实时分析系统(Hive/Hbase/Impala)浅析
Posted 柠檬大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时分析系统(Hive/Hbase/Impala)浅析相关的知识,希望对你有一定的参考价值。
1. 什么是实时分析(在线查询)系统?
大数据领域里面,实时分析(在线查询)系统是最常见的一种场景,通常用于客户投诉处理,实时数据分析,在线查询等等过。因为是查询应用,通常有以下特点:
a. 时延低(秒级别)。
b. 查询条件复杂(多个维度,维度不固定),有简单(带有ID)。
c. 查询范围大(通常查询表记录在几十亿级别)。
d. 返回结果数小(几十条甚至几千条)。
e. 并发数要求高(几百上千同时并发)。
f. 支持SQL(这个业界基本上达成共识了,原因是很难找到一个又会数据分析,还能写JAVA代码的分析工程师)。
传统上,常常使用数据仓库来承担这一任务,数据仓库通过创建索引来应对多维度复杂查询。传统数据仓库也存在很明显的缺点,扩展性不强,索引创建成本高,索引易失效等等。 当查询条件复杂时,传统领域和hadoop目前都没有一个特别好的解决方案。维度如果不固定,就无法创建索引或者索引代价太高,通常只能通过全盘暴力SCAN的方法来解决。
目前来完美解决实时分析的系统还在探索中,下面来讲讲hadoop领域几种常见的解决方案
2. Hive
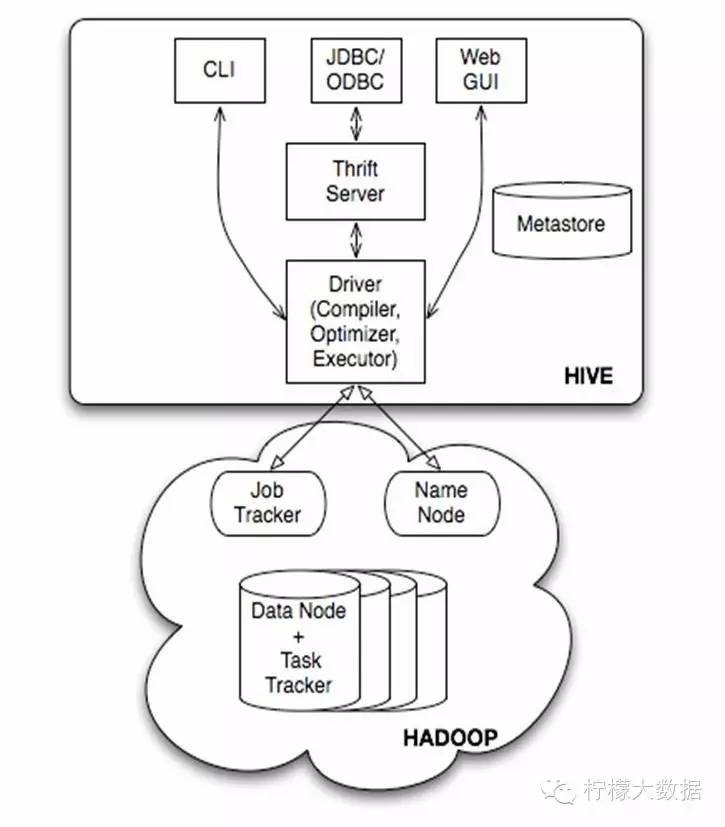
一句话描述Hive: hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。Hive支持HSQL,是一种类SQL。
也真是由于这种机制导致Hive最大的缺点是慢。Map/reduce调度本身只适合批量,长周期任务,类似查询这种要求短平快的业务,代价太高。
Map/reduce为什么只适合批量任务,这里不解释,建议大家看下相关原理,业界对这快的分析比较多,由此也诞生了spark等一系列解决方案。
3. Hbase
HBase是一个分布式的、面向列的开源数据库,该技术来源于Chang et al所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
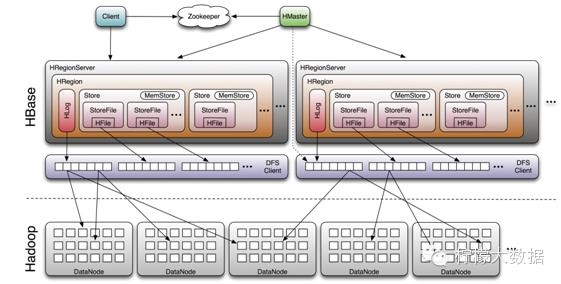
Hbase核心是将数据抽象成表,表中只有rowkey和column family。Rowkey是记录的主键,通过key /value很容易找到。Colum family中存储实际的数据。仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
正是由于Hbase这种结构,应对查询中带了主键(use id)的应用非常有效果,查询结果返回速度非常快。对没有带主键,通过多个维度来查询时,就非常困难。业界为了解决这个问题,在上面实现了一些技术方案,效果也基本差强人意:
a. 华为的二级索引,核心思路仿照数据库建索引方式对需要查询的列建索引,带来的问题时影响加载速度,数据膨胀率大,二级索引不能建太多,最多1~2个。
b. Hbase自身的协处理器,碰到不带rowkey的查询,由协处理器,通过线程并行扫描。
c. Hbase上的Phoniex,Phoniex 可以让开发者在 HBase数据集上使用SQL查询。Phoenix查询引擎会将SQL查询转换为一个或多个HBase scan,并编排执行以生成标准的JDBC结果集,对于简单查询来说,性能甚至胜过 Hive。
4. Impala
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。其架构如图 1所示,Impala主要由Impalad, State Store和CLI组成。
Impalad: 与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的Impalad为Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
Impala State Store: 跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后(Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据)因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
CLI: 提供给用户查询使用的命令行工具(Impala Shell使用python实现),同时Impala还提供了Hue,JDBC, ODBC使用接口。
Impala架构类似分布式数据库Greenplum数据库,一个大的查询通过分析为一一个子查询,分布到底层的执行,最后再合并结果,说白了就是通过多线程并发来暴力SCAN来实现高速。
架构是完美的,现实是骨感的,实际使用过程中,Impala性能和稳定性还差得远。尤其是Impala虽然号称支持HDFS和HBASE,但实际使用中发现,运行在HDFS上,性能还差强人意,运行在HBASE上性能很差,另外还经常有内存溢出之类的问题尚待解决。
5. 结语
目前来看,业界还没有一个完美的解决方案,通常的思路有:
a. 提前根据查询结果来组织数据。每种业务都是不同的,要想查询得快,就要提前分析场景,在数据入库时,就提前根据查询结果来组织数据。这也是微博等应用的做法,根据显示结果提前存储数据。
b. 对不固定维度的,多维度查询,目前来看hadoop和传统的并行数据库架构上会有一个融合的过程,相信最后会殊途同归,Impala还是有前途的。
c. 多查询引擎的融合,通常我们希望一份数据,可以承担多种应用,既可以承担直接带用户id的快速查询,也系统可以搞定多维度的复杂分析,所以要支持多种应用,多查询引擎的特点融合不可以避免。希望后面impala可以解决在habase上性能不高的问题。
d. 用高速硬件加速,flash卡目前越来越便宜,将需要高速查询的数据换成到flash等高速硬件上。
以上是关于实时分析系统(Hive/Hbase/Impala)浅析的主要内容,如果未能解决你的问题,请参考以下文章
CDH5上安装Hive,HBase,Impala,Spark等服务