HiveQL:索引
Posted 大数据DL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HiveQL:索引相关的知识,希望对你有一定的参考价值。
一、创建索引
二、使用索引
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键。hive索引比较麻烦 ,而且有些文件格式不支持,所以不常用,但是它确实提高查询速度。Hive的索引目的是提高Hive表指定列的查询速度。没有索引时,类似'WHERE tab1.col1 = 10' 的查询,Hive会加载整张表或分区,然后处理所有的rows,但是如果在字段col1上面存在索引时,那么只会加载和处理文件的一部分。与其他传统数据库一样,增加索引在提升查询速度时,会消耗额外资源去创建索引和需要更多的磁盘空间存储索引。Hive 0.7.0版本中,加入了索引。Hive 0.8.0版本中增加了bitmap索引。
一、创建索引

with deferred rebuild 延迟重建,创建的时候并不赋值,后面通过:

hive 的索引就是根据给定字段 ,放到一个新的索引表里面,保存表名,字段名和文件路径。
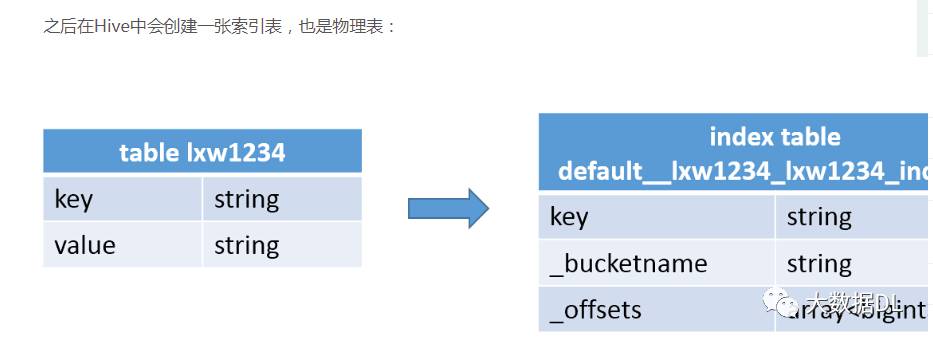
左边是你自己表 ,右边是生成的索引表,索引表中key:原表中key字段的值,
_bucketname:代表数据文件对应的HDFS文件路径,_offsets:代表该key值在文件中的偏移量。可能有多个偏移量。所以字段类型为数组。所以利用索引 可以直接定位到你想要的数据文件,不会去扫描全表。
二、使用索引,首先设置:

然后查询:
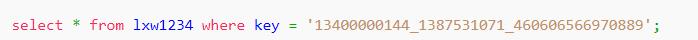
注意:

如果查询索引列
首先扫描索引表找到列名对应值 ,然后找到对应文件路径,直接去加载文件,省去扫描全部表。加快查询数据。
根据值直接查到路径,然后去加载对应文件就可以了,所以索引维护一张索引表,可以手动查看,如果表数据变更,索引表需要手动重建。
以上是关于HiveQL:索引的主要内容,如果未能解决你的问题,请参考以下文章