友盟“Data Geek”专栏 | 友盟 Hive 数据仓库专题模式设计
Posted 友盟数据服务
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了友盟“Data Geek”专栏 | 友盟 Hive 数据仓库专题模式设计相关的知识,希望对你有一定的参考价值。
大数据运用是行业中的一大难题。友盟作为一家数据公司,是如何将数据落地,构建起完备的数据体系结构,以供信息决策和数据挖掘的呢?今天友盟君邀请了数据仓库负责人为我们从模式、性能以及架构层面呈现出友盟数据仓库如何管理海量数据的。
数据仓库的起源可以追溯到计算机与信息系统发展的初期。它是信息技术长期复杂演化的产物,并且直到今天这种演化仍然在继续进行着。而数据仓库容易让人糊涂的地方在于它是一种体系结构,而不是一种技术。这点使得许多技术人员和风投都感到沮丧,因为他们希望的是打好成包的专业技术,而非具有哲学意义的体系架构。
本系列旨在于讲述Hive搭建数据仓库过程中的一些要点,所以希望读者理解Hive和数据仓库的区别和联系。
Hive是Hadoop 生态圈中实现数据仓库的一项技术。虽然Hadoop和HDFS的设计局限了Hive所能胜任的工作,但是Hive仍然是目前互联网中最适合数据仓库的应用技术。 不论从“品相还是举止”,Hive都像一个关系型数据库。用户对数据库、表和列这类术语比较熟悉的话,那么掌握Hive的查询语言HQL也轻而易举。不过,Hive的实现和使用方式与传统的关系数据库相比,有很多不同的地方。
我们Hive的第一篇文章就将讲到Hive数仓中模式设计的三把斧:内部表和外部表、分区和分桶以及序列化/反序列化(SerDe)。
一. 内部表和外部表
Hive将数据表分为内部表和外部表。
内部表
在Hive中创建的普通表都可称作“内部表”。因为Hive可以(或多或少)控制其数据的生命周期,内部表对数据拥有所有权。如我们所见,通常Hive会将内部表的数据储存在由hive.metastore.warehouse.dir所定义的目录下。
所以,当删除一个内部表时,相应的数据也会被删除。
外部表
内部表不方便共享数据源。例如,当采用如Pig或MapReduce等技术工具进行数据处理时,我们将无法读取内部表的数据,也不能将外部数据直接作为内部表数据源分享给Hive。这样的需求就诞生了外部表。不同于内部表,Hive 对外部表的数据仅仅拥有使用权,而数据位置可由表管理者任意配置。
如何理解外部表呢?
如图所示,外部表不需要将数据复制到Hive中。一旦关联上数据格式和数据位置,Hive就能直接访问外部数据,非常灵活方便,即插即用。
而加载内部表数据时,Hive会自动将源数据拷贝到内部。内部表其实访问的是数据副本。
注意,Hive加载内部表数据后会把数据源删除,很像"剪切/移动"。所以,往内部表上传数据时,千万记得备份!
二. 分区和分桶
分区
对于大型数据处理系统而言,数据分区的功能是非常重要的。因为Hive通常要对数据进行全盘扫描,才能满足查询条件(我们暂时先忽略索引的功能)。
以Hive管理大型网站的浏览日志为例。如果日志数据表不采用分区设计,那么就单日网站流量分析这样的需求而言,Hive就必然要通过遍历全量日志来完成查询。以一年日志为全量,单日查询的数据利用率将不到1%,这样的设计基本上将查询时间浪费在了数据加载中。
分区的优势在于利用维度分割数据。在使用分区维度查询时,Hive只需要加载数据,极大缩短数据加载时间。上述案例中,假使我们以日期为维度设计日志数据表的分区,对于自选日期范围的查询需求,Hive就只需加载日期范围所对应的分区数据。
由于HDFS被设计用于存储大型数据文件而非海量碎片文件,理想的分区方案不应该导致过多的分区文件,并且每个目录下的文件尽量超过HDFS块大小的若干倍。按天级时间粒度进行分区就是一个好的分区策略,随着时间的推移,分区数量增长均匀可控。此外常有的分区策略还有地域,语言种类等等。设计分区的时候,还有一个误区需要避免。关于分区维度的选择,我们应该尽量选取那些有限且少量的数值集作为分区,例如国家、省份就是一个良好的分区,而城市就可能不适合进行分区。
注意:分区是数据表中的一个列名,但是这个列并不占有表的实际存储空间。它作为一个虚拟列而存在。
分桶
分区提供了一种整理数据和优化查询的便利方式。不过,并非所有数据集都可形成合理的分区,特别是在需要合理划分数据、防止倾斜时。分桶是将数据分解管理的另一技术。
假设我们有一张地域姓名表并按城市分区。那么很有可能,北京分区的人数会远远大于其他分区,该分区的数据I/O吞吐效率将成为查询的瓶颈。如果我们对表中的姓名做分桶,将姓名按哈希值分发到桶中,每个桶将分配到大致均匀的人数。
分桶解决的是数据倾斜的问题。因为桶的数量固定,所以没有数据波动。桶对于数据抽样再适合不过,同时也有利于高效的map-side Join。
分桶与分区的关系
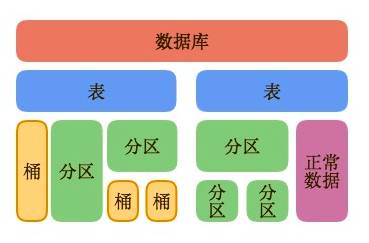
分区和分桶都可以单独用于表;
分区可以是多级的;
分区和分桶可以嵌套使用,但是分区必须在分桶前面。
三. 序列化/反序列化(SerDe)
如果说前两者分别是Hive模式设计的沙漠飞鹰和AK47,那么SerDe就是巡航导弹。
下面我们来看一下SerDe是什么。
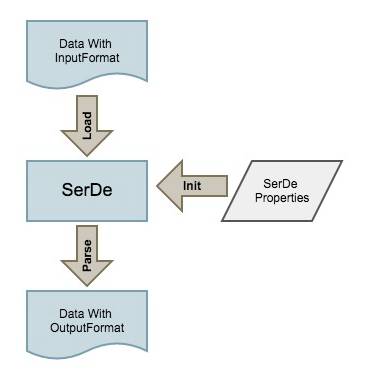
SerDe是序列化/反序列化的简写形式,其作用是将一条非结构化字节转化成Hive可以使用的一条记录。Hive本身自带了几个内置的SerDe,而一些第三方的SerDe也十分常用。
我们举例介绍一下常见SerDe:
RegexSerDe
CSVSerde/TSVSerde
JsonSerde
AvroSerDe
LazySimpleSerDe
......
以JsonSerde为例
create external table messages (
msg_id bigint,
date string,
text string,
id bigint,
name string
)
row format serde "org.apache.hadoop.hive.contrib.serde2.JsonSerde"
with serdeproperties (
"msg_id"="$.id",
"date"="$.created_at",
"text"="$.text",
"id"="$.user_id",
"name"="$.user_name"
)
location '/data/messages';本例中,/data/messages文件为Json格式。JsonSerde读取messages中的每一条记录,并解析成Json Object,在代码中以$表示。类似"msg_id"="$.id"这样的操作语句,表示获取$["id"]的数据内容并转化成messages中的msg_id。
一旦定义好之后,用户就不再需要关心如何读取解析Json数据,可以像操作数据库数据一样操作Json数据。
serdeproperties是Hive提供给SerDe的一个功能,Hive并不关心这些配置属性是什么。在读取文件记录的时候,SerDe读取相应的配置信息来完成解析工作。也就是说,serdeproperties其实是SerDe的配置界面,一种SerDe拥有一种配置信息格式,而不同SerDe之间的serdeproperties配置信息并没有任何关联。
下图为SerDe的工作原理
Hive的SerDe着实是一项重磅武器。对于绝对大多数常用的数据格式,Hive官方或者第三方都提供了相应的SerDe。如果有公司和团队剑走偏锋,采用一些“非凡”的数据格式,仍然可以自定义SerDe。
例如,友盟的移动APP日志数据就采用Google Protobuf格式,并选用高压缩比的lzma/lzo作为压缩算法,而Hive原生态组件中并不支持解析这样的数据格式。如果将Protobuf+lzo的数据转化成文本或者Json以方便Hive读取,又将面临大量的数据冗余。友盟数据仓库搭建采用了Twitter开源项目ElephantBird提供的“ProtobufDeserializer”,又在此基础上实现了对lzo/lzma的解压缩功能,无缝地对接上了友盟数据平台的离线日志。 友盟的小伙伴们从此走上了幸福而快乐的数据分析之路。
Hive的模式设计讲到这里就已经结束了,大家是否有意犹未尽,还想深入了解Hive的其他内容呢?
敬请期待下文:关于Hive数据仓库的那些事儿(二)数据结构。
扩展阅读
https://cwiki.apache.org/confluence/display/Hive/Tutorial
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
https://cwiki.apache.org/confluence/display/Hive/SerDe
以上是关于友盟“Data Geek”专栏 | 友盟 Hive 数据仓库专题模式设计的主要内容,如果未能解决你的问题,请参考以下文章