hive---实践
Posted BingGooo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive---实践相关的知识,希望对你有一定的参考价值。
hive中的partition
partition是Hive提供的一种机制:用户通过指定一个或多个partition,key,决定数据存放方式,进而优化数据的查询,一个表可以指定多个,partition key,每个partition在hive中以文件夹的形式存在。
通过PARTITIONED BY (dt STRING)指定分区的列,通过desc 命令可以看到表的信息。

将本地文件a.txt加载进创建好的分区表中,并且通过partition(dt=0),指定将dt列值为0的记录分配到该分区下,进入/user/hive/warehouse目录下,可以看到所创建的分区表

通过对hive表做partition操作,可以在查询的时候,通过where条件的限制,快速的定位到相应的分区表上,从而加快了数据查询的数据。
hive中的bucket
在前面hive的理论知识中,我们了解到,我们可以根据指定的bucket数目,按照表中的某个字段做hash,将一个大表分成多个小表,这样在查询的时候就能够根据该字段快速定位到对应小表,排除不需要的字段,不需要去扫描全表,从而提升查询效率。除此之外,对hive中的表进行bucket操作后,还能方便我们从较大规模的数据中进行数据抽样操作。下面我们看看具体的操作是怎样的。
首先我们需要创建一张指定bucket分区操作结构的表:
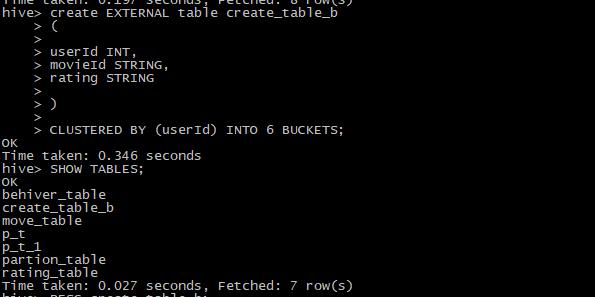
我们创建了一张表名叫create_table_b的表,并且通过CLUSTERED BY (userId) INTO 6 BUCKETS指定按userId进行bucket分区,bucket数量为6个。
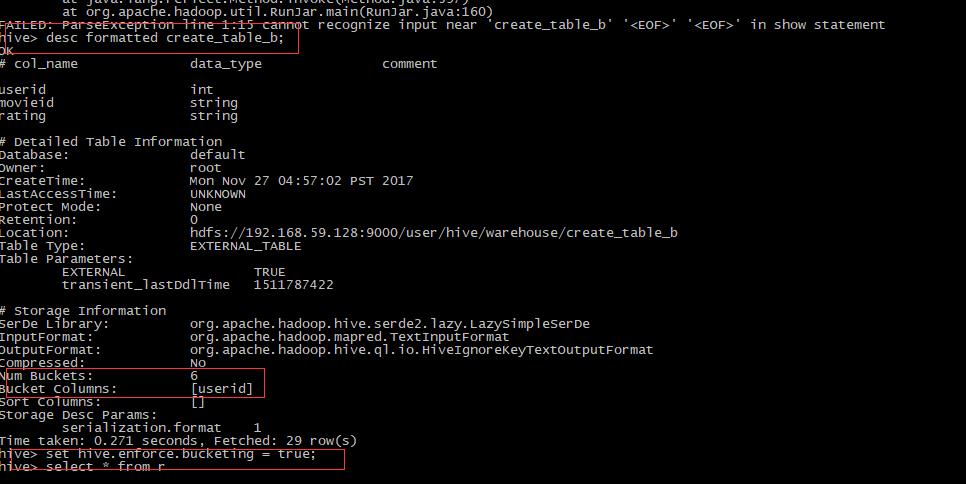
通过desc formatted create_table_b可以查看该表的结构,此外我们还需要
set hive.enforce.bucketing =true设置hive对该表进行bucket分区操作,
为了方便我们将另外一张表中查询出来的数据插入到create_table_b中,
from rating_table insert overwrite into table create_table_b select userId,movieId,rating;
数据插入完成后,进入Hadoop /user/hive/warehouse/create_table_b目录下可以看到表create_table_b已经按照我们设定的bucket数目分成了6个文件,我们可以打开一个文件 ,通过echo $[userid%6],对各个小表中的userid进行取模验证表中的数据是否按照我们的预期,分入到对应编号的bucket中。
根据上面bucket分区后的表进行抽样操作
我们将新建一张test_1的表,将抽样的数据放入该表,通过 tablesample(bucket x out of y on userid)指定抽样形式,x代表从哪一个bucket开始抽取,y的取值决定了抽样的个数,需要注意的是,y的值需要为bucket值的倍数或者因子,这个例子我们设定的参数为tablesample(bucket 1 out of 2 on userid),代表从第1个bucket开始抽样,抽样个数等于6/2为3个,
则抽取的bucket为第1个,第1+2个。第1+2+2个。
以上是关于hive---实践的主要内容,如果未能解决你的问题,请参考以下文章