一文带你了解 Apache Hive2.x 的四大特性
Posted 中兴大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文带你了解 Apache Hive2.x 的四大特性相关的知识,希望对你有一定的参考价值。
文 | 黄榕华
Apache Hive2.x版本推出了多个闪亮的大特性,这些都值得Hive开发者为之振奋。
Apache Hive是建立在Hadoop上的开源数据仓库框架,它提供类SQL语言HQL,以便读取、写入和管理Hadoop中的海量数据集。
Apache Hive从第一个release版本到Hive1.2.1的一系列功能都已被很多开发者熟知,国内不少厂商也使用到Hive1.1或1.2版本的特性。但是在2016年之后逐渐发布的Apache Hive2.x版本中,社区推出了多个闪亮的大特性,这些都值得Hive开发者为之振奋。本文将为大家介绍Apache Hive2.x版本的四个重大特性。
我们先总体来看一下这四个特性是什么:
LLAP
支持使用HPL/SQL的存储过程语言
更智能的成本优化器CBO
全面详尽的监控和诊断工具
下面我们再将这些特性展开介绍。
通过LLAP达到亚秒级查询,极大提升性能
Hive2.1推出的LLAP是下一代分布式计算架构,它能够智能地将数据缓存到多台机器内存中,并允许所有客户端共享这些缓存的数据,同时保留了弹性伸缩能力。通过LLAP(Live Long and Process),Hive2.1进行了极大的性能优化。在Hive2.x开启LLAP与Apache Hive1.x进行对比测试,其性能提升约25倍。
同样基于Hive on Tez的TPC-DS查询,做“Hive1.x+Tez”和“Hive2.1+Tez+LLAP”的性能对比测试,结果是后者性能提升到前者的25倍了。
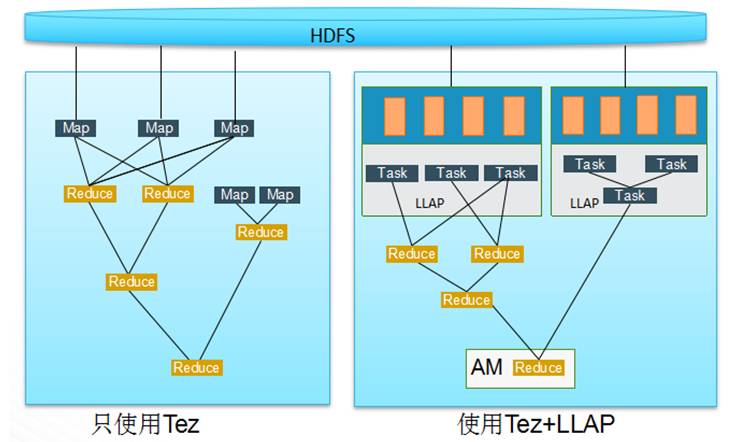
LLAP提供了一个高级的执行模式,它启用一个长时存活的守护程序去和HDFS DataNode的直接交互,也是一个紧密集成的DAG框架。这个守护程序中加入了缓存、预抓取、查询过程和访问控制等功能。短小的查询由守护程序执行,大的重的操作由YARN的Container执行。下面是Hive+Tez与Hive + Tez + LLAP的任务运行原理图,其中Task可以是group by、shuffle join 等Hive Task 。
支持使用HPL/SQL的存储过程
Hive2.0.0推出的Hive Hybrid Procedural SQL On Hadoop (HPL/SQL) 是一个在Hive上执行过程SQL的工具,它可以表达复杂的业务规则。
HPL/SQL具备以下特点:
支持使用变量、表达式、控制流声明、迭代来实现业务逻辑,支持使用异常处理程序和条件处理器来实现高级错误处理。
使SQL-on-Hadoop更加动态,即:支持使用高级表达式、各种内置函数,基于用户配置、先前查询的结果、来自文件或非Hadoop数据源的数据,即时动态地生成SQL条件。
利用已有的存储过程SQL技能:大量的数据库开发者和数据分析师都熟悉传统数据库的存储过程语言,HPL/SQL有利于这部分技能的充分利用。相较于Python、Java或者Linux脚本,HPL/SQL让更多的BI分析师和开发者都能使用上Hadoop。
让传统ETL开发更高效,因为它提供函数和声明。
为BI/SQL开发者提供更高可读性和可维护性。
方便集成和支持多种类型的数据仓库,即:可以实现单个脚本来处理包括Hadoop、RDBMS、NoSQL等多个系统的数据,开发者只需要考虑各个系统负载。
广泛的兼容性和可移植性。
总的来说,Hive支持HPL/SQL是广大BI/SQL开发者的一大福音,通过Hive我们使用存储过程访问Hadoop数据了。
更智能的成本优化器CBO
Hive2.0开始持续不断地优化成本优化器CBO,尤其是在BI业务关注的TPC-DS查询上。
提供全面详尽的监控和诊断工具
可以通过新的Hive Server2 Web UI,LLAP Web UI和Tez Web UI查看Hive相关的HQL查询以及关联的作业状态和日志。丰富了Hive用户的运维和排错的手段。
当然,Hive2.x除了以上新特性外,还有其他的优化特性在持续不断的更新,例如Hive-on-Spark优化、事务ACID优化等等。
以上是关于一文带你了解 Apache Hive2.x 的四大特性的主要内容,如果未能解决你的问题,请参考以下文章