数据仓库工具 hive 的初级入门
Posted 小肉丸子的小当家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库工具 hive 的初级入门相关的知识,希望对你有一定的参考价值。
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。

数据库基本功能也就是增删查改,其他的功能都可以视为扩展功能。将hive安装到linux系统后,进入解压后的文件夹执行以下操作。
0:使用数据库
bin/hive 可以直接进入hive命令界面。如图

若不想进入命令界面,而在外部进行操作,则可以执行以下操作:
(1)bin/hive -e 'select * from default.student;
(2)或是在文件./datas/hivef.sql中写入sql 语句
然后执行 bin/hive -f ../datas/hivef.sql
(3)bin/hive -f ../datas/hivef.sql > /software/datas/hivef-res.txt (执行了并 将执行结果写入文件hive-res.txt)
以下操作均在hive界面进行
1:查看所有数据库
show databases ;
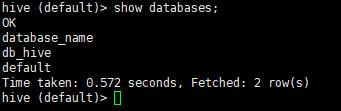
2:使用数据库
use default;
3:查看数据库中所有表
show tables ;
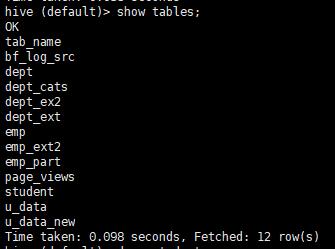
看表信息
desc student;
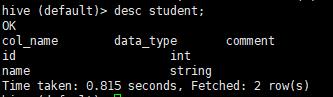
desc extended student;(详细信息,但格式太乱,不建议使用)
desc formatted student;(很清晰)


不仅有表格信息,还有存储信息等,非常详尽。
4;创建表
create table student(
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
以上创建了一张只有属性id 和name的表,最后定义了加载数据时,数据的分割方式,是以符号tab来分割的。
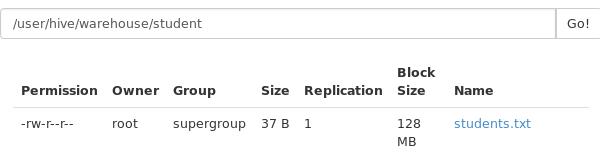
5:从文件中加载表中数据
load data local inpath '/opt/datas/student.txt'into table student ;
6.查找
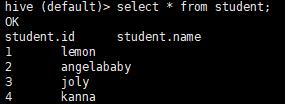
select * from student ;
select id from student ;
正确的结果为:
若是报错:

关闭hadoop安全模式,如下

若报错:

检查datanode是否健在,若是挂掉了,重新启动。
7.使用特定函数
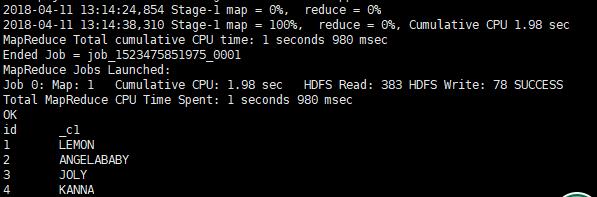
select id, upper(name) from default.student; (将name转化为大写)
以上命令使用了函数,默认执行mapreduce。
另外还有如下操作:
max/min/count/sum/avg (show function 可以查看hive自带的函数,
desc functionextented max;可以查看怎么使用某函数)
select max(sal) max_sal from emp;
select sum(sal) from emp;
还可以自己编写python脚本啊!骚操作!
8.数据的导出
方式1
insert overwrite local directory '/software/datas/hive_exp'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY '\n'
select * from default.emp;
方式2
bin/hive -e "select * from default.emp ;" > /software/datas/exp_res.txt
方式3:将保存在hdfs 中的结果保存到本地。
在hadoop下 :bin/hdfs dfs -get /user/lemon/hive/hive_exp/00000_0
方式4: sqoop(本文未涉及)
hdfs/hive -> rdbms
rdbms -> hdfs/hive/hbase
9.分组(group by)
需求1:每个部门的平均工资
select t.deptno ,avg(t.sal) avg_sal from emp t group by t.deptno;
having
select deptno,avg(sal)avg_sal from emp group by deptno having avg_sal > 2000;
10.join(链接两个 表)
select * from emp e join dept d on
e.deptno=d.deptno;
left join 和right join(以右表为准,左边为空则为空) full join 全链接
11.分区表
create EXTERNAL table IF NOT EXISTS default.emp_part
(
empno int ,
ename string,
job string,
)
partitioned by (month string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
load data local inpath '/software/datas/emp.txt'into table emp_part partition (month='201509');
select * from emp_part where month='201509';
12.删除表
drop table if exists default.dept_like_rename;
好啦!简单介绍就到这里咯~~~
所以大数据薪资高是有原因的TAT~
以上是关于数据仓库工具 hive 的初级入门的主要内容,如果未能解决你的问题,请参考以下文章