如何获取Hive正在执行或者已结束的的MapReduce作业的SQL语句
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何获取Hive正在执行或者已结束的的MapReduce作业的SQL语句相关的知识,希望对你有一定的参考价值。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
Fayson的github:https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档编写目的
当我们提交Hive SQL语句到YARN后,有时如果我们想监控某个SQL的执行情况,需要查看具体SQL语句,如果这个SQL语句比较长,无论是通过YARN的8088界面还是YARN的命令都无法看全这个SQL语句。
YARN的8088界面如下:
查看作业详情也无法看到完整SQL语句
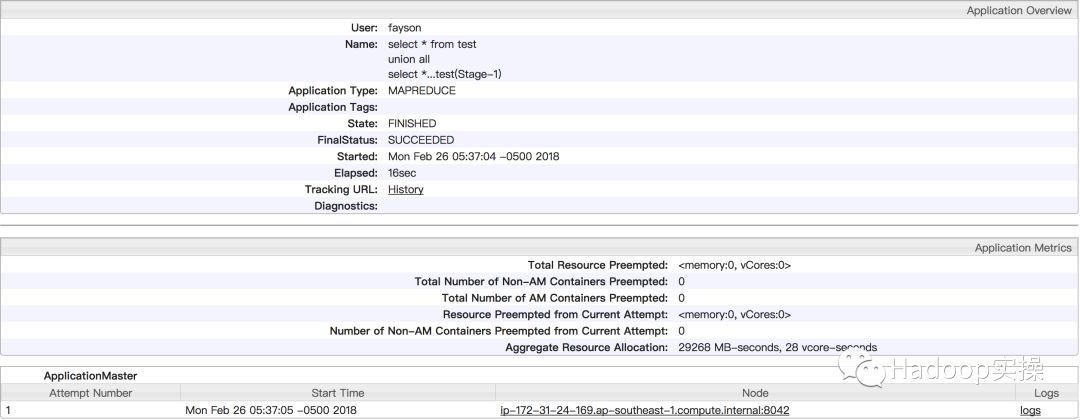
yarn application -list同样无法看全SQL语句,如下:

本文主要介绍三种方式来获取Hive正在执行或者已结束的的MapReduce作业的SQL语句,一种是通过MapReduce API获取执行作业的xml配置文件,另一种是通过Cloudera Manager界面直接查看,第三种是通过Cloudera Manager的API来获取。
测试环境
1.操作系统RedHat7.3
2.CM和CDH版本为5.13.1
3.集群已启用Kerberos
2.通过YARN执行作业的xml配置文件获取
1.使用fayson用户登录hue执行SQL查询
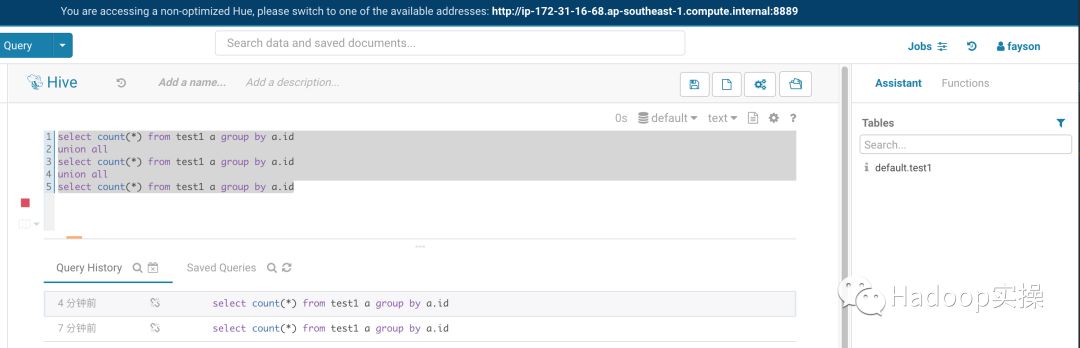
2.通过SQL的ApplicationID获取到作业的配置信息
curl -H "Accept: application/json" -X \
GET http://ip-172-31-16-68.ap-southeast-1.compute.internal:8088/proxy/application_1519613953021_0029/ws/v1/mapreduce/jobs/job_1519613953021_0029/conf > a.xml
(可左右滑动)

3.通过hive.query.string属性过滤查看a.xml文件

通过获取接口获取运行中Hive作业可以查看到Hive的SQL语句,该信息对应到HDFS的/user/$USER/.staging/$JOBID/job.xml文件中。
4.如果作业执行完成将接口改为JobHistory的API接口执行
curl -H "Accept: application/json" -X \
GET http://ip-172-31-16-68.ap-southeast-1.compute.internal:19888/ws/v1/history/mapreduce/jobs/job_1519613953021_0029/conf > b.xml
(可左右滑动)


通过JobHistory的API接口获取Hive历史作业执行的完整SQL语句,该信息对应到HDFS的/user/history/done/2018/02/26/000000/job_1519613953021_0029_conf.xml文件中
3.通过Cloudera Manager来获取
1.进入Yarn的“应用程序”页面
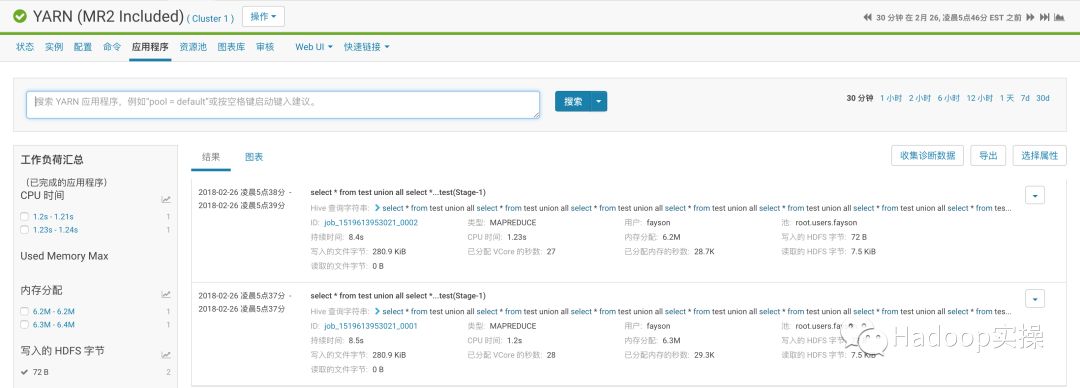
2.在“搜索”中选择“Hive应用程序”
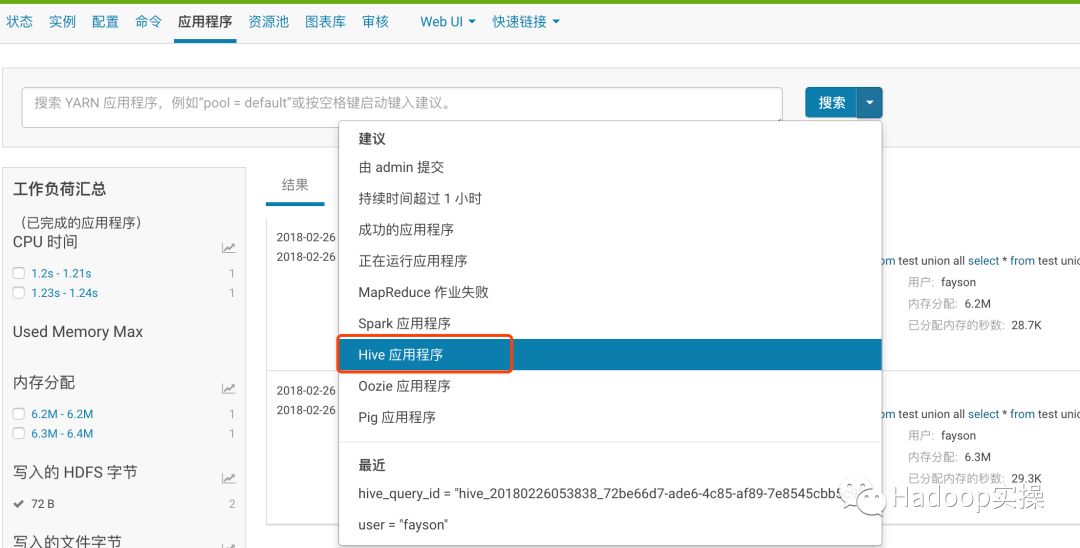
过滤筛选Hive应用程序
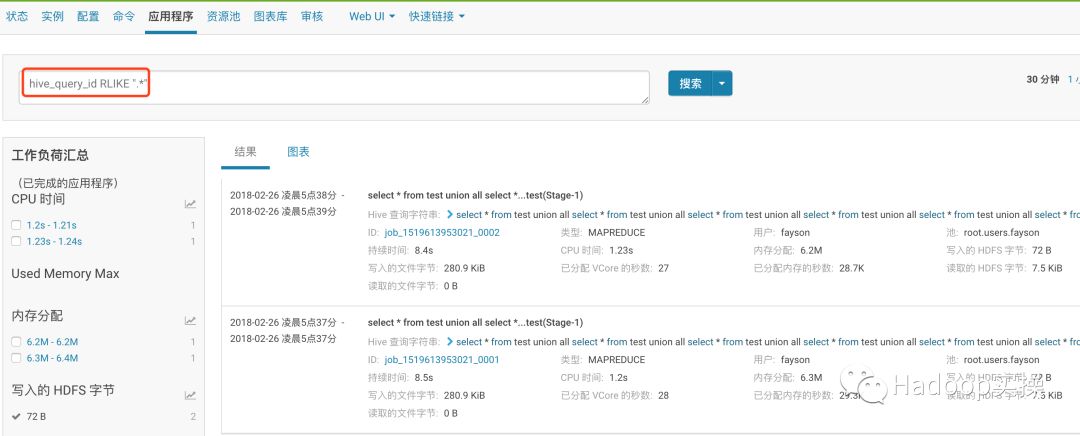
3.选择某个Hive作业,点击箭头可以展开查看完整的SQL,并察看查询的基本统计信息

4.通过Cloudera Manager的API接口获取
1.在命令行执行如下命令获取作业详细信息
[root@ip-172-31-16-68 ~]# curl -u admin:admin "http://ip-172-31-16-68.ap-southeast-1.compute.internal:7180/api/v16/clusters/luster/services/yarn/yarnApplications"
(可左右滑动)
通过查看hive_query_string属性查看到我们运行的完整的SQL语句。
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于如何获取Hive正在执行或者已结束的的MapReduce作业的SQL语句的主要内容,如果未能解决你的问题,请参考以下文章
用sqoop将数据从mysql导入hive报错:org.apache.hadoop.mapred.FileAlreadyExistsException: Output
hive启动报错 java.lang.ClassNotFoundException: org.apache.hadoop.mapred.MRVersion