SQLHive SQL详解
Posted Panda大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQLHive SQL详解相关的知识,希望对你有一定的参考价值。
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行,通过自己的SQL 去查询分析需要的内容,这套SQL 简称Hive SQL。使不熟悉mapreduce 的用户很方便的利用SQL 语言查询,汇总,分析数据。而mapreduce开发人员可以把己写的mapper 和reducer 作为插件来支持Hive 做更复杂的数据分析。
hive sql与关系型数据库的SQL 略有不同,但支持了绝大多数的语句如DDL、DML 以及常见的聚合函数、连接查询、条件查询。
hive不适合用于联机,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。
hive的特点:可伸缩(在Hadoop的集群上动态的添加设备),可扩展,容错,输入格式的松散耦合。
01
DDL
1-1 创建表

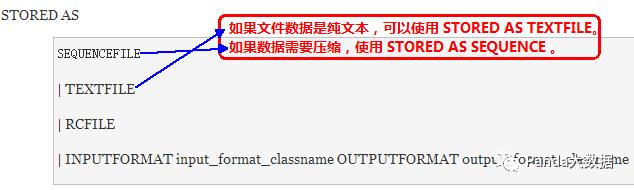
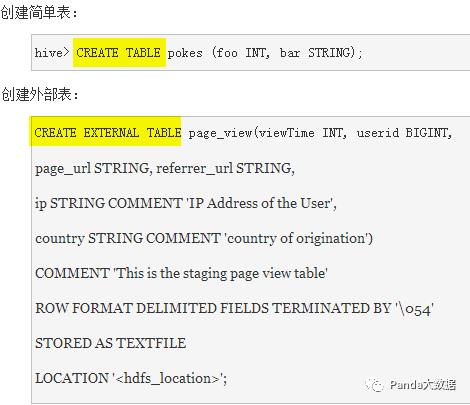
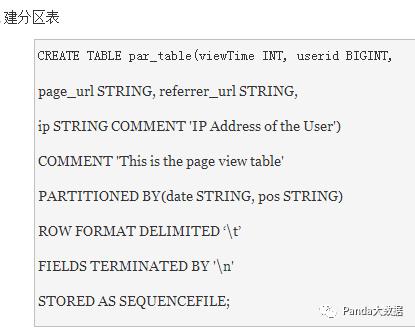
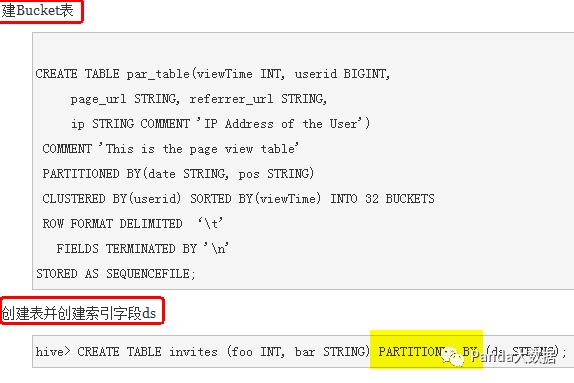
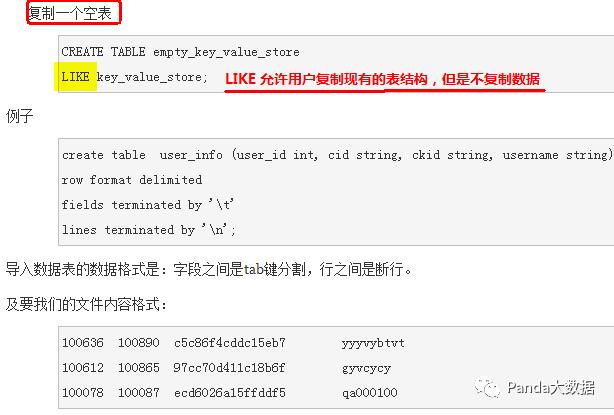

1-2 修改表结构




1-3 创建删除视图
CREATE VIEW [IF NOT EXISTS] view_name [ (column_name [COMMENT column_comment], ...) ][COMMENT view_comment][TBLPROPERTIES (property_name = property_value, ...)] AS SELECT |
增加视图
如果没有提供表名,视图列的名字将由定义的SELECT表达式自动生成
如果修改基本表的属性,视图中不会体现,无效查询将会失败
视图是只读的,不能用LOAD/INSERT/ALTER
删除视图
DROP VIEW view_name
创建数据库
CREATE ATABASE name
显示命令
show tables; |
02
DML
hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。数据是以load的方式加载到建立好的表中,数据一旦导入就不可以修改。
DML包括:INSERT插入、UPDATE更新、DELETE删除
向数据表内加载文件
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)]
Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。
filepath

包含模式的完整 URI,例如:hdfs://namenode:9000/user/hive/project/data1
例如:
hive> LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
加载本地数据,同时给定分区信息
加载的目标可以是一个表或者分区。如果表包含分区,必须指定每一个分区的分区名。filepath 可以引用一个文件(这种情况下,Hive 会将文件移动到表所对应的目录中)或者是一个目录(在这种情况下,Hive 会将目录中的所有文件移动至表所对应的目录中)
LOCAL关键字
指定了LOCAL,即本地
oad 命令会去查找本地文件系统中的 filepath。如果发现是相对路径,则路径会被解释为相对于当前用户的当前路径。用户也可以为本地文件指定一个完整的 URI,比如:file:///user/hive/project/data1.
load 命令会将 filepath 中的文件复制到目标文件系统中。目标文件系统由表的位置属性决定。被复制的数据文件移动到表的数据对应的位置
例如:加载本地数据,同时给定分区信息:
hive> LOAD DATA LOCAL INPATH './examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');
没有指定LOCAL
如果 filepath 指向的是一个完整的 URI,hive 会直接使用这个 URI。 否则
如果没有指定 schema 或者 authority,Hive 会使用在 hadoop 配置文件中定义的 schema 和 authority,fs.default.name 指定了 Namenode 的 URI
如果路径不是绝对的,Hive 相对于 /user/ 进行解释。 Hive 会将 filepath 中指定的文件内容移动到 table (或者 partition)所指定的路径中。
OVERWRITE
指定了OVERWRITE
目标表(或者分区)中的内容(如果有)会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。
03
HQL
例如:
按先件查询
hive> SELECT a.foo FROM invites a WHERE a.ds='<DATE>';
将查询数据输出至目录:
hive> INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='<DATE>';
将查询结果输出至本地目录:
hive> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/local_out' SELECT a.* FROM pokes a;
选择所有列到本地目录:
hive> INSERT OVERWRITE TABLE events SELECT a.* FROM profiles a; |
将一个表的统计结果插入另一个表中:
hive> FROM invites a INSERT OVERWRITE TABLE events SELECT a.bar, count(1) WHERE a.foo > 0 GROUP BY a.bar; |
将多表数据插入到同一表中:
FROM src |
将文件流直接插入文件:
hive> FROM invites a INSERT OVERWRITE TABLE events SELECT
TRANSFORM(a.foo, a.bar) AS (oof, rab) USING '/bin/cat' WHERE a.ds > '2008-08-09'; |
基于Partition的查询
一般 SELECT 查询会扫描整个表,使用 PARTITIONED BY 子句建表,查询就可以利用分区剪枝(input pruning)的特性
Hive 当前的实现是,只有分区断言出现在离 FROM 子句最近的那个WHERE 子句中,才会启用分区剪枝
join
join_table: table_reference: table_factor: join_condition: equality_expression: |
Hive 只支持等值连接(equality joins)、外连接(outer joins)和(left semi joins)。
Hive 不支持所有非等值的连接,因为非等值连接非常难转化到 map/reduce 任务。
LEFT,RIGHT和FULL OUTER关键字用于处理join中空记录的情况。
LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现。
join 时,每次 map/reduce 任务的逻辑是这样的:reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统
实践中,应该把最大的那个表写在最后。
join 查询时,需要注意几个关键点:
只支持等值join
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b
ON (a.id = b.id AND a.department = b.department)
可以 join 多于 2 个表,例如
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
如果join中多个表的 join key 是同一个,则 join 会被转化为单个 map/reduce 任务
LEFT,RIGHT和FULL OUTER
例子:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
如果你想限制 join 的输出,应该在 WHERE 子句中写过滤条件——或是在 join 子句中写
容易混淆的问题是表分区的情况
SELECT c.val, d.val FROM c LEFT OUTER JOIN d ON (c.key=d.key)
WHERE a.ds='2010-07-07' AND b.ds='2010-07-07‘
如果 d 表中找不到对应 c 表的记录,d 表的所有列都会列出 NULL,包括 ds 列。也就是说,join 会过滤 d 表中不能找到匹配 c 表 join key 的所有记录。这样的话,LEFT OUTER 就使得查询结果与 WHERE 子句无关
解决办法
SELECT c.val, d.val FROM c LEFT OUTER JOIN d
ON (c.key=d.key AND d.ds='2009-07-07' AND c.ds='2009-07-07')
LEFT SEMI JOIN
LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
可以被重写为:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key)
UNION ALL
用来合并多个select的查询结果,需要保证select中字段须一致。
select_statement UNION ALL select_statement UNION ALL select_statement ...
04
从SQL到hql习惯的转变
Hive不支持等值连接
SQL中对两表内联可以写成:
select * from dual a , dual b where a.key = b.key;
Hive中应为
select * from dual a join dual b on a.key = b.key;
而不是传统的格式:
SELECT t1.a1 as c1, t2.b1 as c2FROM t1, t2
WHERE t1.a2 = t2.b2
分号字符
分号是SQL语句结束标记,在HiveQL中也是,但是在HiveQL中,对分号的识别没有那么智慧,例如:
select concat(key,concat(';',key)) from dual;
但HiveQL在解析语句时提示:
FAILED: Parse Error: line 0:-1 mismatched input '<EOF>' expecting ) in function specification
解决的办法是,使用分号的八进制的ASCII码进行转义,那么上述语句应写成:
select concat(key,concat('\073',key)) from dual;
IS [NOT] NULL
SQL中null代表空值,
在HiveQL中String类型的字段若是空(empty)字符串, 即长度为0, 那么对它进行IS NULL的判断结果是False.
Hive不支持将数据插入现有的表或分区中,仅支持覆盖重写整个表:
INSERT OVERWRITE TABLE t1
SELECT * FROM t2;
hive不支持INSERT INTO, UPDATE, DELETE操作
这样的话,就不要很复杂的锁机制来读写数据。
INSERT INTO syntax is only available starting in version 0.8。INSERT INTO就是在表或分区中追加数据。
hive支持嵌入mapreduce程序,来处理复杂的逻辑
如:
FROM ( MAP doctext USING 'python wc_mapper.py' AS (word, cnt) FROM docs CLUSTER BY word ) a REDUCE word, cnt USING 'python wc_reduce.py'; FROM ( MAP doctext USING 'python wc_mapper.py' AS (word, cnt) FROM docs CLUSTER BY word ) a REDUCE word, cnt USING 'python wc_reduce.py'; |
--doctext: 是输入
--word, cnt: 是map程序的输出
--CLUSTER BY: 将wordhash后,又作为reduce程序的输入
并且map程序、reduce程序可以单独使用,如:
FROM ( FROM session_table SELECT sessionid, tstamp, data DISTRIBUTE BY sessionid SORT BY tstamp ) a REDUCE sessionid, tstamp, data USING 'session_reducer.sh'; FROM ( FROM session_table SELECT sessionid, tstamp, data DISTRIBUTE BY sessionid SORT BY tstamp ) a REDUCE sessionid, tstamp, data USING 'session_reducer.sh'; |
--DISTRIBUTE BY: 用于给reduce程序分配行数据
hive支持将转换后的数据直接写入不同的表,还能写入分区、hdfs和本地目录
这样能免除多次扫描输入表的开销。
FROM t1 INSERT OVERWRITE TABLE t2 SELECT t3.c2, count(1) FROM t3 WHERE t3.c1 <= 20 GROUP BY t3.c2
INSERT OVERWRITE DIRECTORY '/output_dir' SELECT t3.c2, avg(t3.c1) FROM t3 WHERE t3.c1 > 20 AND t3.c1 <= 30 GROUP BY t3.c2
INSERT OVERWRITE LOCAL DIRECTORY '/home/dir' SELECT t3.c2, sum(t3.c1) FROM t3 WHERE t3.c1 > 30 GROUP BY t3.c2; |
以上是关于SQLHive SQL详解的主要内容,如果未能解决你的问题,请参考以下文章