Hive基础操作和数据类型
Posted 大数据DL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive基础操作和数据类型相关的知识,希望对你有一定的参考价值。
一、基础操作
二、数据类型
三、数据库相关操作
一、基础操作
指定数据仓库 目录
一般都是在hdfs上有这个目录,hive 安装的时候元数据保存在关系数据库中,一般是 mysql。hive 启动命令:

hive默认,bin / hive启动的是 client模式,bin/hive类似于bin/hive --service cli
后面的选项还有如下图,你也可以启动一个hwi,用web访问,执行sql可视化。
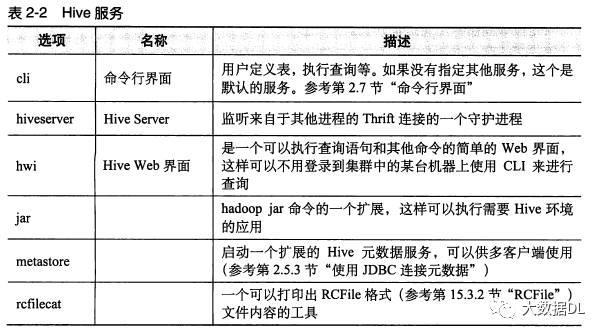
剩下的两个参数说明:添加额外 jar包和指定配置文件

命令行界面,也就是CLI,是和HIVE交互的常用方式,使用CLI,用户可以创建表,检查模式,以及查询表等,CLI选项如下

 各个选项使用说明
各个选项使用说明
-d 可以设置变量,类似于:

可以简化成 -d ,-d是用来自定义变量的,注意的是定义的是hivevar,可以不加 hivevar。例如上面第一个写的但是如果是 env、system 必须要加前缀,如下:

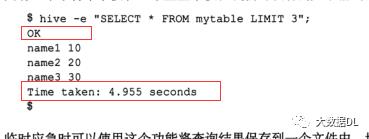
-e 是直接执行 sql 语句。如下:bin/hive -e "sql 语句"

-f 是执行文件里的sql语句,例如:

为了区别 以 .hql结尾,我们可以把 hive sql 执行的结果直接导入到本地文件中
例如:

注意 -S 去掉了额外提示信息
启动 hive shell的时候 , 如果想加载一下额外配置可以在命令里面写 -d 配置=值,但这样比较麻烦,每次都还得写,hive有一个hive shell每次启动的时候都回去加载的目录:$HOME/hiverc,比如 /home/root/hiver

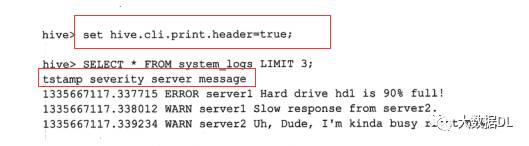
注意 hive.cli.print.current.db=true 是显示数据库的名字 ,还有一个配置是 hive.exec.mode.local.auto=true ,即使在hadoop分布式环境中,配置之后hive根据数据量来判断是用自己的mr本地执行(本地执行快),还是用hadoop分布式环境执行。在hive shell 中可以直接执行 hadoop命令,执行方式是去掉hadoop,例如:

hive 不光可以配置提示数据库,还可以设置显示列,配置如下设置命令和显示的列名
二、数据类型
hive的数据类型 和 java的基本类型保持一致
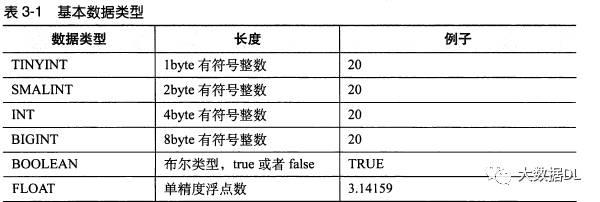
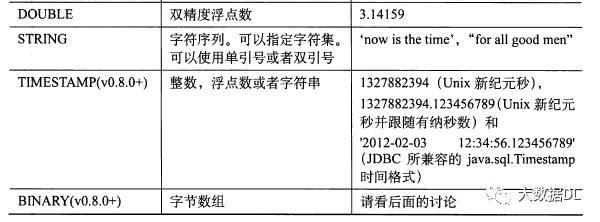
它只有 时间戳类型没有date类型,hive里面的类型强制转换用的是:cast(列 as 类型)。hive 为了提高读取数据 , 把平时我们要分表做的事情,写到一张表里面,为了实现这个目的,它额外多出了集合类型,冗余存储

分别是结构体 、key value 键值对、数组。注意里面都是引号引起来,例如:

当我们设置了集合类型 ,我们的数据格式就一定 限制了,接下来看看数据格式分割符,例如我们平时csv 就是逗号分割,我们来看看hive 默认的分隔符 :
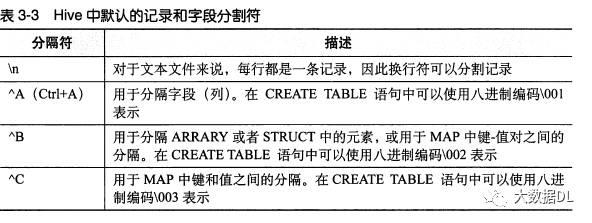
换行符是不能自定义的, 其它都可以自定义:集合元素之间用 ^B、map的key value之间用 ^C、列与列之间用 ^A。这是hive默认的。例如数据:


用户可以不使用默认分隔符 ,根据数据情况自定义分隔符,比如:
你的是csv ,自定义fields


注意两点:


看一下上面例子各个自定义介绍(例子用的是默认分隔符):

csv 是逗号分隔符:

列与列之间用逗号
注: 比如一个表是 3列, 你的数据是5列数据,那么hive会自动舍弃后面两列数据,展现只有3列。
三、数据库相关操作
hive的数据库创建
我们都知道 hive是数据仓库,因为它不能对单条数据进行更改和删除
hive的数据库的创建语句:hive> CREATE DATABASE financials
最好加上IF NOT EXISTS 判断一下,例如
hive> CREATE DATABASE IF NOT EXISTS financials
否则如果库存在则会报错。注意数据库创建完,在数据库所在的目录位于属性hive.metastore.warhouse.dir所指定的顶层目录之后
hive 不管是数据库还是表创建记录是在关系数据库里面,并且还要在hdfs文件系统中生成一个文件夹,表示数据库或者表,你就可以在这下面放你的数据了
如下所述:

你也可以去手动修改存储在hdfs 位置 (建议不要修改)例如:

查数据库的详细信息:
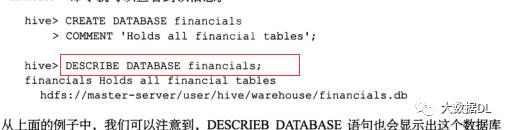
最好 加 formated:得到 更多信息
切换数据库:use {dbname}
删除数据库:

注意后面的 cascade,加上之后即使数据库有表也可以删除 (强制删除)
如果不加,当数据库有表时,删除是不成功的。
以上是关于Hive基础操作和数据类型的主要内容,如果未能解决你的问题,请参考以下文章