关于Hive数据仓库的那些事儿Hive架构
Posted TheFortyTwo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于Hive数据仓库的那些事儿Hive架构相关的知识,希望对你有一定的参考价值。
Hive架构在Hadoop生态圈中已经是老生常谈。尽管如此,很多资料并没有将Hive模块之间的关系描述的十分清楚,本人也在管理Hive数据仓库时绕了不少弯路。所以我们仍要再谈Hive架构,希望将积累的经验总结出一套完整而又易懂的Hive架构,借此为行业新人开路,为大数据运维排忧。
Hive是典型C/S模式。Client端有JDBC/ODBC Client和Thrift Client两类。Server 端则分为如下几个部分:
CLI
Thrift Server
Metastore
WUI
Driver
Hive Structure
其他资料要么把Hive架构分为Clients/Services两个部分,要么全部称之为组件。为了更好地理解Hive,我重新调整一下组织结构,如上图所示。Hive的模块分为:
Clients:远程访问Hive的应用客户端;
Services:需要独立部署的Hive服务;
Components:独立功能的Hive组件。
下面且听我细细分解。
Clients
Thrift Client
Thrift客户端采用Hive Thrift Server提供的接口来访问Hive。官网已经公开了Thrift服务的RPC,有兴趣的同学可以了解一下。
如果不想重新编写Thrift客户端,Hive也提供了封装好Thrift RPC的Python Client和Ruby Client。
Thrift Client的优点在于,程序员不再依赖Hive环境来访问Hive数据仓库。
JDBC Client
Hive官方已经实现了JDBC Driver(hive-jdbc-*.jar)。如果你希望通过Java访问Hive,请参照官网JDBC Client Sample Code。
Hive 0.14以后,Hive将自带的Beeline重构成一个命令行界面的JDBC Client。之前,Beeline类似于Hive CLI的运行模式。
Beeline解决了CLI无法避免的并发访问冲突。
ODBC Client
目前Hive暂没有提供ODBC Driver支持。
Services
CLI(命令行界面)
CLI是和Hive交互的最简单/最常用方式,你只需要在一个具备完整Hive环境下的Shell终端中键入hive即可启动服务。
我们之所以将CLI归为Services,是因为它可以直接调用Driver来工作。不妨把CLI看成一个命令行界面的单机版Hive服务,用户可以在CLI上输入HQL来执行创建表、更改属性以及查询等操作。不过Hive CLI不适应于高并发的生产环境,仅仅是Hive管理员的好工具。
优点:简单快捷,易于上手。
Hive Thrift Server
Hive Thrift Server是基于Thrift 软件框架开发的,它提供Hive的RPC通信接口。目前的HiveServer2(HS2)较之前一版HiveServer,增加了多客户端并发支持和认证功能,极大地提升了Hive的工作效率和安全系数。
在运维HS2的时候,我们还需要注意以下一些细节:
HS2启动加载hive-site.xml文件配置时,只会加载HS2相关参数。也就是说,你在hive-site.xml里面设置的Hive任务参数并不会对Clients生效;
Hive Clients的用户权限取决于启动HS2进程的用户;
利用hive.reloadable.aux.jars.path参数可以不用重启HS2而热加载第三方jar包(UDF或SerDe)。
WUI (Web User Interface)
WUI并不属于Apache Hive,它是Hive生态圈的一项服务,目前熟知的有Karmasphere、Hue、Qubole等项目。WUI是B/S模式的服务进程,Server一端与Hive Thrfit Server交互,Brower一端供用户进行Web访问。
目前绝大多数的数据分析公司都采用了Cloudera公司的开源项目Hue作为Hive WUI。后续文章也会着重提及Hue的运维,本文不做详细解说。有关Hue的内容大家可以详见Hue官网。
Components
Driver
Driver在很多Hive架构描述里都划分到Services中,这给我初入Hive带来了一些困扰。我认为Driver并不是服务,而是在输入HQL后才会被调用的一项组件,在这里将其归纳到Components部分。每一个Hive服务都需要调用Driver来完成HQL语句的翻译和执行。通俗地说,Driver就是HQL编译器,它解析和优化HQL语句,将其转换成一个Hive Job(可以是MapReduce,也可以是Spark等其他任务)并提交给Hadoop集群。
Metastore
Metastore是Hive元数据的存储地。在功能上Metastore分为两个部分:服务和存储,也就是架构图中提到的Metastore及其Database。
官方提供了服务和存储部署的三种模式,我们一一介绍之。
内嵌模式
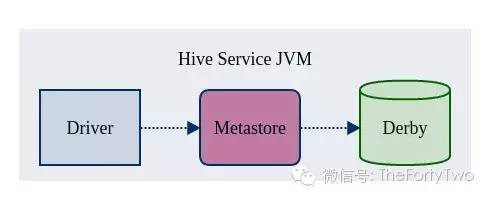
Embedded Metastore
内嵌模式是Hive Metastore的最简单的部署方式,使用Hive内嵌的Derby数据库来存储元数据。但是Derby只能接受一个Hive会话的访问,试图启动第二个Hive会话就会导致Metastore连接失败。
Hive官方并不把内嵌模式当做默认的Metastore模式。我们把官方解释翻译成了大白话,“内嵌模式自个儿玩玩就行,投入生产概不负责”。需要尝试内嵌模式的同学,可以手动修改hive-site.xml中的embedded.metastore.configruation参数并重启相应的Hive服务。
本地模式
Local Metastore
本地模式是Metastore的默认模式(懒人专用模式)。该模式下,单Hive会话(一个Hive 服务JVM)以组件方式调用Metastore和Driver。
我们可以采用mysql作为Metastore的数据库。下面列出部署细节:
在hive-site.xml中设置MySQL的Connection URL、用户名和密码以及ConnectionDriverName;
将MySQL的JDBC驱动Jar文件放到Hive的lib目录下。
远程模式
Remote Metastore
远程模式将Metastore分离出来,成为一个独立的Hive服务(Metastore服务还可以部署多个)。这样的模式可以将数据库层完全置于防火墙后,客户就不再需要用户名和密码登录数据库,避免了认证信息的泄漏。
远程模式的配置如下:
| 属性 | 默认值 | 描述 |
|---|---|---|
| hive.metastore.local | true | false为远程模式 |
| hive.metastore.uris | 未设定 | 远端模式下Metastore的URI列表 |
| hive.jdo.option.connectionURL | jdbc:derby | metastore数据库的JDBC URL |
| hive.jdo.option.ConnectionDriverName | org.apache.derby.jdbc.EmbeddedDriver | JDBC驱动类 |
| hive.jdo.option.connectionUserName | 未设定 | JDBC用户名 |
| hive.jdo.option.connectionPassword | 未设定 | JDBC密码 |
Hive架构的简略介绍在这里也结束了。请大家期待下一篇:(四)揭秘Metastore。
扩展阅读
《Programming Hive》
《Hadoop权威指南》
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
https://cwiki.apache.org/confluence/display/Hive/Setting+Up+HiveServer2
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
http://www.cloudera.com/content/www/en-us/documentation/archive/cdh/4-x/4-2-0/CDH4-Installation-Guide/cdh4ig_topic_18_4.html
以上是关于关于Hive数据仓库的那些事儿Hive架构的主要内容,如果未能解决你的问题,请参考以下文章