重磅:关于hive的join使用必须了解的事情
Posted 浪尖聊大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重磅:关于hive的join使用必须了解的事情相关的知识,希望对你有一定的参考价值。
Hive支持连接表的以下语法:
本文主要讲hive的join
编写连接查询时要考虑的一些要点如下,不同版本支持的情况可能会有些许不同:
1,可以编写复杂的链接表达式,如下
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
SELECT a.* FROM a LEFT OUTER JOIN b ON (a.id <> b.id)
2,在同一查询中可以连接两个以上的表,例如
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
3,如果每个表在连接子句中使用了相同的列,则Hive将多个表上的连接转换为单map/reduce作业
如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
上面的sql被转换成一个map / reduce作业,因为只有b的key1列参与了连接。另一方面
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
上面的sql被转换成两个map / reduce作业,因为来自b的key1列在第一个连接条件中使用,而来自b的key2列在第二个连接条件中使用。第一个map / reduce作业与b连接,然后在第二个map / reduce作业中将结果与c连接。
4,在join的每个map/reduce stage中,和其它被缓存的表一样,序列中的最后一个表是通过reducer进行流式传输。 因此,通过组织这些表使得最大的表出现在最后一个序列中,可以减少reducer中用于缓冲特定连接键值的行所需的内存。例如
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
所有这三个表都加入到一个map /reduce 作业中,表a和b的键的特定值的值被缓存在reducer的内存中。 然后,对于从c中检索的每一行,都会使用缓存的行计算连接。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
同样的上面的sql有两个map / reduce参与计算连接。其中的第一个join是a和b,并缓存a的值,同时在reducers中流式传输b的值。其中第二个作业缓冲了第一个连接的结果,同时通过reducer流式传输c的值。
5,在每个连接的map / reduce阶段,可以通过提示来指定要流式传输的表。例如
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
所有这三个表都加入到一个map / reduce作业中,并且表b和c的键的特定值的值被缓存在reducer中的内存中。然后,对于从a中检索的每一行,都会使用缓冲的行计算连接。如果省略了STREAMTABLE提示,则Hive会将最右边的表加入连接。
6,存在LEFT,RIGHT和FULL OUTER连接,已提供对这些未匹配到的行在on 条件语句上的控制权。例如:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
这个查询将返回一行中的每一行。当有一个等于a.key的b.key时,这个输出行将是a.val,b.val,当没有相应的b.key时,输出行将是a.val,NULL。从没有对应的a.key的行将被删除。
语法“FROM LEFT OUTER JOIN b”必须写在一行上,以便理解它是如何工作的 - a是在这个查询中在b的左边,所以a中的所有行都保留;
RIGHT OUTER JOIN将保留来自b的所有行,并且FULL OUTER JOIN将保留来自a和b的所有行。OUTER JOIN语义应该符合标准的SQL规范。
7,连接发生在where之前。因此,如果要限制连接的OUTPUT,则需要在WHERE子句中,否则应该在JOIN子句中。这个问题的一大困惑是分区表:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
上面的sql将中对a和b进行连接,产生a.val和b.val的列表。但是,WHERE子句也可以引用连接输出中的a和b的其他列,然后将其过滤掉。但是,每当JOIN的某行为b找到一个键而没有键时,b的所有列都将为NULL,包括ds列。这就是说,你将过滤掉没有有效的b.key的所有连接输出行,因此你已经超出了你的LEFT OUTER要求。换句话说,如果在WHERE子句中引用b的任何一列,则连接的LEFT OUTER部分是无关紧要的。相反,当外部连接时,使用下面的语法:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b
ON (a.key=b.key AND b.ds='2009-07-07' AND a.ds='2009-07-07')
结果是连接的输出被预先过滤,并且您将不会得到有一个有效的a.key但没有匹配的b.key行的后过滤的麻烦。相同的逻辑适用于右和全连接。
8,连接不可交换!连接是左关联的,无论它们是左或右连接。
SELECT a.val1, a.val2, b.val, c.val
FROM a
JOIN b ON (a.key = b.key)
LEFT OUTER JOIN c ON (a.key = c.key)
首先对a和b进行join,丢弃在其他表中没有a相应的键的a或b中的所有内容。然后将减小后的表跟c表进行join。这提供了不直观的结果,如果在a和c中都存在一个键,但b中不存在:整个行(包括a.val1,a.val2和a.key)在“a JOIN b”步骤中被删除,因为它不在b中存在。结果没有a.key,所以当它与c进行 LEFT OUTER JOIN的时候,c.val被删除了,因为没有与a.key相匹配的c.key(因为a的那一行被删除了)。同样,如果这是一个RIGHT OUTER JOIN(而不是LEFT),我们最终会得到一个更奇怪的效果:NULL,NULL,NULL,c.val,因为即使我们指定了a.key = c.key作为连接键,我们删除了与第一个JOIN不匹配的所有行。
为了达到更直观的效果,我们应该改为 FROM c LEFT OUTER JOIN a ON (c.key = a.key) LEFT OUTER JOIN b ON (c.key = b.key).
9,LEFT SEMI JOIN以有效的方式实现不相关的IN / EXISTS子查询语义。从Hive 0.13开始,使用子查询支持IN / NOT IN / EXISTS / NOT EXISTS运算符,因此大多数这些JOIN不必手动执行。使用LEFT SEMI JOIN的限制是右边的表只能在连接条件(ON子句)中引用,而不能在WHERE或SELECT子句中引用。
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
可以改写为:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b ON (a.key = b.key)
10,如果除了一个连接的表之外的所有表都很小,则连接可以作为仅map工作来执行。
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a JOIN b ON a.key = b.key
上面的查询不需要reduce。对于每个mapper,a,b都被完全读取。限制是不能执行FULL / RIGHT OUTER JOIN b。
11,如果被连接的表在连接列上被分桶,并且一个表中的桶的数量是另一个表中的桶的数量的倍数,则桶可以彼此连接。如果表A有4个桶,而表B有4个桶,则下列联接
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM A a JOIN B b ON a.key = b.key
仅仅在mapper上即可完成连接完成。不是为每个A的mapper去完全获取B,而只是获取所需的桶。对于上面的查询,A的映射器处理存储桶1将仅取出B的桶1.它不是默认的行为,可以使用以下参数使能:
set hive.optimize.bucketmapjoin = true
12,如果连接的表在连接列上进行排序和分桶,并且具有相同数量的存储桶,则可以执行sort-merge连接。相应的桶在mapper上相互连接。如果A和B都有4个桶,
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM A a JOIN B b ON a.key = b.key
上面的功能尽在mapper即可完成。A的桶的映射器将遍历B的相应桶。这不是默认行为,需要设置以下参数:
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
如有疑问请参考官方链接
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Joins
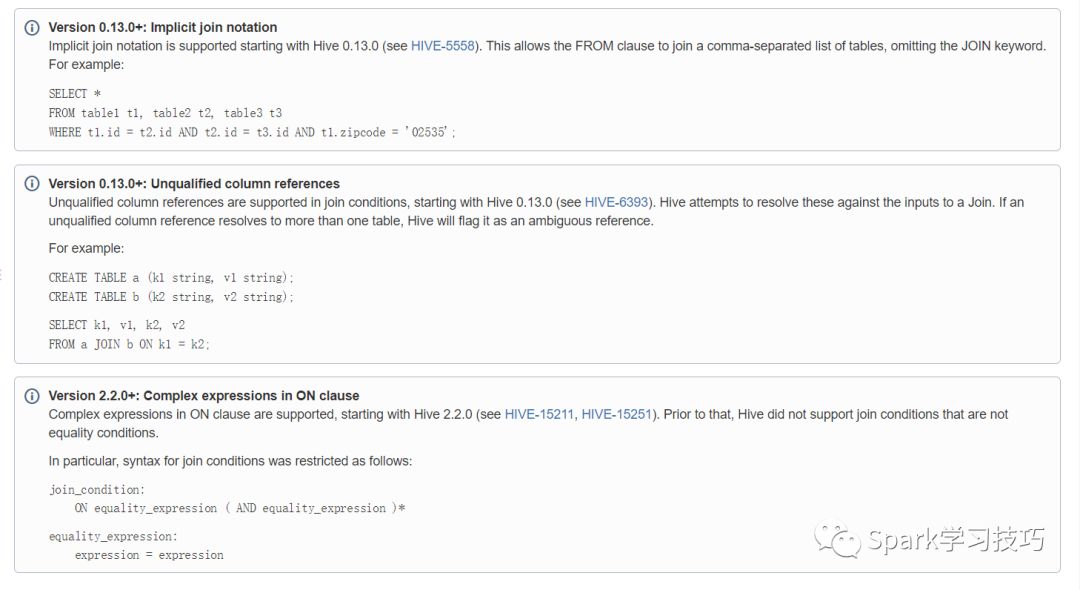
对于hive不同版本join的不支持情况,浪尖这里给出如下官方截图,:
推荐阅读:
1,
2,
3,
4,
关于Spark学习技巧
更多文章,敬请期待
以上是关于重磅:关于hive的join使用必须了解的事情的主要内容,如果未能解决你的问题,请参考以下文章