Hive优化
Posted 大数据DL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive优化相关的知识,希望对你有一定的参考价值。
Hive优化
1.explain关键字:hive优化实际上是hadoop的 map reduce 优化,首先我们需要知道一条sql语句执行了哪几个步骤,hive和传统关系数据库一样也有个执行计划,用explain关键字可以看到完整的执行步骤。
2. 本地模式:当输入数据小于250M时候默认不调用 mapreduce,直接在本地机器执行计算hive.exec.mode.local.auto=true。
3.并行执行:执行一条sql的时候分成步骤,有的时候不是关联的,这种情况下可以并行执行。开启: hive.exec.parallel=true这个默认是关闭的。
4.严格模式:hive 默认情况下是不严格模式的。严格模式是对sql执行有要求 。
4.1、对于表分区查询的时候必须 where 表分区字段,必须指定表分区限制
4.2、order by必须加limit限制
4.3、join的时候必须用 on 关联不能用 where关联,用 where会进行笛卡尔积
5. 调整 map 和renduce 个数。
6.jvm 重用: 在hadoop2中是uber模式。
7.推测执行: hadoop说过,最好关掉。默认是开启的。
8. join优化 :如果有小表我们开启join优化,可以进行map端 join。
hive.auto.convert.join=ture,小表放左边。
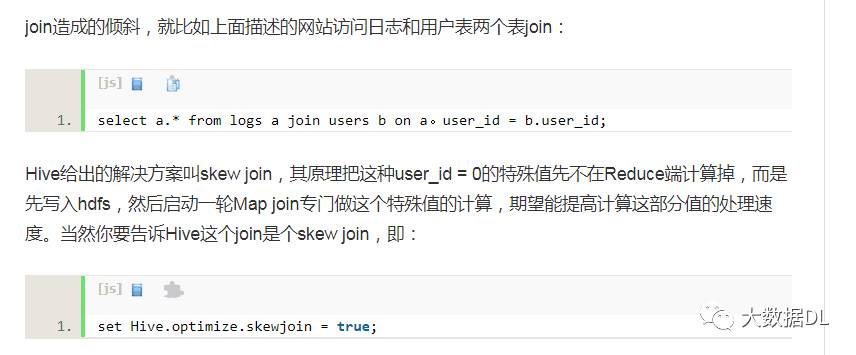
hive 的数据倾斜 :
Hive压缩
查看现有压缩包有几种

这里显示了四种:gzip,bzip,默认,snappy,最好的压缩格式是snappy,空间时间比较均衡,hive的压缩和hadoop是一样的,有中间压缩和输出压缩
压缩优点:减少空间.
缺点:不能分割和消耗cpu。如果想分割根据大小文件 来压缩。
hive 的中间压缩的设置:可以在hive中设置也可以在 hadoop中设置 ,如果 hadoop设置了 hive中就不需设置了,我们来看在hive中开启中间压缩 hive-site.xml

开启以后如果不选择压缩格式就是默认压缩,一般情况下我们都要选择压缩格式,如果 hadoop里面配置了, 就不需要再配置了。配置如下:hive-site.xml

这些配置也可以在执行sql的时候配置:配置 hive环境变量用 set
例如 :

指定压缩格式和开启中间压缩,上面说的是中间压缩。
输出结果压缩
hive 和 hadoop一样都可以对输出结果进行压缩,如果 hadoop设置了 hive就不用设置了,如果没有,可以用 hive进行设置,在 hive-site.xml 中添加:


这是在配置文件中添加 ,我们也可以在执行语句的时候添加:
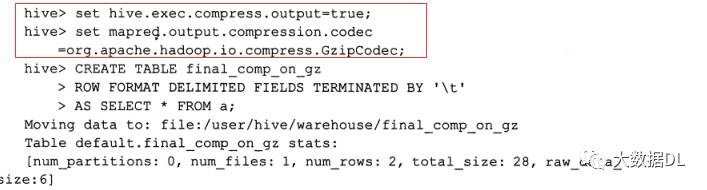
直接在执行的用set 对这两个变量进行赋值,这种方法只对这个对话有效,配置文件对整个hive有效,如果设置hadoop中所有使用hadoop引擎的都有效。
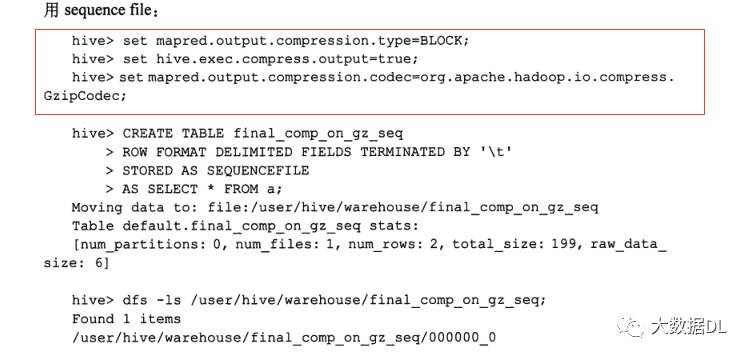
hadoop内置的一种为了压缩可分割的文件格式是:sequence文件
用sequence文件 我们可以指定压缩方法比如按照行来压缩,按照block 来压缩
hadoop中可以设置的,hive中的配置文件设置是 :

按照block压缩也就是128压缩一次,这个同样可以用set 执行语句的时候设置
现在有一种比较好的文件格式 parquet, hadoop本身不支持,需要额外jar包
以上是关于Hive优化的主要内容,如果未能解决你的问题,请参考以下文章