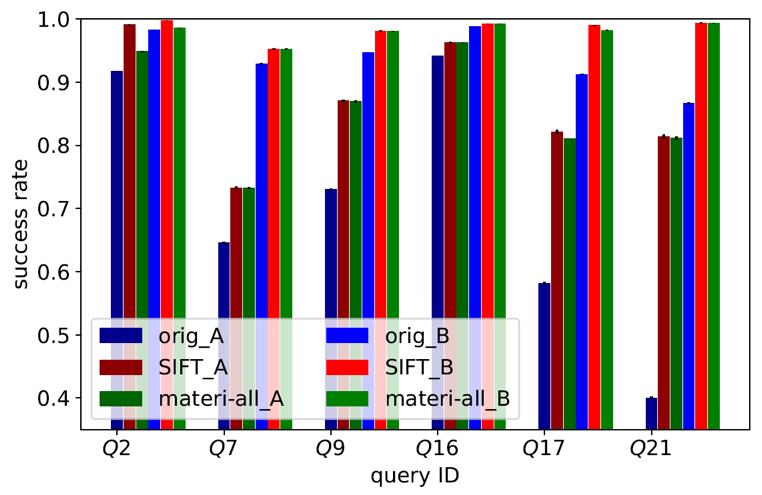
图4 不同系统在不同集群上的查询成功率
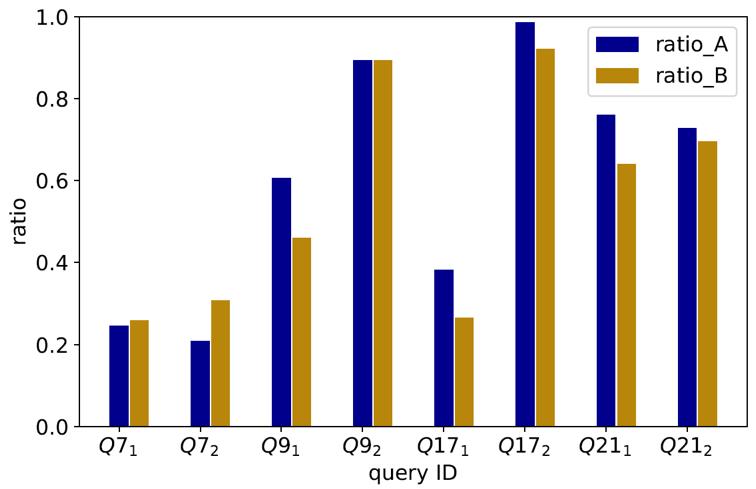
图5 不同集群上,查询执行过程中发生一次故障的情况下 SIFT 节省的时间比例
总的来说,本文提出了一个智能化的且较易实现的查询内部容错机制,并且在开源数据库 Greenplum 中进行了实现,未来的工作会考虑进一步优化它的性能。
作者简介

纪昀红,中国人民大学信息学院博士研究生,主要研究方向为数据库相关系统的开发及性能优化。
柴云鹏,中国人民大学信息学院计算机科学与技术系副教授,计算机系副主任,2009年于清华大学取得博士学位。研究方向包括云计算资源管理、基于新硬件的数据系统优化等。
周烜,华东师范大学数据学院副院长,教授。2005年在新加坡国立大学取得博士学位。研究兴趣包括数据库系统和信息检索技术。
Ji, Y., Chai, Y., Zhou, X. et al. Smart Intra-query Fault Tolerance for Massive Parallel Processing Databases. Data Sci. Eng. (2019).
以上是关于DSE精选文章|MPP数据库查询内部智能化容错的主要内容,如果未能解决你的问题,请参考以下文章
【Flink 精选】阐述 Flink 的容错机制,剖析 Checkpoint 实现流程