Hive sql大数据有道之Hive sql去重
Posted 大数据有道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive sql大数据有道之Hive sql去重相关的知识,希望对你有一定的参考价值。
Hive是基于Hadoop之上的数据仓库基础框架,可以将结构化的HDFS数据文件映射为数据库表。Hive提供了完善的sql功能实现数据的ETL(抽取Extract、转换Transform和加载Load),即Hive sql。
Hive sql是分析和统计Hadoop分布式数据文件的利器,即使不熟悉map和reduce原理/模型的同学也可以快速上手,灵活掌握大数据开发技巧。
大数据去重
在Hive sql学习和使用中不免遇到数据去重的场景,如统计江南皮革厂有效订单量等。
这里大数据有道给大家介绍一下,Hive sql常用的三种去重技巧:
i. distinct
ii. group by
iii. row_number() over()
首先,我们虚构一个江南皮革厂,2018年4月15日有335150条订单,各条订单中都有唯一的标识ID(order_id)对应一笔交易。

根据交易流程,在系统上报该交易信息时依次会有已下单、已支付、已发货、配送中、已接收、已退货、已退款等多种事务状态,而且每个事务的发生都会在Hive表中生成一条记录。因此,当天实际交易量(唯一order_id)可能只有70000单左右。
具体参考xiongda的订单流程: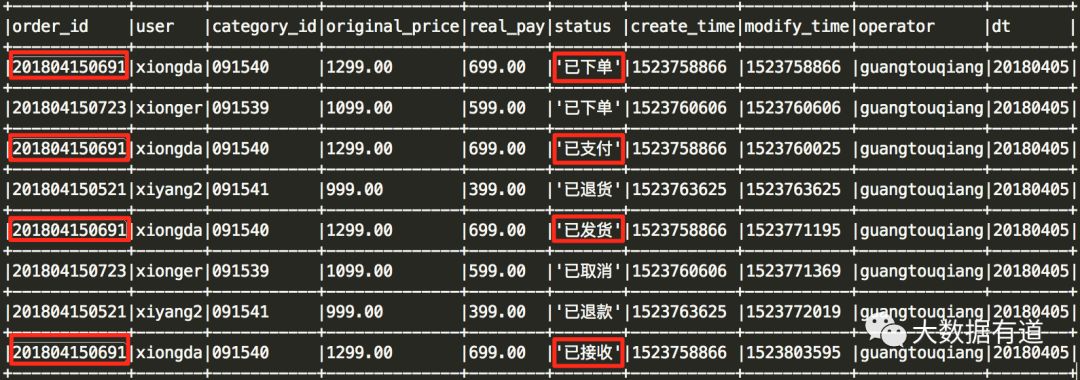
俗话讲,磨刀不误砍柴工。在执行Hive sql作业前,需要评估原始数据量,然后配置Hive中mapper和reducer的执行参数。
set mapred.max.split.size=256000; //每个mapper处理的最大的文件大小,单位为B
set mapred.min.split.size.per.node=256000; //节点中可以处理的最小的文件大小,单位为B
set mapred.min.split.size.per.rack=256000; //机架中可以处理的最小的文件大小,单位为B
set hive.exec.reducers.max=100; //每个任务中最大的reduce数
set hive.exec.reducers.bytes.per.reducer=102400000; //每个reducer处理的数据量,单位B
顾名思义,distinct通过大量数据(如果数据集确实很大的话)之间的shuffle比较(混洗)筛选出所有唯一标识的结果集。
a.统计当天订单Hive sql:
 b.执行日志:
b.执行日志:
MapReduce Jobs Launched: Stage-Stage-1: Map: 97 Reduce: 1 Cumulative CPU: 383.02 sec HDFS Read: 24407412 HDFS Write: 789899
SUCCESS
Total MapReduce CPU Time Spent: 6 minutes 23 seconds 20 msec
OK
Time taken: 93.535 seconds, Fetched: 71809 row(s)
c.逻辑分析:该Hive sql作业时启动97个mapper拉取了数据库中335150条记录,然后通过1个reducer fetch所有的记录做对比去重,耗时93.535秒。
该方法是通过分组方式获取唯一的组,应用在去重场景下需要将标识字段(order_id)作为分组的key,即group by order_id。
a.统计当天订单sql:
b.执行日志:
MapReduce Jobs Launched: Stage-Stage-1: Map: 97 Reduce: 1 Cumulative CPU: 400.63 sec HDFS Read: 24410031 HDFS Write: 789899
SUCCESS
Total MapReduce CPU Time Spent: 6 minutes 40 seconds 630 msec
OK
Time taken: 85.937 seconds, Fetched: 71809 row(s)
c.逻辑分析:该Hive sql作业时同样启动97个mapper拉取了数据库中335150条记录,然后通过1个reducer fetch所有的记录使用分组方式去重,共耗时85.937秒。
通过窗口函数方式对分组(分组原理同group by order_id)内的每条记录做排序(也可参考分组之外的字段做排序,如order by modify_time DESC,本作业中没有用到),当限制num=1时,则达到去重效果。
a.统计当天订单sql:
b.执行日志:
MapReduce Jobs Launched: Stage-Stage-1: Map: 97 Reduce: 1 Cumulative CPU: 458.32 sec HDFS Read: 24298434 HDFS Write: 789899
SUCCESS
Total MapReduce CPU Time Spent: 7 minutes 38 seconds 320 msec
OK
Time taken: 100.866 seconds, Fetched: 71809 row(s)
c.逻辑分析:该Hive sql作业时同样启动97个mapper拉取了数据库中335150条记录,然后通过1个reducer fetch所有的记录并对相同分组下的记录做编号,然后取出num=1的记录,共耗时100.866秒。
1.当数据量较小时,优先考虑使用distinct,可读性强,简洁高效;
2.当数据量较大时,推荐使用group by,性能可靠,结合mapper和reducer参数设置后性能优化更佳;
3.row_number() over()窗口函数本身是为分组内排序设计的,通过num=1限制后也可以用作数据去重。
大数据有道,为您提供通俗易懂的技能分享,让大数据更容易!
以上是关于Hive sql大数据有道之Hive sql去重的主要内容,如果未能解决你的问题,请参考以下文章