举一反三-Pandas实现Hive中的窗口函数
Posted 小小挖掘机
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了举一反三-Pandas实现Hive中的窗口函数相关的知识,希望对你有一定的参考价值。
1、Hive窗口函数
我们先来介绍一下Hive中几个常见的窗口函数,row_number(),lag()和lead()。
row_number()
该函数的格式如下:
row_Number() OVER (partition by 分组字段 ORDER BY 排序字段 排序方式asc/desc)
简单的说,我们使用partition by后面的字段对数据进行分组,在每个组内,使用ORDER BY后面的字段进行排序,并给每条记录增加一个排序序号。
lag()
该函数的格式如下:
lag(字段名,N) over(partition by 分组字段 order by 排序字段 排序方式)
lag括号里理由两个参数,第一个是字段名,第二个是数量N,这里的意思是,取分组排序后比该条记录序号小N的对应记录的指定字段的值,如果字段名为ts,N为1,就是取分组排序后上一条记录的ts值。
lead()
该函数的格式如下:
lead(字段名,N) over(partition by 分组字段 order by 排序字段 排序方式)
lead括号里理由两个参数,第一个是字段名,第二个是数量N,这里的意思是,取分组排序后比该条记录序号大N的对应记录的对应字段的值,如果字段名为ts,N为1,就是取分组排序后下一条记录的ts值。
有关这几个函数的详细的实例,可以参考我之前写过的文章:https://www.jianshu.com/p/3738d3591da9,这里我们就不再赘述。
2、窗口函数的Pandas实现
接下来,我们介绍如何使用Pandas来实现上面的几个窗口函数。
数据使用
我们建立如下的测试数据集:
df = pd.DataFrame({'A':[12,20,12,5,18,11,18],
'C':['A','B','A','B','B','A','A']})
我们使用C作为分组列,使用A作为窗口列。
2.1 row_number()
该函数的意思即分组排序,在pandas中我们可以结合groupby和rank函数来实现和row_number()类似的功能。
我们先看一下实现代码:
df['row_number'] = df['A'].groupby(df['C']).rank(ascending=True,method='first')
print(df)
代码的输出为:
这样我们的row_number功能就实现了,groupby方法大家应该很熟悉了,那么我们主要介绍一下rank函数,rank函数主要有两个参数,首先是ascending参数,决定是按照升序还是降序排列,这里我们选择的是升序。第二个参数是填充方式,主要有以下几种方式:
dense:稠密的方式,即当两个或多个的数值相同时,使用同样的序号,同时后面的序号是该序号+1,即多个相同的值只会占用一个序号位,例如四个数的排序,中间两个数相同,那么四个数的排序为1,2,2,3.
我们用代码看一下效果:
df = pd.DataFrame({'A':[12,20,12,5,18,11,18],
'C':['A','B','A','B','B','A','A']})
df['row_number'] = df['A'].groupby(df['C']).rank(ascending=True,method='min')
print(df)
输出为:

first:即当两个或多个的数值相同时,使用不样的序号,按照数据出现的先后顺序进行排序,这个其实跟row_number的实现是相同的。
df = pd.DataFrame({'A':[12,20,12,5,18,11,18],
'C':['A','B','A','B','B','A','A']})
df['row_number'] = df['A'].groupby(df['C']).rank(ascending=True,method='first')
print(df)
输出为:

max :当两个或多个的数值相同时,使用相同的序号,不过使用的是能达到的最大的序号值。例如四个数的排序,中间两个数相同,那么四个数的排序为1,3,3,4.
df = pd.DataFrame({'A':[12,20,12,5,18,11,18],
'C':['A','B','A','B','B','A','A']})
df['row_number'] = df['A'].groupby(df['C']).rank(ascending=True,method='max')
print(df)
输出为:

min :当两个或多个的数值相同时,使用相同的序号,不过使用的是能达到的最小的序号值。例如四个数的排序,中间两个数相同,那么四个数的排序为1,2,3,4.
df = pd.DataFrame({'A':[12,20,12,5,18,11,18],
'C':['A','B','A','B','B','A','A']})
df['row_number'] = df['A'].groupby(df['C']).rank(ascending=True,method='min')
print(df)
输出为:

2.2 lag/lead函数
pandas中使用shift函数来实现lag/lead函数,首先我们来看一个例子:
df = pd.DataFrame({'A':[12,20,12,5,18,11,18],
'C':['A','B','A','B','B','A','A']})
df['lag'] = df.sort_values('A').groupby('C')['A'].shift(1)
df['lead'] = df.sort_values('A').groupby('C')['A'].shift(-1)
print(df)
输出为:
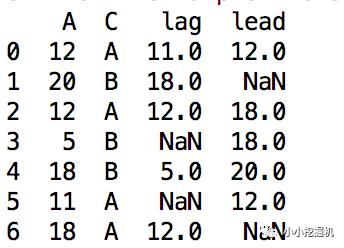
可以看到,当shift函数中的数字为正数时,我们就实现了lag的功能,当数字为负数时,实现的是lead的功能。不过这里切记,一定要排序哦,否则可能出现下面的结果:
df = pd.DataFrame({'A':[12,20,12,5,18,11,18],
'C':['A','B','A','B','B','A','A']})
df['lag'] = df.groupby('C')['A'].shift(1)
df['lead'] = df.groupby('C')['A'].shift(-1)
print(df)
输出为,这个就是完全根据数据出现的顺序进行排序的,不符合我们的要求!
好啦,两个简单的小应用就介绍到这里了,希望可以帮到大家。
以上是关于举一反三-Pandas实现Hive中的窗口函数的主要内容,如果未能解决你的问题,请参考以下文章