HiveQL
Posted 大数据DL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HiveQL相关的知识,希望对你有一定的参考价值。
一、where查询
二、JOIN
三、视图
四、桶
一、where查询
例如:
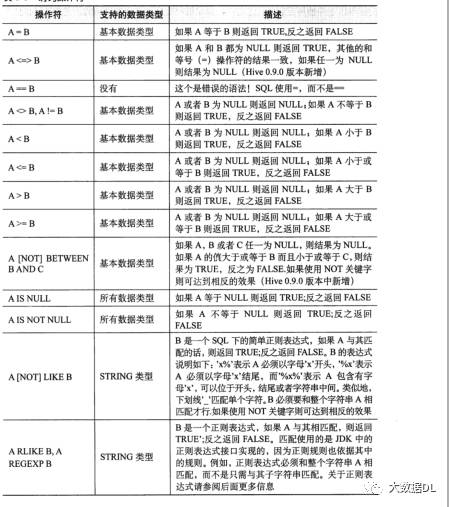
where后面的操作符:
like 和 rlike (hive独有rlike),其中like :模糊查询;rlike :通过java正则表达式指定条件。例如:

关键字RLIKE后面的字符串表达如下含义:字符串中的点号(.)表示和任意的字符匹配,星号(*)表示重复‘左边的字符串零次到无数次,表达式(x|y)’表示和x或者y匹配。
group by :和聚合函数配合使用 ,并且可以用用having 做分组结果过滤。
二、JOIN:分为内连接、外连接、全连接 ,hive中一定要用on做连接过滤,如果用where做匹配连接容易出现笛卡尔积 ,导致执行很慢
内连接

join 优化:hive查询的执行顺序是从左到右 ,一般是把左表缓存到共享缓存中,在 map中做 join加快执行速度, 需要设置:hive.auto.convert.join=true
默认大小:hive.mapjoin.smalltable.filesize=25000000,外连接分为left join和right join,与其他数据库基本一致,全连接是两张表的记录都输出。hive有两个特殊连接:左半开连接 ,map端连接。
左半开连接:输出左表记录 ,在右表已经存在的
例如:平常的SQL

hive 只能用 左半开实现:
 order by : 排序 ,order by 是对全表排序效率 比较慢,也就是最后结果是一个reducer执行, hive 中有sort by :sort by 只会在每个reducer中对数据进行序,执行一个局部排序过程,这样可以保证每个reducer的输出都是有序的,但并非全局有序。如果需求没必要全部排序,可以用sort by局部排序。sort by多个 reduce输出需要设置reduce个数 :
order by : 排序 ,order by 是对全表排序效率 比较慢,也就是最后结果是一个reducer执行, hive 中有sort by :sort by 只会在每个reducer中对数据进行序,执行一个局部排序过程,这样可以保证每个reducer的输出都是有序的,但并非全局有序。如果需求没必要全部排序,可以用sort by局部排序。sort by多个 reduce输出需要设置reduce个数 :

一般用 sort by 加上distribute by,可以保证 全局有序。例如:

如果只对一个列这样排序 可以简写cluster by:cluster by代替了distribute by 和sort by对一个列排序组合。
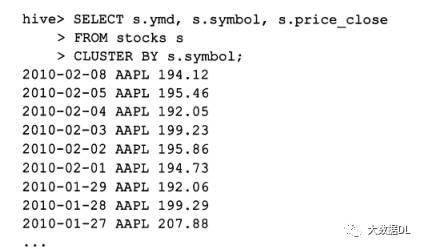
注: distribute by 和 sort by 或者cluster by 会剥夺sort by 的并行性,这样实现输出文件全局有序。
类型转换cast():cast(value as type)
桶随机抽样查询例如(使用不多):

union all 合并,多个表有相同列类型,可以合并成 一张表例如:

三、视图
hive的可以创建视图, 视图只是保存 sql语句并不在hdfs上创建目录,例如:

可以用 if not exists做视图是否存在判断例如:

注意 查询视图的时候先执行视图,视图后面跟的 sql 语句只能是select,当语句为select * from view 时,此时使用视图和使用表一样,删除视图:drop view if exists shipments,查看 视图 :show tables (没有show views语句)。
四、桶
创建分区的时候创建的太多分区目录 ,这对hdfs压力很大,这个时候需要做桶,实际桶比分区查询速度快;
概念:桶表是对数据进行哈希取值,然后放到不同文件中存储。数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。
物理上,每个桶就是表(或分区)目录里的一个文件,一个作业产生的桶(输出文件)和reduce任务个数相同。
作用:桶表专门用于抽样查询,是很专业性的,需要抽样查询时,才创建和使用桶表。
优势: 桶比分区查询效率要高,分桶就是把大表拆成小表过程,然后可以进行 map端执行 ,并且分桶是默认排序的
例子:比如你的分区是2017,2017里面有一年的数据一个 大文件大小为100g
做查询 join 的时候可以做map端join,map端join需要默认是 25M,可以结合这 分区 ,在分区里面做分桶,也就是把那大文件分成一块一块 小文件
创建带桶表:

上图表示创建四个桶,桶是要指定的,首先开启使用桶:

向桶里面插入数据 :
一般情况下分区和桶都是配合使用的,分桶是相对分区进行更细粒度的划分。分桶将整个数据内容安装某列属性值得hash值进行区分,如要安装name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。
注意:第一,分桶之前要执行命令hive.enforce.bucketiong=true;第二,要使用关键字clustered by 指定分区依据的列名,还要指定分为多少桶,这里指定分为3桶。第三,与分区不同的是,分区依据的不是真实数据表文件中的列,而是我们指定的伪列,但是分桶是依据数据表中真实的列而不是伪列。所以在指定分区依据的列的时候要指定列的类型,因为在数据表文件中不存在这个列,相当于新建一个列。而分桶依据的是表中已经存在的列,这个列的数据类型显然是已知的,所以不需要指定列的类型。
如何使用 分桶 查询:
要指定关键字tablesample。用桶来查询数据tablesample(bucket 下标从1开始 out of 到第3个桶 on 你之前指定 分桶字段)。
以上是关于HiveQL的主要内容,如果未能解决你的问题,请参考以下文章