HiveQL
Posted 大数据DL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HiveQL相关的知识,希望对你有一定的参考价值。
一:数据定义
二:数据操作
三:数据查询
一:数据定义
表创建,hive 表分为内部表和外部表:内部表删除后数据也随着删除, 外部表删除了数据还在。创建内部表:

 指定到表目录,
指定到表目录,
其中location指定表的创建位置。注意:
我们可以复制已存在的表结构(仅仅是表结构,不包括数据)创建出一张新表

创建一个同样有数据的表:
create table name as select * from name
创建外部表:

注意 :外部表要指定 location,因为外部表都是指向有数据目录,当外部表删除的时候并不影响数据,复制一张外部表:

备注:
 表分区partition ,表分区可以加快查询,创建表表分区
表分区partition ,表分区可以加快查询,创建表表分区
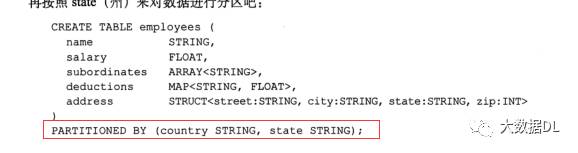
 我们 可以 把 partition当成一个过滤条件。
我们 可以 把 partition当成一个过滤条件。
SELECT * FROM employees默认情况下是非严格模式的,如果有partition你不加where过滤 也可以执行,如果是严格模式 你不加 where 会报错

查看表分区:

查看特定一个分区:

从本地文件目录加载数据到内部表中例如:

去掉 local:从 hdfs上move 数据; local : copy 本地数据到hive表
外部表同样可以创建分区表例如:

分区表 外部表需要先创建好分区 然后在hdfs拷贝数据到目录下:

表删除语句:

注:对于管理表,表的元数据信息和表内的数据都会被删除,对于内部表,表的元数据信息会被删除,但是表中的数据不会被删除。
表的修改:修改就是针对元数据,大多数修改可以通过ALTER TABLE语句
表重命名:ALTER TABLE name RENAME TO new_name
增加分区:

修改分区:

删除分区:
修改表列:

修改列位置:

可以增加列:

删除列:

hive 也可以修改存储属性:

hive 还可以修改一些分割符等。
二:数据操作
表的数据加载 ,动态分区,数据导出
向内部表加载数据 ,因为hive没有行级插入更新和事物,第一种方法只能整个文件copy到 表目录下:

overwrite :覆盖 ;去掉 overwrite :新增。
第二种方法是通过查询语句插入到新表:

加载数据有三种方法: load, select,hdfs命令。注意 hive的hql 语句可以写成 :from name select * ,注意表要加别名,hive 插入到分区表中的时候可以用动态分区:默认情况下动态分区没有开启,需求我们手动配置开启,例如:
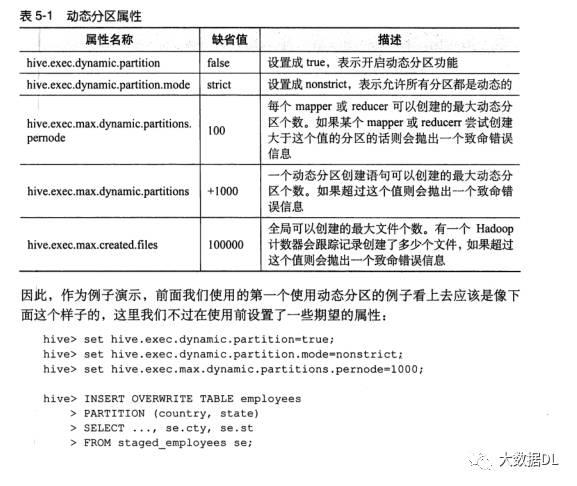
开启动态分区 ,然后按照非严格模式执行 ,非严格模式是可以没有静态分区
注意:如果有静态非区 ,一定在动态分区前面
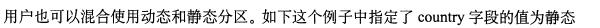

动态分区例子:它是按照后两位来动态分区的。

单个查询语句中创建表并加载数据:

 导出数据:有两种方法。第一种用 hdfs 命令,直接拷贝到本地目录
导出数据:有两种方法。第一种用 hdfs 命令,直接拷贝到本地目录
第二种的就是用sql来导出数据

三:数据查询
select * from name 都用过在hive中from name a select a.*这样写也是对的
查询的时候集合显示与使用:
查询数组

查询Map:

查询 struct:

数组类型使用:

map类型使用:

struct类型使用:

我们可以使用 .* 来匹配列:
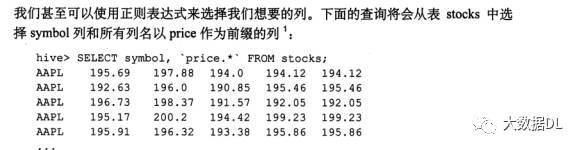
hive 的函数 有内置函数 , 数学函数(窗口函数)聚合函数, 表函数。
对于不同的函数我们可以自定义
总结上面的函数可以分三大类: 内置函数 ,数学函数都是一列一个值,聚合函数都是是多列一个值,表函数是一列多个值比如处理集合列。所以我们可以自定义三种函数类型。
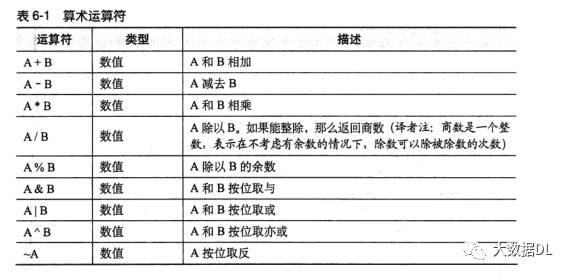
hive的 函数 操作符:
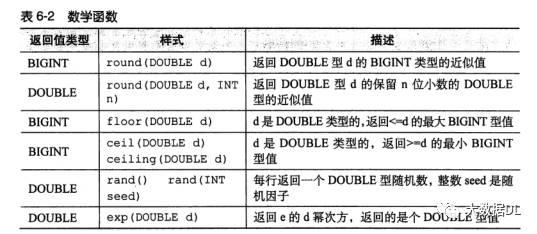
数学函数 : 一个列返回一个值例如 round ()

数学函数表:
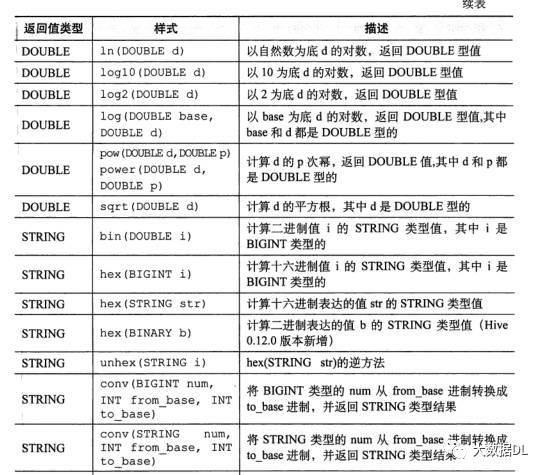
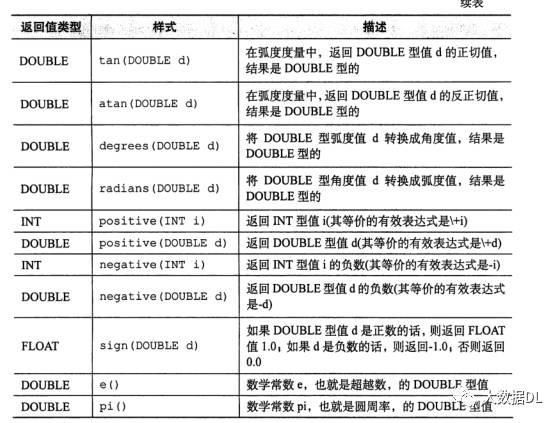
聚合函数:针对的是多列多行求一个值如:

聚合函数的表:
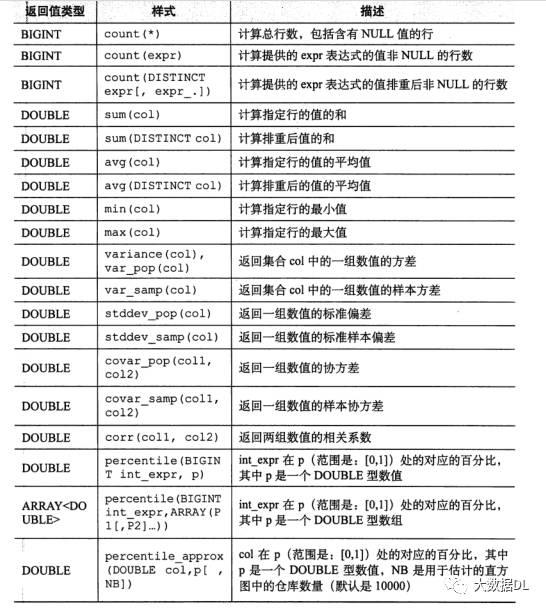
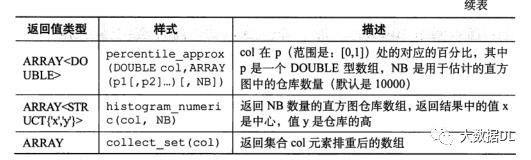
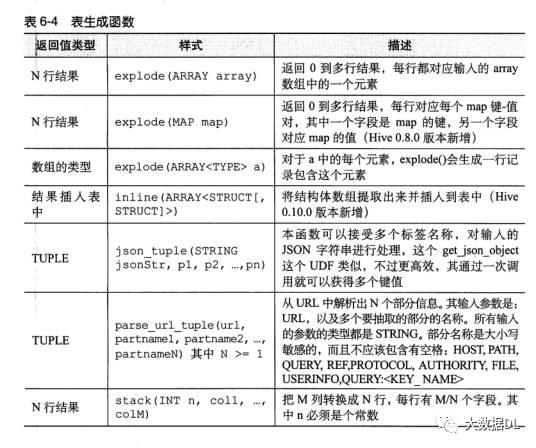
表生成函数:一个集合类型生成多行多列例如


表生成函数的表:
LIMIT:hive可以加 limit语句, 但是只能是返回多少条数据,不能像mysql那样做分页查询

列起别名:as或空格
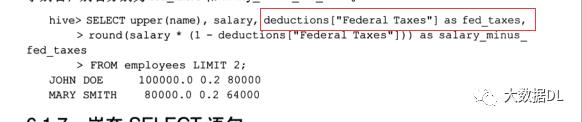
select嵌套 :只能在 from后面嵌套语句

做条件判断: case when the

避免不必要的 mr程序:最好开启本地模式 例如:


select* from name 是不会走 mr程序的,如果是分区表 ,条件是分区条件也不走 mr程序例如:
以上是关于HiveQL的主要内容,如果未能解决你的问题,请参考以下文章