Apache Hive vs Apache Impala Query Performance
Posted whoami
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Hive vs Apache Impala Query Performance相关的知识,希望对你有一定的参考价值。
Apache Hive 2.0 是100%开源软件,而社区也在不断驱动Apache Hive 2.0的革新,LLAP更是真实地将快速分析提升到一个新的水平。它使得客户在不需要追加基于SQL的分析工具就可以执行次秒级的交互式查询,能够快速迭代分析,还提供了非常重要的价值转换。
今天尝试HIVE LLAP
1, 阅读关于具有LLAP功能的Hive 如何带来次秒级查询你的大数据湖,请转到此处:
2, 如果你想要在单个节点上进行快速测试,在. 下载和,几分钟之内就可以安装并运行。
请注意:这种方法,你需要一个RAM至少16GB的系统。
上星期,我们讨论了ApacheHive转换到内存中心的架构,展示了新的架构如何提供显著的性能改良,尤其是交互式SQL 工作负载。今天我们将对比同样的硬件和数据规模在Hadoop 引擎的其他SQL上和在ApacheImpala(孵化中)上的结果。
对比Apache Hive LLAP和Apache Impala (孵化)
,测试环境概述表明查询设置和数据是符合规则的。Impala and Hive的数字是在同样的10个节点的d2.8xlarge EC2 VMs上产生的。为了准备Impala环境,节点是采用Cloudera Manager的Cloudera CDH 5.8版本备份系统后重新安装的。Cloudera Manager 以默认值进行安装/配置Impala 2.6.0. 值得指出的是在这次测试中Impala 的运行时间过滤功能可以使用在所有查询中。
数据:Hive最适合在ORCFile中工作, Impala最适合在Parquet文件中工作, 因此Impala测试的所有数据是以Parquet格式完成, 压缩成最精简的压缩文件。数据都是”沿date_sk列“同样的分区方式分布到两个系统中的。这样分区是为了有利于Impala的运行时间过滤和Hive的动态分区Pruning。
查询:相关设置和数据加载完成之后,我们尝试运行同样的查询, (完全查询链接到下面的查询区)Impala被设计成高度兼容Hive,但由于完美的SQL对等是不可能的,有5个查询因为语法错误无法在Impala中运行。例如, 一个查询编译失败因为缺少 Impala的汇总支持。有可能它已经找到了Impala-specific 对这些问题的解决办法,但是因为这些结果无法直接比较所以也无从尝试。在这里,我们只画出了用完全相同的语法在两个引擎上运行查询的比较图。
时间设定: 对于两个系统, 所有的计时测量时从查询提交到客户端最后一行的接收为止
这个条形图展示了两个引擎运行时间的比较。
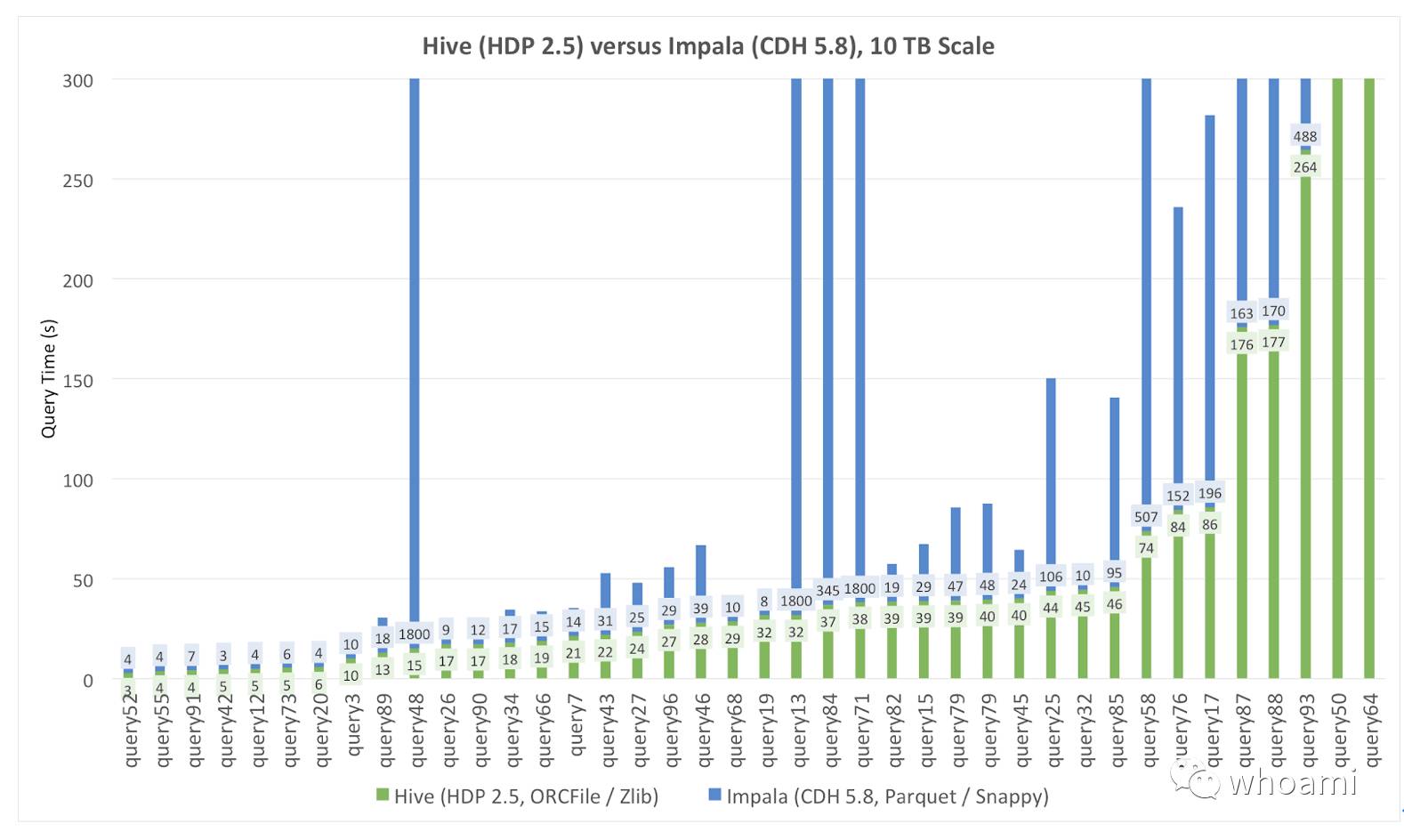
有一点, 一些 Impala 查询超时(30分钟)很快就突显了出来,其中还包括在Hive中低于1分钟的查询。这就使得直接比较有点挑战性。
比较引擎更有效的方式是检测在指定时间内有多少个查询完成。下面图表中显示了在给定的时间内完成查询的累计次数。图标中的X轴有30秒的离散时间间隔。
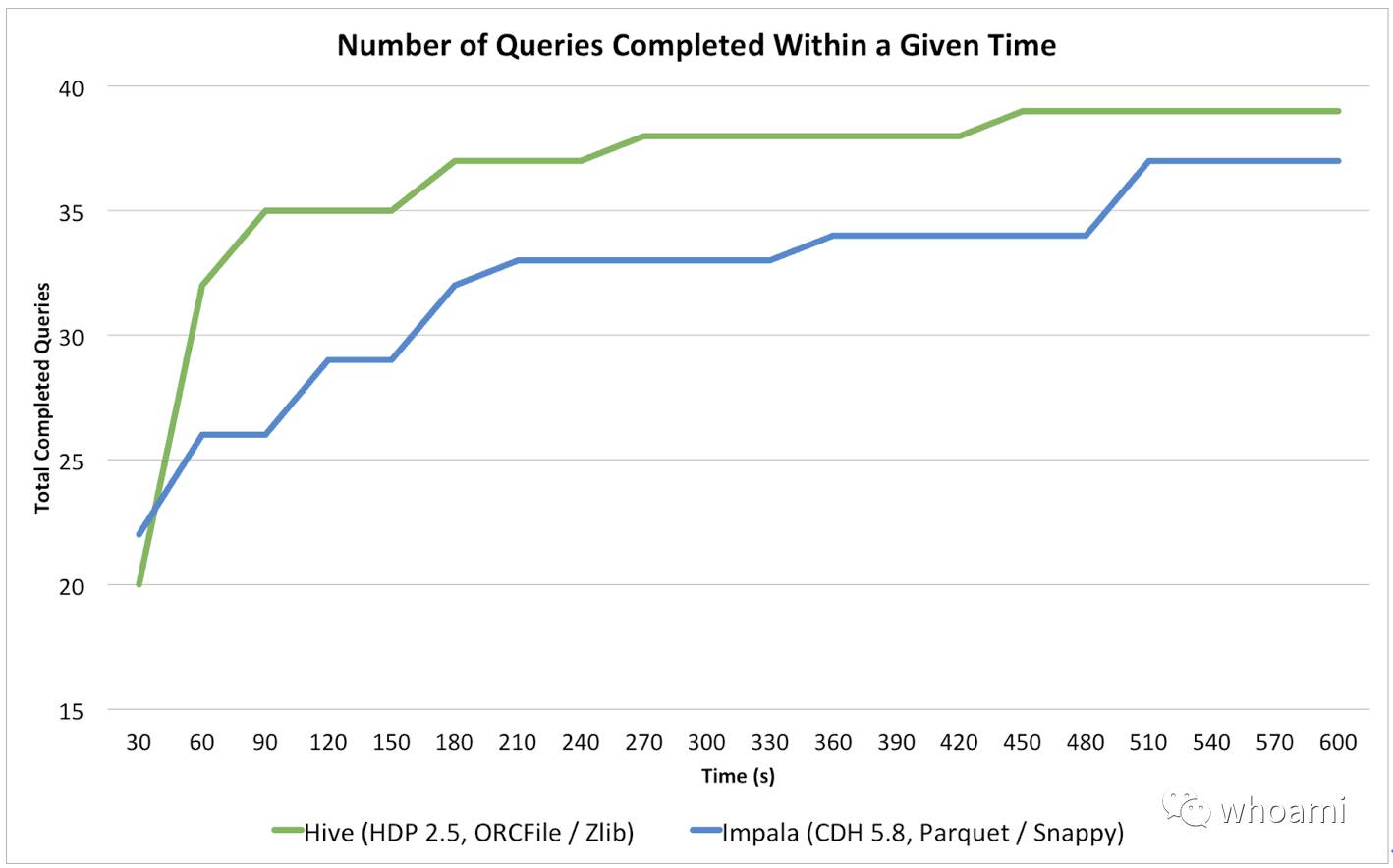
首先我们关注到的是Impala在30秒之内的查询优势。在Impala中30秒内完成22个查询对比Hive只完成了20个。而随着查询时间边长位置开始变化:当时间达到一分钟时, Hive已经完成了32个查询时Impala是26个而相对位置并没有再次切换。这就表明Impala在简单的查询中表现良好但是随着查询的复杂性增加查询就开始变得困难了。
从部分运行时间上很难判断, 一张完整的运行时间表包括时间结束的时候。
总结:
随着更多的Hadoop工作负载移动到交互式和面向用户,工作组面临只有一个SQL引擎可用于交互式的不和谐的前景而Hive可以用于任何地方。这就增加了Hadoop的成本和复杂性,因为它意味着需要专门分离小组去调整,排除故障,运行两个不同的SQL系统。
Hive LLAP通过引入符合Hive交互性能专门定制仅用于交互式的SQL引擎从根本上改变了这种格局。使用Hive LLAP你可以在同一个引擎解决SQL的速度和规模问题,极大地简化了Hadoop分析架构。
测试环境:
软件和数据:
其他设置:
所有的HDP软件都是利用Apache Ambari用HDP2.5 部署完成的。所有的安装都用默认值。
利用Cloudera Manager部署所有的CDH
硬件:
10x d2.8xlarge EC2节点都用于Hive和Impala 测试。使用独立,全新安装,并且数据生成在本地环境。
OS 配置:
大部分情况下,OS默认设置有1个例外:
/proc/sys/net/core/somaxconn= 4000
数据:
TPC-DS 10000M(10TB)数据规模通过date_sk 列分区。
Hive数据用Zlib压缩存储为ORC格式。
Impala数据使用snappy压缩存储为Parquet格式。
查询:
从Hive测试平台上查询https://github.com/hortonworks/hive-testbench/tree/hive14 ,同样的查询文本文件都用于Hive 和Impala, 查询只有在两种环境都包括在内时工作。
参考:Hive 和Impala运行时间表
https://hortonworks.com/blog/apache-hive-vs-apache-impala-query-performance-comparison/
试用Hive LLAP:
在云或者你的电脑上试用Hive LLAP 都很简单。
1,想要在云上快速启动? (在技术预览版)绝对能满足你的需求,以及便捷的会指引你每一步操作。
2,如果你想在单个节点上快速测试, 在Hortonworks Sandbox 2.5.下载和,几分钟之内就可以安装并运行。请注意:这种方法,你需要一个RAM至少16GB的系统。
3,Hive LLAP还包含在的预置型安装,单击几下就可以启用。
测试驱动很简单, 因此我们支持你从今天开始并且在和我们分享你的经验。
译文原文:https://hortonworks.com/blog/apache-hive-vs-apache-impala-query-performance-comparison/
原创文章,转载请注明: 转载自的博客
本博客的文章集合:
以上是关于Apache Hive vs Apache Impala Query Performance的主要内容,如果未能解决你的问题,请参考以下文章
SparkSQL 错误:org.apache.hadoop.hive.ql.metadata.HiveException:无法实例化 org.apache.hadoop.hive.ql.metadat
apache atlas - hook hive - 如何构建 apache-atlas-$project.version-hive-hook.gz?
执行错误,从 org.apache.hadoop.hive.ql.exec.DDLTask 返回代码 1。无法验证 serde:org.apache.hadoop.hive.serde2.avro.A