云数据库介绍
Posted 智能云计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云数据库介绍相关的知识,希望对你有一定的参考价值。
1. 数据库简介
1.1 数据库类型
1.2 数据库排名
1.3 数据库发展
1.4 数据库架构
2. 数据库管理
2.1 数据库管理系统DBMS
2.2 事务ACID与管理
2.3 数据库安全管理
2.4 数据库备份恢复
2.5 多副本容灾部署
3. 分布式数据库
3.1 部署架构
3.2 分库分表
3.3 分布式事务
4. NoSQL数据库简介
4.1 CAP与BASE理论
4.2 NoSQL数据库简介
4.3 NoSQL数据库框架
1. 数据库简介
1.1 数据库类型
数据库就是通过特定的数据模型进行数据的组织存储、访问处理与管理应用的仓库。如图1,数据模型由数据结构、数据操作与数据约束三部组织,其中数据结构是数据模型的核心,也是决定数据库类型关键。
图1:数据类型组成部分
基于不同的数据模型,数据库主要分为关系型和非关系型。关系型数据库采用二维关系表组织和存储数据,采用统一的SQL查询语言,支持事务处理的ACID特性,数据结构化高,冗余度低;分为传统关系型、分布式关系型,以及整合SQL和NoSQL优势同时支持OLTP与OLAP系统的NewSQL。
数据类型 |
主要特征 |
应用场景 |
主流产品 |
传统关系型 |
结构化二维表、事务处理ACID、通用SQL语言、易维护使用。 |
适合OLTP系统、不适合高扩展、非结构化、海量数据分析。 |
Oracle、DB2、SQL Server,mysql |
分布式关系型 |
采用分库分表与分布式事务机制,适合大规模、超高性能、超高并发、高扩展的场景。 |
OLTP系统、企业核心应用系统。 |
TDSQL、OceanBase、DRDS+RDS |
NewSQL |
整合关系型事务支持ACID与非关系型、扩展性、分布式、海量数据分析等能力 |
OLTP+OLAP系统整合,去O场景。 |
PostgreSQL、TBase |
表1:常用的关系型数据库
1.2 数据库排名
DB-Engines Ranking按月对全球数据库流行度进行综合评估与排名,评估指标主要包括:搜索引擎、社交网络上的查询讨论情况;Google Trends分析的兴趣度;专业网站上的技术文件或讨论频率;相关的工作招聘信息等。表2截取了该排名的Top 30,可以看到关系型数据库应用非常广泛,其中老牌的商用关系型数据库Oracle、SQL Server与DB2排在前列,在企业应用占大量的份额。而开源的MySQL与PostgreSQL排在第2、4位。非关系型数据库中,MongoDB、ES与Redis排进了前十。
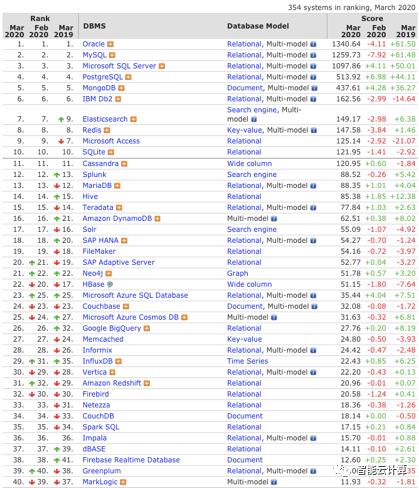
图2:数据库流行度排名(2020.03)
1.3 数据库发展
如表2,数据库发展主要经历了几个阶段,单机关系型(SQL)、分布式关系型(中间件)、分布式非关系型(NoSQL)、分布式关系型(NewSQL),以及云原生数据库。
时间 |
2008 之前 |
2008-2012 |
2012-2016 |
2016-2019 |
2019至今 |
类型 |
单机关系型 |
分布式关系型 |
分布式非关系型 |
分布式关系型 |
云原生数据库 |
模型 |
SQL模型 |
中间件模型 |
NoSQL模型 |
NewSQL模型 |
云原生模型 |
特征 |
应用广泛、结构化数据与事务处理。 |
基于中间件实现分库分表 , 业务与数据库处理逻辑解耦。 |
分布式、易扩展,海量数据分析。灵活的表结构扩展。 |
整合SQL与NoSQL优势,支持事务,强一致等。 |
基于云优化,极致性能、海量存储、成本低。 |
挑战 |
成本高,扩展性弱,海量数据处理能力低。 |
无法处理交易类数据以及复杂的业务逻辑。 |
无法处理复杂业务逻辑,事务能力,存储过程等多种类型语言。 |
各厂商路线多,技术门槛高,各种功能有待完善。 |
应用运行在云上,数据存储在云端。 |
产品 |
Oracle SQL Server |
MyCat DRDS |
HBase MongoDB |
PostgreSQL TBase |
PolarDB CynosDB |
1.4 数据库系统架构
关系型数据库的系统架构比较相似,图3展示了MySQL系统架构,主要分为三大功能模块:客户端的数据库访问接口、服务器端的SQL引擎模块与存储引擎模块。
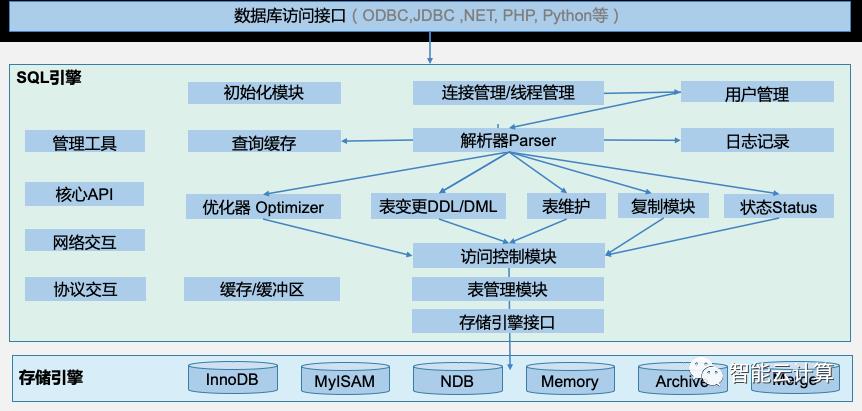
图3:MySQL数据库系统架构
Client端:
1) 数据库访问接口:客户端通过不同语言的数据库访问接口,如ODBC、JDBC来连接数据库,发起SQL操作。
SQL引擎负责连接管理、SQL语句分发与解析、执行计划优化、提供缓存与缓冲区、访问控制等功能。主要组件如下:
2) 初始化:MySQL Server启动时执行各种资源(Cache、Buffer等)、系统变量与存储引擎的初始化设置。
3) 连接管理/线程管理:连接池监听和接收客户端请求,转发到目标模块处理。每个连接都会分配对应的线程,建立两端的通信,接收命令,并返回结果。
4) 用户管理与访问控制:用户管理负责用户连接权限控制和授权管理。访问控制根据用户认证、授权,以及数据库各种约束,控制用户对数据的访问操作。
5) 解析器Parser:对SQL语句进行语义/语法解析,生成SQL_ID,按不同操作类型分发
6) 查询缓存Query Cache:将select请求的返回结果缓存到到内存中,与该查询的Hash值一一对应,基表更改时对应的缓存值失效,用于提升查询性能。
7) 优化器Optimizer:对Client的查询请求与数据库统计信息行分析,得出一个最优的SQL语句执行策略。
8) SQL接口模块:表变更模块负责完成DML和DDL操作,如:update、delete、insert、create table,alter table等。表维护模块负责表的状态检查,错误修复,以及优化和分析等。复制模块分为Master模块和Slave模块,负责MYSQL主从复制。
9) 系统状态管理:在客户端请求系统状态时,如showstatus,show variables,返回各种状态数据返回给用户。
10) 表管理器:维护MySQL表定义文件,缓存表结构信息,管理table级别的锁
11) 日志记录:负责整个系统级别的逻辑层日志记录,包括error log, binary log, show query log等。
12) 核心API:提供需高效处理的底层操作的优化实现,包括底层数据结构、特殊算法、字符串/数字处理,小文件IO,格式化输出与内存管理等。
13) 网络/协议交互:负责底层网络数据的接收与发送,供其他模块调用。协议交互模块实现客户端与MySQL交互过程中的基于OS、TCP/IP的协议。
14) 管理工具:实现系统配置管理、备份恢复、安全设置、迁移同步等。
15) 缓存/缓冲区:提供查询缓存、所有缓存、元数据和统计信息缓存
16) 存储引擎接口:将各种数据库处理高度抽象化,实现底层数据存储引擎插件式管理。
17) 存储引擎模块:负责数据存取操作实现。MySQL默认存储引擎是InnoDB, 同时支持其他多种插件式的存储引擎,如MyISAM、NDB、Memory等。
2. 数据库管理
2.1 数据库管理系统DBMS
如图4,数据库运维管理软件DBMS主要分为三层,语言解析层、数据控制层、存储管理层,提供数据库运行服务引擎,以及各种基于界面或命令行的数据管理功能与工具。其主要功能如下:
图4:数据库管理系统DBMS
1) 数据库定义:通过DDL提供数据库对象创建与修改.如CREATE TABLE/INDEX等;
2) 数据库查询:通过DQL实现数据库查询读取。如 SELECT xx FROM xx WHERE xx。
3) 数据库控制:通过DCL授予或回收访问数据库的某种特权,控制数据库操纵事务发生的时间及效果。如 GRANT、COMMIT、ROLLBACK。
4) 数据库操纵:通过DML对数据库对象更新/修改。如INSERT、UPDATE、DELETE。
5) 数据库组织存储:数据库文件组织、数据分区存储、索引、缓冲区与存储路径管理等。
6) 数据库运维管理:数据库系统监控、日志管理、数据导入导出、访问控制、性能优化。
7) 数据库同步迁移:数据库多副本的同步迁移、备份恢复管理等。
2.2 事务ACID与管理
在关系型数据库中,事务(Transaction )实现特定功能的一组逻辑独立的数据库操作,是DBMS系统任务执行、恢复与并发控制的最小单元。事务支持4个重要特性ACID通过DBMS日志管理、锁机制、并发控制等实现。
1) 原子性(Atomicity):事务中的操作不可分割,要么全部成功执行,要么全部不执行。
2) 一致性(Consistency):并行执行的事务,其结果与按某一顺序串行执行的结果一致。
3) 隔离性(Isolation):事务执行不受其他事务干扰,执行的中间结果对其他事务透明。
4) 持久性(Durability):已提交事务对数据库改变是永久的,即使出现故障也不会丢失。
在数据库中需要对多个事务进行并发执行与控制以提升系统性能与资源利用率。为了保障并发事务ACID,需要通过事务管理器与并发控制器来保障事务隔离级别,实现表3中的可串行化调度,主要采用基于锁并发控制机制。锁机制就是在执行CRUD操时,通过资源锁定禁止其他数据访问共享数据,分为排他锁(Lock-X,禁止操作)、共享锁(Lock-S,可读)。需要根据数据库性能与管理复杂度等因素来评估加锁的粒度(数据库、表、页面、行)。DBMS通常按照两阶段锁协议(增长、缩减)对共享数据进行加锁或解锁。同时,系统中存在较多并发事务,需要采用超时撤销或基于事务锁等待图主动检测的机制,来发现系统出现死锁,并及时撤销死锁上的某些事务及时消除死锁。
隔离级别 |
脏读 |
不可重复读 |
幻像读 |
丢失更新 |
读取未提交 Read uncommitted |
可能 |
可能 |
可能 |
可能 |
读取已提交 Read committed |
不可能 |
可能 |
可能 |
可能 |
可重复读 Repeatable read |
不可能 |
不可能 |
可能 |
可能 |
可串行化 Serializable |
不可能 |
不可能 |
不可能 |
不可能 |
表3:数据库隔离级别
2.3 数据库安全管理
如图5,数据库安全保障涉及用户、堡垒机、DBMS和数据库等多个层次,防止数据的机密性、完整性和可用性受到破坏。可以采用多维度的安全措施,如账号安全、身份认证、权限管理、访问控制、操作审计、数据加密与脱敏,以及备份恢复,多副本容灾部署等。
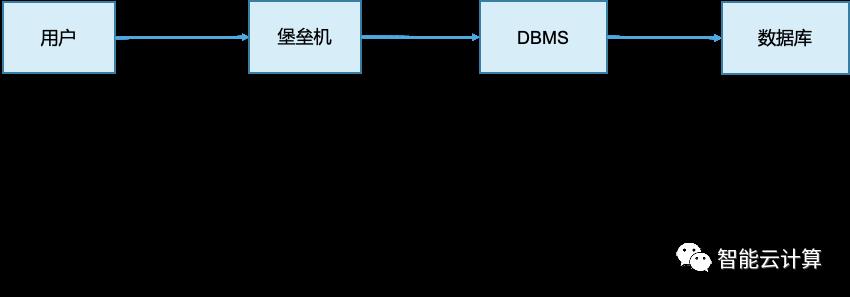
图5:数据库安全机制
2.4 数据库备份恢复
数据库备份恢复、多副本与容灾部署机制是数据库可靠性与可用性的重要保障,如图6,MySQL数据库3种备份方案:1)物理备份,使用Xtrabackup备份数据库的二进制文件,支持全量备份与增量备份;2)逻辑备份,采用Mydumper备份数据库的库表逻辑结构与数据;3)Binlog备份,实时或准实时备份数据库的变更操作日志。在进行数据库恢复时,通常采用最近的物理全量备份,加上binlog备份来实现基于时间点的恢复。如果需要恢复某些具体的数据库或表文件,可以采用基于逻辑备份的实现库表级的逻辑回档。
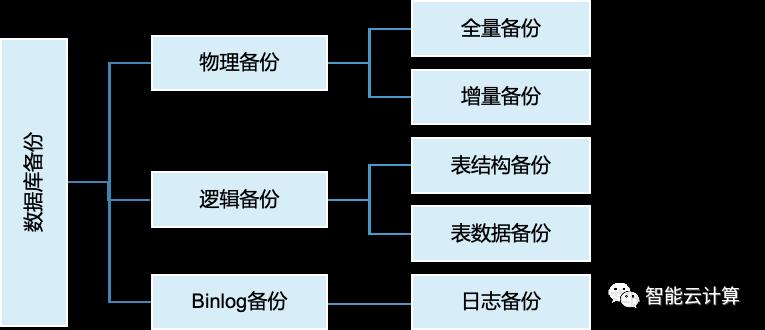
图6:数据库备份方案
2.5 多副本容灾部署
如图7,数据库支持一主多从。基于性能、数据一致性等因素主副本与从副本可采用三种复制方式:1)异步复制,数据写到主副本之后直接返回应用(步骤1、2),应用端不关心数据是否成功同步到从副本(步骤3、4);该方案快速返回性能较好,但主从副本一致性上存在挑战。2)同步复制,数据写入主副本后,需要同步到从副本(步骤1、2),等至少有一个从副本返回成功后,主副本再返回应用(步骤3、4);该方案数据一致性有保障,但性能相比异步复制差一些。半同步复制结合异步和同步复制,正常情况下采用同步复制,当系统响应超时或发生异常时可以退化为异步复制。
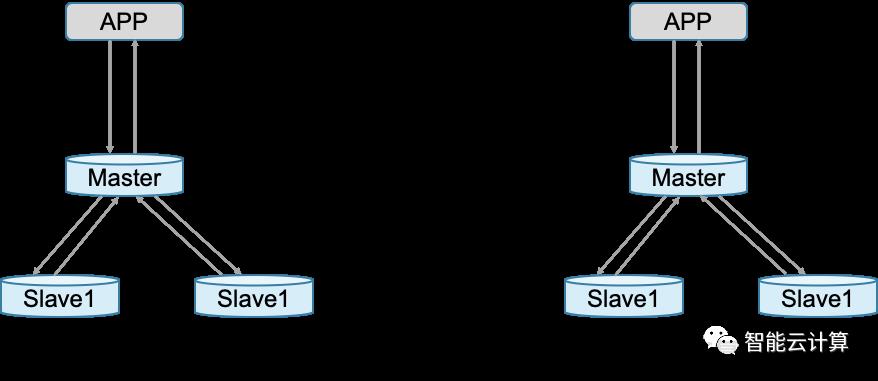
图7:数据库复制方式
为了满足金融等行业核心系统与数据跨IDC或跨地域容灾的需求,数据库支持同城多中心,两地三中心的高可用部署。如图8,同城双中心部署时,数据库支持5个层次(负载均衡、管理调度系统、SQL引擎、核心数据、数据备份)的组件跨IDC部署。数据库多个副本之间的可以基于PAXOS或RAFT协议实现分布式一致性。图中一个实例分为多个副本,部署在不同的IDC,副本之间可以设置为同步或异步复制方式。当主副本故障时,还可以自动发起新的主副本选举,实现业务应用透明的秒级主从切换。如果需要两地三中心部署,可在异地在部署一套数据库集群,考虑时间延迟的影响,可采用异步复制实现跨地域数据同步。
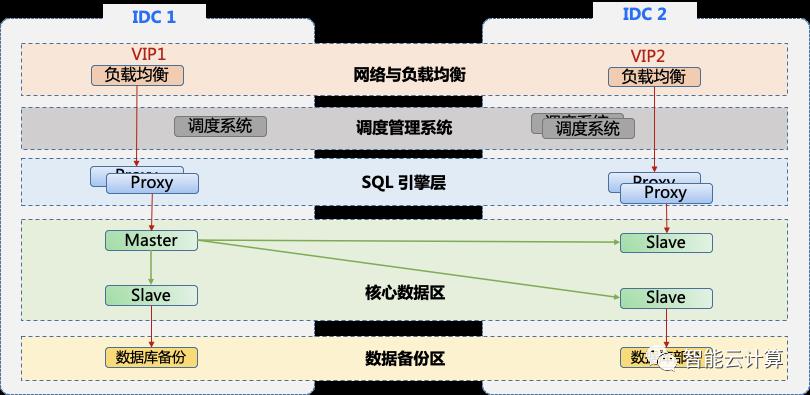
图8:数据库同城双中心部署
3. 分布式数据库
3.1 部署架构
如图9,数据库部署架构分为三个阶段,第一阶段属于单机部署,数据库引擎与存储都在同一台机器。业务负载较高时,对数据库的容量、性能与可靠性面临挑战。第二阶段实现计算与存储分离,数据库节点分开部署,然后共享专用的SAN存储,传统的关系型数据库主要采用这种部署方式,如Oracle RAC等,在大规模高并发的场景,该架构在性能,扩展与成本上也面临一些挑战。第三阶段,分布式架构,通过分库分表,让不同的数据库/表分散到独立的物理节点上处理存储,实现高性能、高并发以及业务透明的弹性扩容。
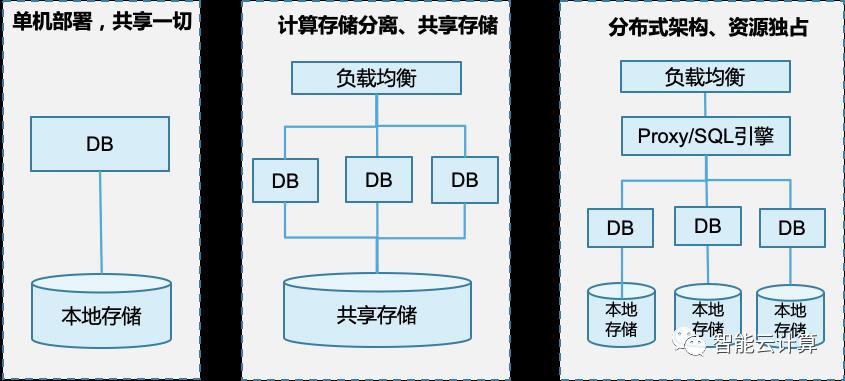
图9:数据库部署架构
3.2 分库分表
如图10,集中式数据库将所有数据放在一个库中部署在单机上,可以采用分库分表机制实现性能与容量的线性扩展。分库就是垂直拆分,基于业务功能将不同的数据存储在不同的数据库,应用需要从不同的库读写对应的数据。分表就是水平拆分,将一个逻辑上完整的数据库/表拆分成不同的分片、分散在不同的物理节点上处理和存储,处理结果再汇总反馈到应用端,水平拆分的过程对应用透明。部分厂商还是支持二级分区功能,将逻辑上完整的一张大表分散在不同的物理节点上处理和存储。
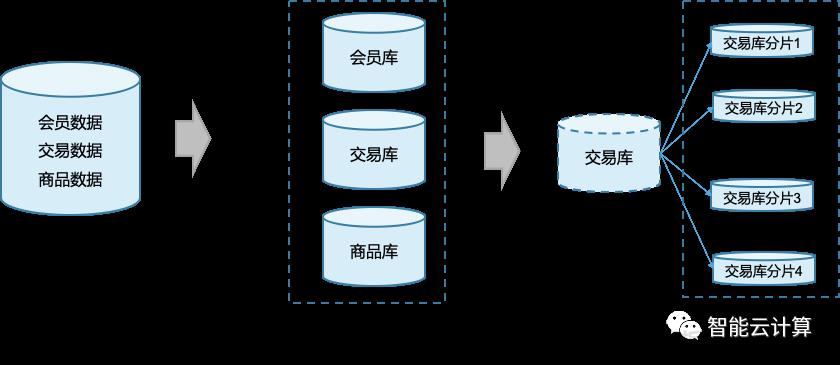
图10:数据库分库分表
3.3 分布式事务
单节点的事务一致性由数据库存储引擎(如InnoDB)保障。多节点的分布式事务一致性涉及网络通信、节点状态与各种场景,处理相对复杂。如图11,业界通用的实现是基于开源的XA事务、2PC两阶段提交协议以及全局事务管理器TM来实现。SQL引擎上的全局事务管理器负责事务状态同步与任务发起。准备阶段:事务启动时GTM向各节点上的RM发起Prepare请求,各节点准备就绪后返回确认到GTM;提交阶段:GTM向各节点发起提交请求,各节点开始提交事务并返回结果;各节点都提交成功则事务执行成功,如果其中某个节点出现异常则可能触发事务重试或回滚。
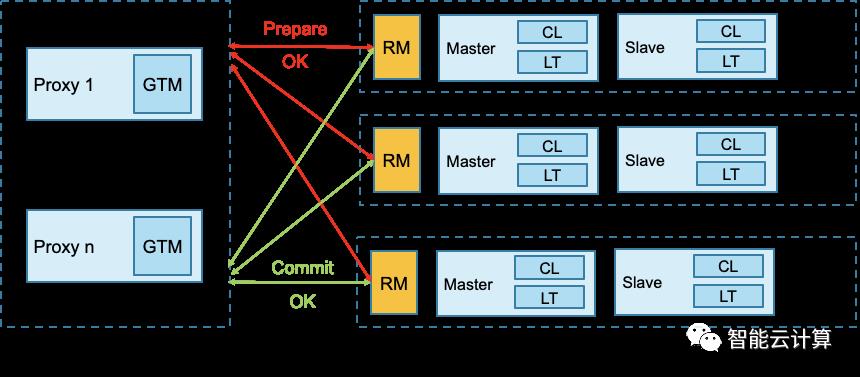
图11:分布式事务一致性
4. NoSQL数据库简介
4.1 CAP与BASE理论
NoSQL数据库主要应用于分布式、高并发、高扩展、非结构化、表结构灵活变更、海量数据分析等关系型数据库不太适合的场景。如图12,与关系型数据库保障事务ACID特性不同,NoSQL通常采用CAP或BASE理论。
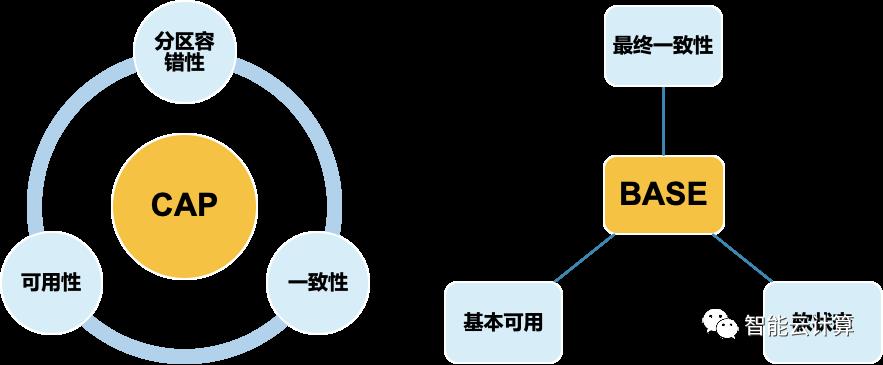
图12:NoSQL数据库CAP与BASE理论
CAP理论指在一个分布式系统中不能同时满足三个核心要求:一致性、可用性和分区容错性,最多只能同时满足其中两项。所以NoSQL数据库主要基于业务需求在一致性和可用性上找到平衡,有时为了保障一致性,在性能和扩展性上有一定妥协;或为了保障高性能,在一致性上有所妥协。
1) 一致性(Consistency):执行某项数据修改后,系统所有节点的数据保持一致。
2) 可用性(Availability):每个请求都能及时地得到合适的处理响应。
3) 分区容错性(Partition tolerance):系统中部分组件或节点异常或系统被隔离为多个孤立的区域后,不影响整体系统的可用性。
按照BASE理论实现的系统不保障强一致性,在处理请求过程中可能处于临时的中间状态,出现短暂的数据不一致;系统会记录这些临时中间状态,当系统故障时可以从这些中间状态继续执行未完成的请求或回退到原始状态达到系统的最终一致性。BASE包括3要素:
1) BA:Basically Available(基本可用):系统能够正常运行,持续提供服务
2)Softstate(软状态/柔性事务):系统不要要求一致保持强一致状态,存在一些临时的中间状态和不一致窗口。
3)Eventuallyconsistent(最终一致性):系统采取机制保障系统能够达到最终一致性。
NoSQL数据库具有一些通用的特征:如Schema-free,不用预先定义数据模式与表结构等;Share-nothing无共享架构;数据分区,弹性扩展;基于日志的异步复制;简单的数据类型;元数据和应用数据分离;BASE理论。
4.2 NoSQL数据库简介
非关系型数据库采用多种数据结构与查询语言,跟进数据存储类型和特点,键值型数据库、文档型数据库、列存储数据库、图数据库与时序数据库等;主要特征是对事务支持较弱,支持CAP或BASE理论,比较适合非结构化数据、高扩展、高并发、大数据分析、数据搜索等场景。
数据类型 |
主要特征 |
应用场景 |
主流产品 |
键值型 |
使用哈希表存储键Key和指向特定的数据Value的指针。索引简单,访问高效。 |
缓存数据库,热点数据高速缓存、读写访问。 |
Redis,Memcached |
文档型 |
版本化的文档,以文档形式(JSON/BSON/XML)存取数据。Schema-Free弱模式结构、可建立索引。 |
应用日志存取、数据结构变化频繁场景(如游戏开发)。 |
MongoDB, CouchDB |
列存储 |
数据表中只定义可灵活变化的列族。键的指针指向多个列、以列族式分区存储结构化或半结构化数据,可压缩。 |
适合OLAP系统、大数据分析场景。 |
HBase, Cassandra |
图结构 |
以图形储存数据、实体顶点,边代表关系,数据以有向加权图方式存取。 |
搜索引擎、社交网络、推荐系统等 |
Neo4J, InfoGrid, Infinite Graph |
时序数据库 |
数据存储处理中带有时间标签,支持海量时序数据的低成本存储、高效处理、聚合分析。 |
业务监控、实时监测、IoT系统 |
InfluxDB、Prometheus |
表4:常用NoSQL数据库
4.3 NoSQL数据库框架
不同类型的NoSQL数据库系统架构各不相同,但逻辑框架如图13所示,主要分为访问接口层、数据模型层、数据分布层和数据持久层。
图13:NoSQL数据库逻辑框架
参考文档:《数据库系统原理、设计与编程》
--------------------
相关阅读:
----------------------------------------------------------------------
智能云计算
微信:AIcloud01
介绍:云计算、人工智能、大数据、物联网、云安全、区块链等前沿技术知识与资讯分享平台。
以上是关于云数据库介绍的主要内容,如果未能解决你的问题,请参考以下文章