Hive的“有缘人”
Posted 畅游DT时代
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive的“有缘人”相关的知识,希望对你有一定的参考价值。
文章来源:中国联通网研院——IT技术研究团队
简介
本文以Hadoop数据仓库工具——Hive,为出发点,以全新的视角介绍了Hive的发展历程,以及沿途所涉及的各类相关技术。从而,让读者对Hive有更加全面的了解。
Hive是基于Hadoop的一个数据仓库工具,可以查询、管理海量的结构化数据。其提供了一系列的工具,可以用来进行ETL(extract/transform/load,提取、转化、加载);可以从HDFS或者其他数据存储系统(例如HBase)中,直接访问文件;提供类SQL查询功能,SQL语句基于MapReduce提供查询分析功能,此种类SQL语言被称为Hive QL。从而,使得没有编程背景的分析人员,能够通过Hive使用类SQL语言执行分析任务,而不用写复杂的MapReduce代码。但是,Hive需要将SQL翻译成MapReduce,以MR任务进行执行。而MapReduce有较高的延迟,并且在作业提交和调度的时候需要有大量的开销成本。因此,Hive不能满足对于实时性有要求的快速查询场景。
Tez是一款基于YARN的新型计算框架。其直接源自于MapReduce框架,将Map和Reduce这两个操作做进一步的拆分。Map被拆分成Input、Processor、Sort、Merge和Output。Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等。这些分解后的元操作可以被任意灵活组合,构建出DAG(Directed Acyclic Graph,有向无环图)任务。Tez具有以下特性:
任务基于DAG进行,并尽可能地优化调整DAG的执行流程,确保优化后传输最少的数据量,并减少任务数量,大大降低调度成本;
任务之间的数据传输不需要再通过HDFS进行写入、读出,从而大大减少了因为HDFS读写所造成的时间开销;
更加高效地利用Hadoop集群上的资源;
能够根据不同的应用程序需求建立特定的模型;
各个节点输出的中间结果数据,会根据数据量的大小来动态决定放在本地磁盘、分布式文件系统还是内存中(MR的中间结果只能存在磁盘)。
基于以上特性,Tez解决了MapReduce架构在迭代计算与交互式分析方面的不足。另外,Tez是基于YARN的,因此可以与原有的MapReduce进行共存,之前的MR任务可以无缝移植到Tez上。Tez并不直接面向最终用户,其目的是让开发人员基于它构建供最终用户使用的应用程序。
Spark是一个开源的分布式计算框架,其主要特点是提供了一个集群的分布式内存抽象,这个抽象被称为RDD(Resilient Distributed Dataset,弹性分布式数据集)。RDDs可以来自于Hadoop上的数据输入,例如HDFS文件,或者来自于其他RDDs。RDD具有两类操作,转换(transformation)与行动(action)。transformation,根据原有的RDD创建一个新的RDD,包括map、flatMap、filter、union、join、groupByKey、ReduceByKey等;action,对RDD操作并将结果返回,包括collect、reduce、count、save等。通过对RDDs进行处理与分析可以完成MapReduce所能完成的所有工作。在Spark中,所有RDD的transformation都是惰性求值的,即Spark不会即刻计算结果,直到遇到action才会开始计算。RDD的transformation会生成新的RDD,新的RDD数据依赖于原来RDD的数据。这样,一段程序实际上是一个由多个RDD组成的DAG,并以一个action操作作为结束。遇到action操作后,才将这个DAG作为一个Job提交给Spark进行执行并返回结果。由于Spark对DAG的Job执行进行了优化,并且将常用数据保存在内存中,这样极大地提高了分析性能,从而能够满足迭代式算法与交互式挖掘的应用需求。
Tez与Spark的对比
Tez与Spark具有很多相似点,具体如下:
有分布式内存处理能力;
都可以基于YARN执行;
任务基于DAG进行分解优化;
上层都支持Hive、Pig等应用;
可以使用MR的输入输出格式来读写Hadoop上的数据。
那么Tez与Spark之间到底有何区别?
首先,最大的区别是Tez更偏向于底层,用于构建应用程序的底层执行框架,例如Hive和Pig。而Spark更面向于最终用户,为普通开发者提供易用的API接口,直接对数据进行处理分析,或者调用机器学习算法进行数据挖掘。
Tez的目的是为像Hive和Pig,这种传统的Hadoop数据处理语言,提供比MR更快的数据处理引擎。Spark除了以上的目的之外,还提供了清晰、丰富的面向用户的API接口,除了支持原生Scala语言之外,还支持Java、Python、R。Spark可以通过3行Scala或者15行Java代码实现wordcount功能。而Tez提供的API接口更加偏重底层,用于控制一个任务执行过程中的各类细节。其需要超过300行代码才能够实现wordcount功能。因此,Spark的使用门槛就比较低,有利于提升开发效率。
从社区活跃度及接受度方面来讲,Spark是要远远好于Tez的。Spark拥有上百家企业的贡献者,例如:Databricks、Cloudera、MapR、Intel等。而对于Tez的贡献者基本来自于一家企业,Hortonworks。
Hive on Tez
Hive使用MapReduce作为其执行引擎,由于MapReduce的自身缺陷导致了Hive执行查询效率低。基于此,Hortonworks提出将Tez作为另一个计算引擎以提高Hive的性能,并在Hive 0.13版本(于2014年4月21号发布)中支持。从而,Hive的性能有了飞跃的进步,执行效率相比之前的MR架构要提升100倍。Tez的出现大大提升了Hive的执行效率,从而使得Hive on Tez能够满足对实时性要求高的交互式查询需求。
Hive on Spark
Hive社区于2014年推出了Hive on Spark项目(HIVE-7292),将Spark作为继MapReduce和Tez之后Hive的第三个计算引擎。Hive原本是没有很好支持MapReduce之外的引擎的,而Hive On Tez项目让Hive得以支持和Spark近似的Planning结构(非MapReduce的DAG)。所以在此基础上,Cloudera主导启动了Hive On Spark。这个项目并得到了IBM,Intel和MapR的支持。受到了来自Hive和Spark两个社区的共同关注。2015年5月,随着Hive 1.1版本的发布,Hive on Spark已经成为Hive代码的一部分了。
有了Tez支撑Hive,那为什么还需要用Spark做Hive的后端执行引擎。这个问题有以下几个方面的考虑:
使得Spark用户受益,对于已经使用Spark用于数据处理与机器学习的用户来说此特性非常有意义。因为一个标准化的后端执行引擎方便用户进行操作管理;
进一步增强Hive的接受度,为Spark用户带来基于Hadoop的SQL,能够进一步提升Hive的流行度,增强Hive社区活力。同样,也扩展了Spark的应用场景,进一步提升了Spark的适用范围;
提升Hive执行性能,像Tez一样提升Hive用户的使用体验。
使用Spark作为Hive的后台引擎并不是为了替换Tez或者MapReduce。多个后台引擎的共存对于Hive项目来说是健康的。用户可以自由选择Tez、Spark或者MapReduce作为其Hive任务的执行引擎。每种后台引擎都具有其自身的特性,用户需要根据其具体的应用场景进行选择。而且,Hive的成功与否不单一依赖于Tez或者Spark的成功,这样就增强了Hive项目的抗风险能力。
至此,Tez与Spark也与MapReduce一起作为Hive选项配置单元下的执行引擎,其中MapReduce是默认选项。Hive的运行架构如上图所示。由于有了以上三个引擎的支持,使得Hive的应用场景更加多样与灵活。以下,介绍与Hive On Spark相似的Spark SQL项目,并且分析了两者的相似性与区别。
Spark SQL
Spark SQL的前身是Shark。Shark为了解决由于Hive将SQL翻译成MapReduce,从而任务执行效率低的问题。其实现了在Spark引擎上执行SQL的功能,使SQL查询的性能得到了很大的提升。但是,随着Spark的发展,Shark对于Hive有着太多的依赖(如:采用Hive的语法解析器、查询优化器,等等),制约了Spark各个组件的相互集成,违背了Spark的One Stack to Rule Them All的既定方针,在此背景下终止了Shark项目,并开始了Spark SQL项目,如下图所示。
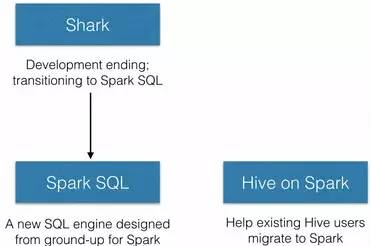
Spark SQL为Spark带来了通用、高效、多元一体的结构化数据处理能力。
就易用性而言,对比传统的MapReduce API,Spark的RDD API有了数量级的飞跃。然而,对于没有MapReduce和函数式编程经验的新手来说,RDD API仍然存在着一定的门槛。另一方面,数据科学家们所熟悉的R、Pandas等传统数据框架虽然提供了直观的API,却局限于单机处理,无法胜任大数据场景。为了解决这一矛盾,Spark SQL在原有Schema RDD的基础上提供了与R和Pandas风格类似的DataFrame API。新的DataFrame API不仅可以大幅度降低普通开发者的学习门槛,同时还支持Scala、Java与Python三种语言。更重要的是,由于脱胎自Schema RDD,DataFrame天然适用于分布式大数据场景。查询时既可以使用SQL也可以使用DataFrame API(RDD),以及混合使用两者,需要用户根据使用场景进行选择。
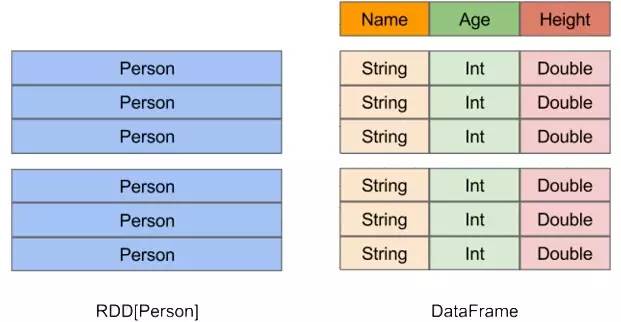
如上图所示,在Spark中,DataFrame是一种以RDD为基础的分布式结构化数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。
Hive on Spark与Spark SQL
Spark SQL和Hive On Spark都是在Spark引擎上实现SQL的解决方案。Hive On Spark比Spark SQL稍晚。
Spark SQL是Spark的一个特性,其使用Hive解析器作为前端,从而为Hive QL提供支持。Spark程序开发者可以轻松的将数据处理逻辑用SQL与其他Spark操作进行实现,从而将SQL查询与Spark程序进行无缝的融合。因此,Spark SQL相对于Hive on Spark来说,能够多支持一种不同的使用案例。
与Spark SQL相比,Hive on Spark的目的更加的单一,与Hive on Tez的目的类似,其就是为了支撑所有Hive特性,包括Hive QL,和Hive与授权、监控、统计和其他操作工具的集成,并使用新的引擎,让Hive冲向云霄。
结束语
本文介绍了与Hive相关的各类技术,以及它们之间的关联关系。我们看到各类技术为Hive带来的进步与提升,也有Hive对其反过来产生的影响。这其中既有技术因素,也有非技术层面的驱动。后续,将对基于各类技术的Hive技术进行实际的对比测试,以便在执行效率、运行稳定性等方面提供给用户更加直观的信息。我们希望百家争鸣,各类社区健康均衡发展,而不是一家独大。这样,才会给用户以丰富的选择,让用户根据其具体的应用场景选择适用的工具,最大化提升用户使用体验。而这才是开源技术发展的根本目标与意义。
-END-

声明:
本文为中国联通网研院IT技术研究团队独家提供。
如需转载或合作,请联系管理员(zhouyh@dimpt.com)
长按既可添加关注
以上是关于Hive的“有缘人”的主要内容,如果未能解决你的问题,请参考以下文章